Java 版本WordCount
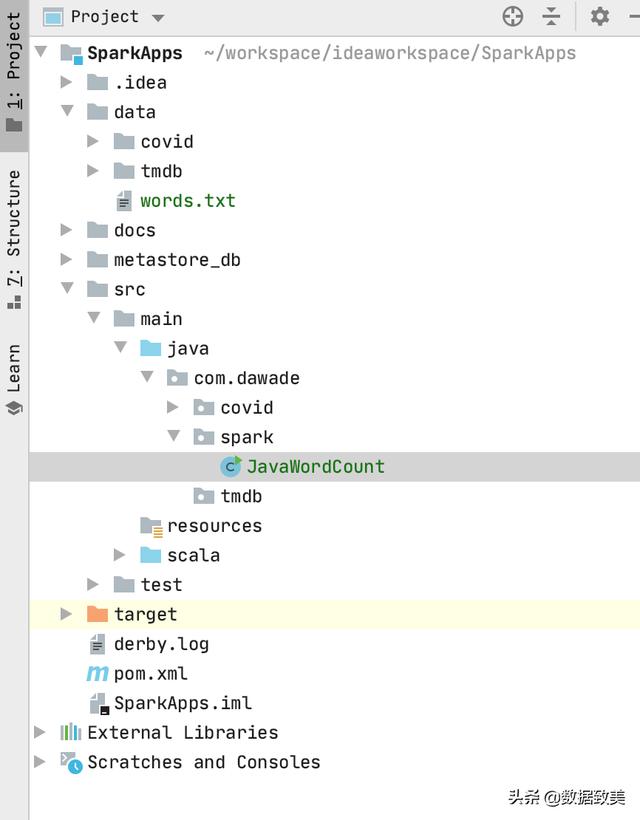
- 项目目录结构如下:
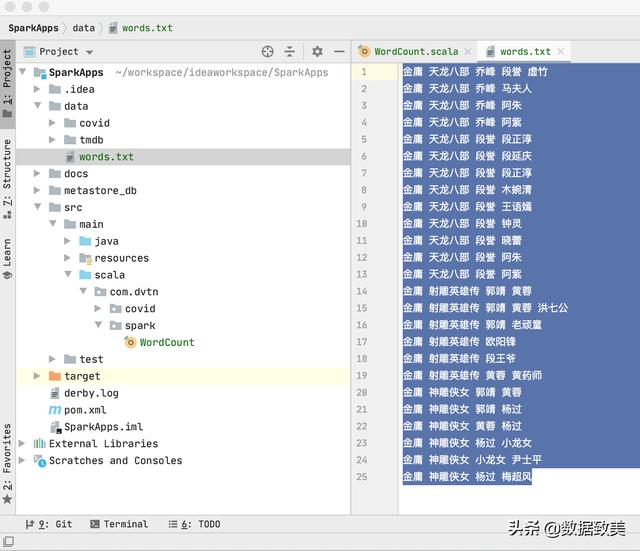
- 在项目目录data下创建要统计词频的文件words.txt
- 新建Java版的WordCount程序
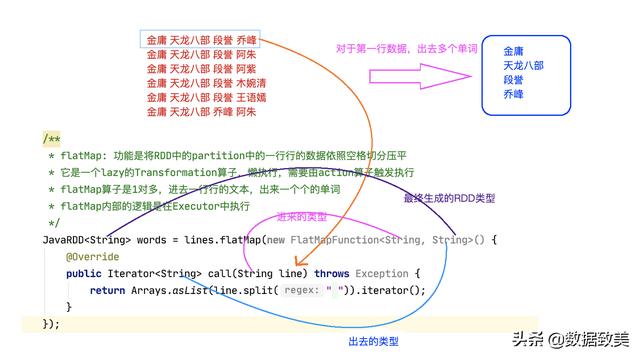
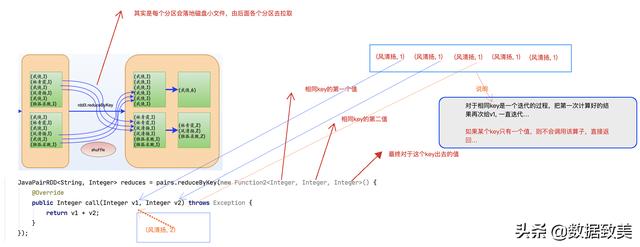
import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.FlatMapFunction;import org.apache.spark.api.java.function.Function2;import org.apache.spark.api.java.function.PairFunction;import org.apache.spark.api.java.function.VoidFunction;import scala.Tuple2;import java.util.Arrays;import java.util.Iterator;public class JavaWordCount { public static void main(String[] args) { /** * SparkConf创建Spark应用程序的配置 * * setAppName:用来设置应用程序的名称,如果些程序运行在Spark的集群上,可以在资源管理器的UI上看到,如standalone,yarn,mesos * * setMaster:用来设置应用程序的本地运行模式 * 1) local: Spark应用程序本地运行模式,如果local后不不指定参数,就默认使用一个core来运行Spark应用程序 * local[n]: 指定使用n个cores来运行Spark应用程序 * local[*]: 使用本地机器所有的cores来运行Spark应用程序 * 这里的core是对应计算机线程,假如你的计算机是4核8线程,那么你的计算机总共可以提供8个cores来运行Spark应用程序 * 如果不设置setMaster, 将来程序要打包发布到集群上了运行,集群主要有standalone, yarn, mesos * 2) standalone: Spark自带的资源管理器,主节点叫Master, 从节点叫Worker * 3) yarn: 基于Hadoop yarn资源管理器运行Spark程序,主节点叫ResourceManager, 从节点叫NodeManager * 4) mesos: 一般国外用的比较多,这里就不详细讲解 * */ SparkConf conf = new SparkConf().setMaster("local").setAppName("JavaWordCount"); /** * JavaSparkContext: 它是Spark应用程序通往集群的唯一通道, 创建了JavaSparkContext * JavaSparkContext底层默认会创建两个对象DAGScheduler和TaskScheduler * DAGScheduler: 依赖Spark应用程序中的RDD的宽窄依赖切割Job, 划分Stage, 每个Stage又会封装成TaskSet,提交给TaskScheduler * * TaskScheduler: 负责从TaskSet中遍历一个个的并行的Task, 发送给工作节点中的Executor中的ThreadPool执行,监控Task执行,回收结果。 */ JavaSparkContext jsc = new JavaSparkContext(conf); //设置log级别 jsc.setLogLevel("WARN"); /** * 通过调用Hadoop底层的读取文件的方法来切分文件,创建RDD, */ JavaRDD lines = jsc.textFile("./data/words.txt"); /** * flatMap: 功能是将RDD中的partition中的一行行的数据依照空格切分压平 * 它是一个lazy的Transformation算子,懒执行,需要由action算子触发执行 * flatMap算子是1对多,进去一行行的文本,出来一个个的单词 * flatMap内部的逻辑是在Executor中执行 */ JavaRDD words = lines.flatMap(new FlatMapFunction() { @Override