









 本文详细介绍如何使用IntelliJ IDEA和Maven搭建Spark开发环境,并通过Scala与Java实现WordCount程序,涵盖从环境配置到程序部署的全过程。
本文详细介绍如何使用IntelliJ IDEA和Maven搭建Spark开发环境,并通过Scala与Java实现WordCount程序,涵盖从环境配置到程序部署的全过程。
基于Intellij IDEA搭建Spark开发环境搭建
基于Intellij IDEA搭建Spark开发环境搭——参考文档
● 参考文档http://spark.apache.org/docs/latest/programming-guide.html
● 操作步骤
·a)创建maven 项目
·b)引入依赖(Spark 依赖、打包插件等等)
基于Intellij IDEA搭建Spark开发环境—maven vs sbt
● 哪个熟悉用哪个
● Maven也可以构建scala项目
基于Intellij IDEA搭建Spark开发环境搭—maven构建scala项目
● 参考文档http://docs.scala-lang.org/tutorials/scala-with-maven.html
● 操作步骤
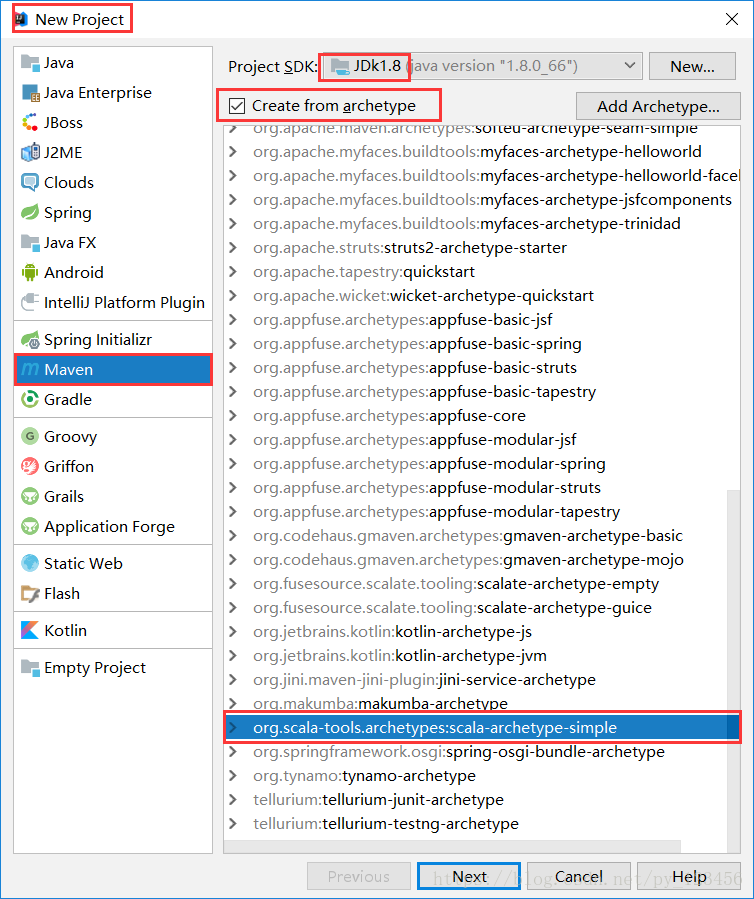
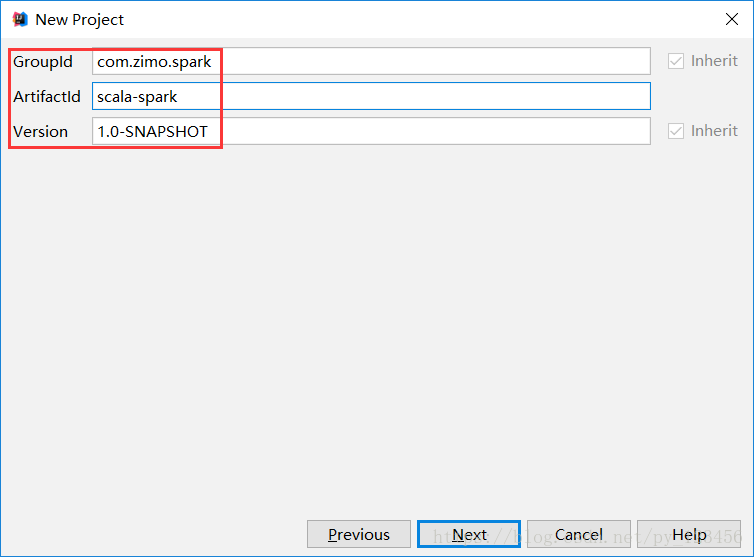
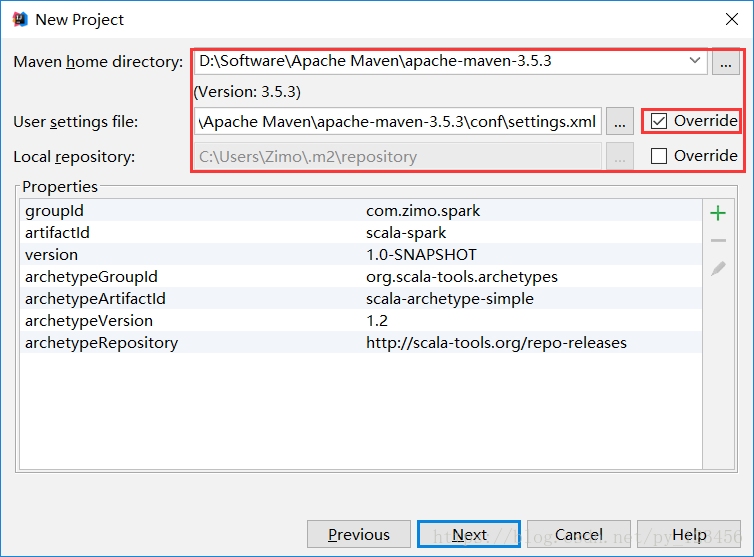
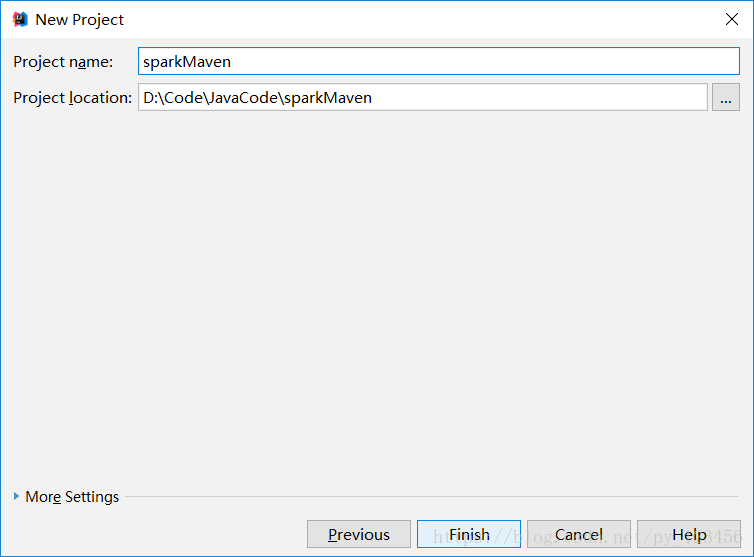
a)用maven构建scala项目(基于net.alchim31.maven:scala-archetype-simple)
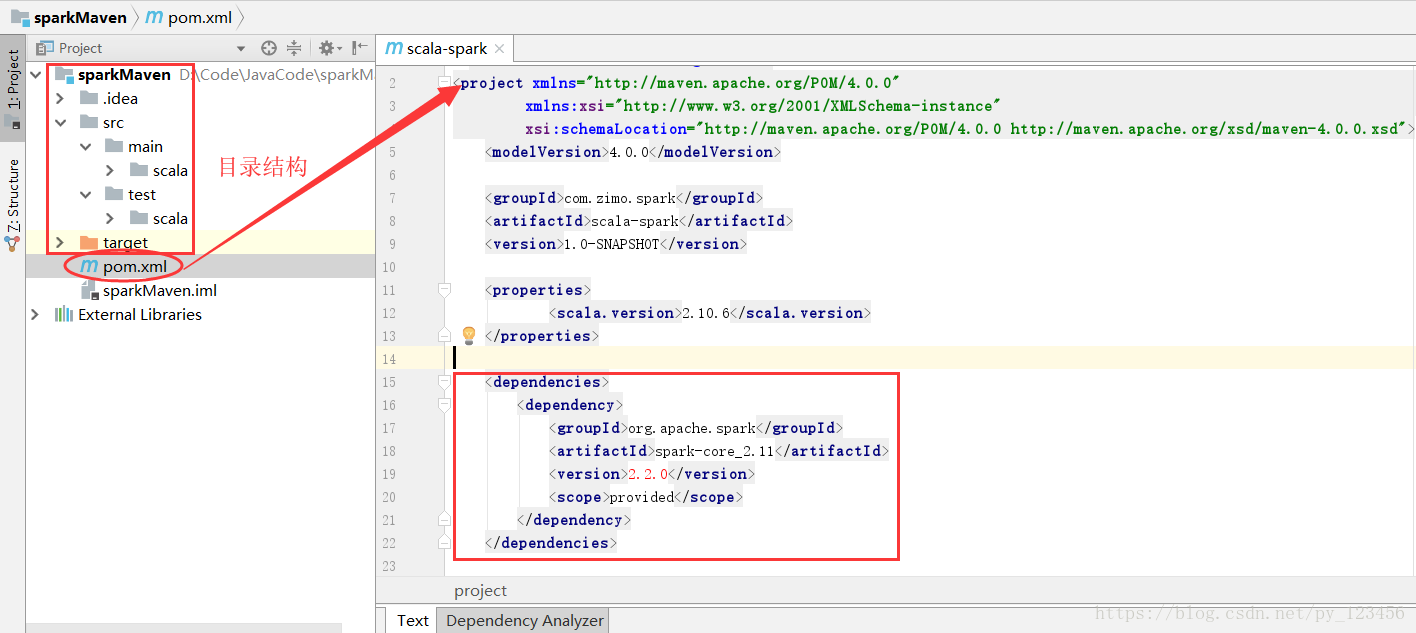
b)pom.xml引入依赖(spark依赖、打包插件等等)
在pom.xml文件中的合适位置添加以下内容:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
<scope>provided</scope> //设置作用域,不将所有依赖文件打包到最终的项目中
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"></transformer>
</transformers>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build> 进行一次打包操作以测试是否工作正常。
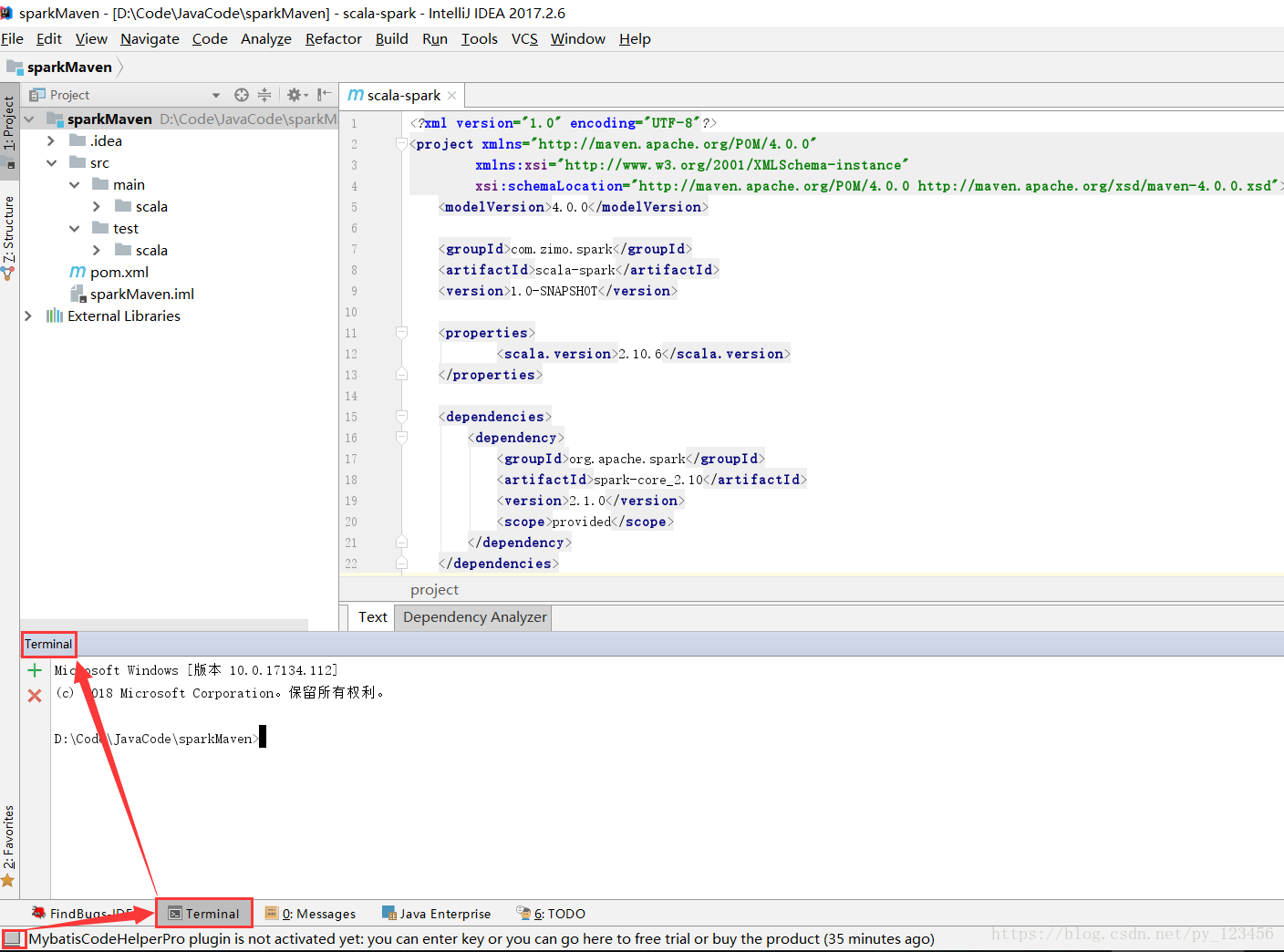
在Terminal中输入指令进行打包操作。
mvn clean package
运行结果如下:
D:\Code\JavaCode\sparkMaven>mvn clean package