public Iterator call(String line) throws Exception { return Arrays.asList(line.split(" ")).iterator(); } }); /** * mapToPair: 将一个个的单词的JavaRDD转换成格式的JavaPairRDD * 期中,K为单词, V为1 * * mapToPair与Scala中的map功能类似,是一个懒执行算子,一对一的操作,进去一个单词word, 出来一个键值对(word,1) */ JavaPairRDD pairs = words.mapToPair(new PairFunction() { @Override public Tuple2 call(String word) throws Exception { return new Tuple2<>(word, 1); } }); /** * reduceByKey: 对上步RDD的partition中的K,V格式的RDD先分组再聚合, 是懒执行算子 * * reduceByKey是一个shuffle类的算子,如果数据分布在多台节点上,会进行局部分组聚合,再全局聚合, 对于跨节点的数据会落地磁盘小文件 * 基处理也要经过mapper和reducer两个阶段 * * 假如数据有两个分区,分别在node1节点和node2节点上,那么: * * ===================>mapper=========================>shuffle=================>reducer========================= * node1节点: * (金庸,1) * (金庸,1) * (金庸,1) * (金庸,1) 局部分组聚合=> (金庸,4) => 写入磁盘落地 (金庸,6) * (天龙八部,1) (天龙八部,4) * (天龙八部,1) * (天龙八部,1) * (天龙八部,1) => 全局聚合 * node2节点: (天龙八部,6) * (金庸,1) (段誉,2) * (金庸,1) * (天龙八部,1) 局部分组聚合=> (金庸,2) => 写入磁盘落地 * (天龙八部,1) (天龙八部,2) * (段誉,1) (段誉,2) * (段誉,1) * */ JavaPairRDD reduces = pairs.reduceByKey(new Function2() { @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); /** * 由于Spark JAVA的API中没有提供sortBy()方法,只提供了sortByKey(), 所以要进行排序,需要经历以下步骤: * * 1. 调用mapToPair, 把原来的RDD从格式转换成 * 2. 调用sortByKey() * 3. 排好序后,再换回原来K,V */ JavaPairRDD swaps = reduces.mapToPair(new PairFunction, Integer, String>() { @Override public Tuple2 call(Tuple2 tuple) throws Exception { return tuple.swap(); } }); JavaPairRDD sorted = swaps.sortByKey(false); JavaPairRDD results = sorted.mapToPair(new PairFunction, String, Integer>() { @Override public Tuple2 call(Tuple2 tuple) throws Exception { return tuple.swap(); } }); /** * foreach: 是一个action算子,触发执行 * * Spark应用程序中有几个action算子就有几个job */ results.foreach(new VoidFunction>() { @Override public void call(Tuple2 tuple) throws Exception { System.out.println("单词:"+tuple._1+" 个数:"+tuple._2); } }); //释放资源 jsc.stop(); }}
- 关键代码说明






















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