[INFO] Scanning for projects...
[INFO]
[INFO] ---------------------< com.zimo.spark:scala-spark >---------------------
[INFO] Building scala-spark 1.0-SNAPSHOT
[INFO] --------------------------------[ jar ]---------------------------------
[INFO]
[INFO] --- maven-clean-plugin:2.5:clean (default-clean) @ scala-spark ---
[INFO]
[INFO] --- maven-resources-plugin:2.6:resources (default-resources) @ scala-spark ---
[WARNING] Using platform encoding (GBK actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] skip non existing resourceDirectory D:\Code\JavaCode\sparkMaven\src\main\resources
[INFO]
[INFO] --- maven-compiler-plugin:3.1:compile (default-compile) @ scala-spark ---
[INFO] No sources to compile
[INFO]
[INFO] --- maven-resources-plugin:2.6:testResources (default-testResources) @ scala-spark ---
[WARNING] Using platform encoding (GBK actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] skip non existing resourceDirectory D:\Code\JavaCode\sparkMaven\src\test\resources
[INFO]
[INFO] --- maven-compiler-plugin:3.1:testCompile (default-testCompile) @ scala-spark ---
[INFO] No sources to compile
[INFO]
[INFO] --- maven-surefire-plugin:2.12.4:test (default-test) @ scala-spark ---
[INFO] No tests to run.
[INFO]
[INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ scala-spark ---
[WARNING] JAR will be empty - no content was marked for inclusion!
[INFO] Building jar: D:\Code\JavaCode\sparkMaven\target\scala-spark-1.0-SNAPSHOT.jar
[INFO]
[INFO] --- maven-shade-plugin:2.4.1:shade (default) @ scala-spark ---
[INFO] Replacing original artifact with shaded artifact.
[INFO] Replacing D:\Code\JavaCode\sparkMaven\target\scala-spark-1.0-SNAPSHOT.jar with D:\Code\JavaCode\sparkMaven\target\scala-spark-1.0-SNAPSHOT-shaded.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 9.675 s
[INFO] Finished at: 2018-09-11T15:33:53+08:00
[INFO] ------------------------------------------------------------------------出现了BUILD SUCCESS,表明一切正常。下面给大家演示以下Scala编程的大致流程,以及在该框架下同样用Java进行实现应该如何操作。
Scala编程实现WordCount
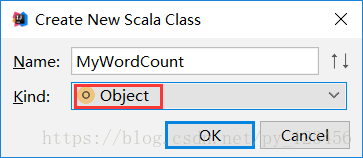
注意:此处必须选为Object,否则没有main方法!
然后输入以下代码,然后执行打包操作
def main(args: Array[String]): Unit = {
println("hello spark")
}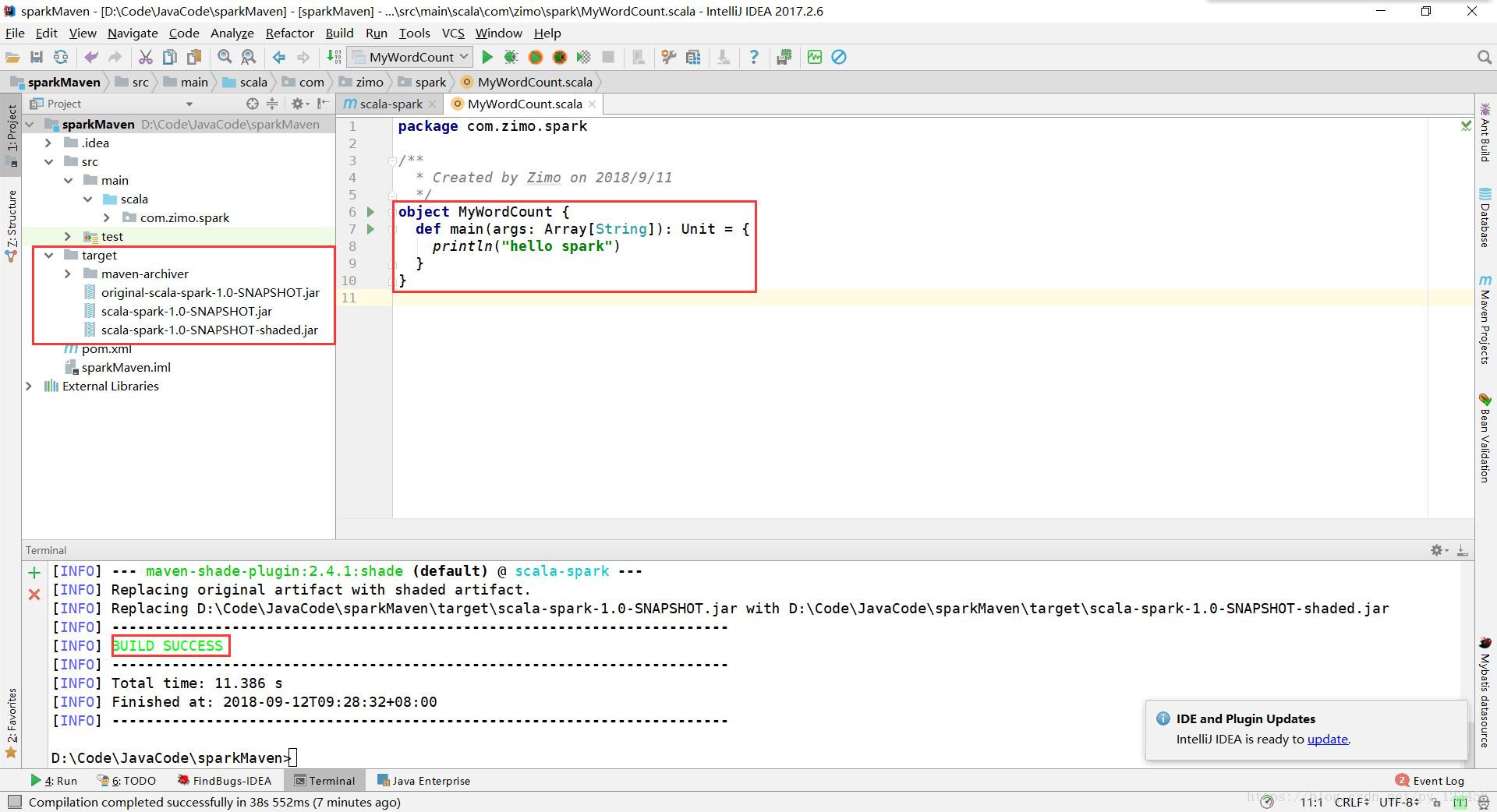
完成后可以看到项目目录下多出来了一个target目录。这就是使用Scala编程的一个大致流程,下面我们来写一个WordCount程序。(后面也会有Java编程的版本提供给大家)
首先在集群中创建以下目录和测试文件:
[hadoop@masternode ~]$ cd /home/hadoop/
[hadoop@masternode ~]$ ll
total 68
drwxr-xr-x. 9 hadoop hadoop 4096 Sep 10 22:15 app
drwxrwxr-x. 6 hadoop hadoop 4096 Aug 17 10:42 data
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Desktop
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Documents
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Downloads
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Music
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Pictures
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Public
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Templates
drwxrwxr-x. 3 hadoop hadoop 4096 Apr 18 10:11 tools
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Videos
-rw-rw-r--. 1 hadoop hadoop 20876 Apr 20 18:03 zookeeper.out
[hadoop@masternode ~]$ mkdir testSpark/
[hadoop@masternode ~]$ ll
total 72
drwxr-xr-x. 9 hadoop hadoop 4096 Sep 10 22:15 app
drwxrwxr-x. 6 hadoop hadoop 4096 Aug 17 10:42 data
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Desktop
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Documents
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Downloads
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Music
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Pictures
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Public
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Templates
drwxrwxr-x. 2 hadoop hadoop 4096 Sep 12 10:23 testSpark
drwxrwxr-x. 3 hadoop hadoop 4096 Apr 18 10:11 tools
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 17 10:03 Videos
-rw-rw-r--. 1 hadoop hadoop 20876 Apr 20 18:03 zookeeper.out
[hadoop@masternode ~]$ cd testSpark/
[hadoop@masternode testSpark]$ vi word.txt
apache hadoop spark scala
apache hadoop spark scala
apache hadoop spark scala
apache hadoop spark scalaWordCount.scala代码如下:(如果右键New下面没有“Scala Class“”选项,请检查IDEA是否添加了scala插件)
package com.zimo.spark
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Zimo on 2018/9/11
*/
object MyWordCount {
def main(args: Array[String]): Unit = {
//参数检查
if (args.length < 2) {
System.err.println("Usage: myWordCount <input> <output>")
System.exit(1)
}
//获取参数
val input = args(0)
val output = args(1)
//创建Scala版本的SparkContext
val conf = new SparkConf().setAppName("myWordCount")
val sc = new SparkContext(conf)
//读取数据
val lines = sc.textFile(input)
//进行相关计算
lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
//保存结果
sc.stop()
}
}从代码可以看出scala的优势就是简洁,但是可读性较差。所以,学习可以与后面的java代码进行对比。
然后打包
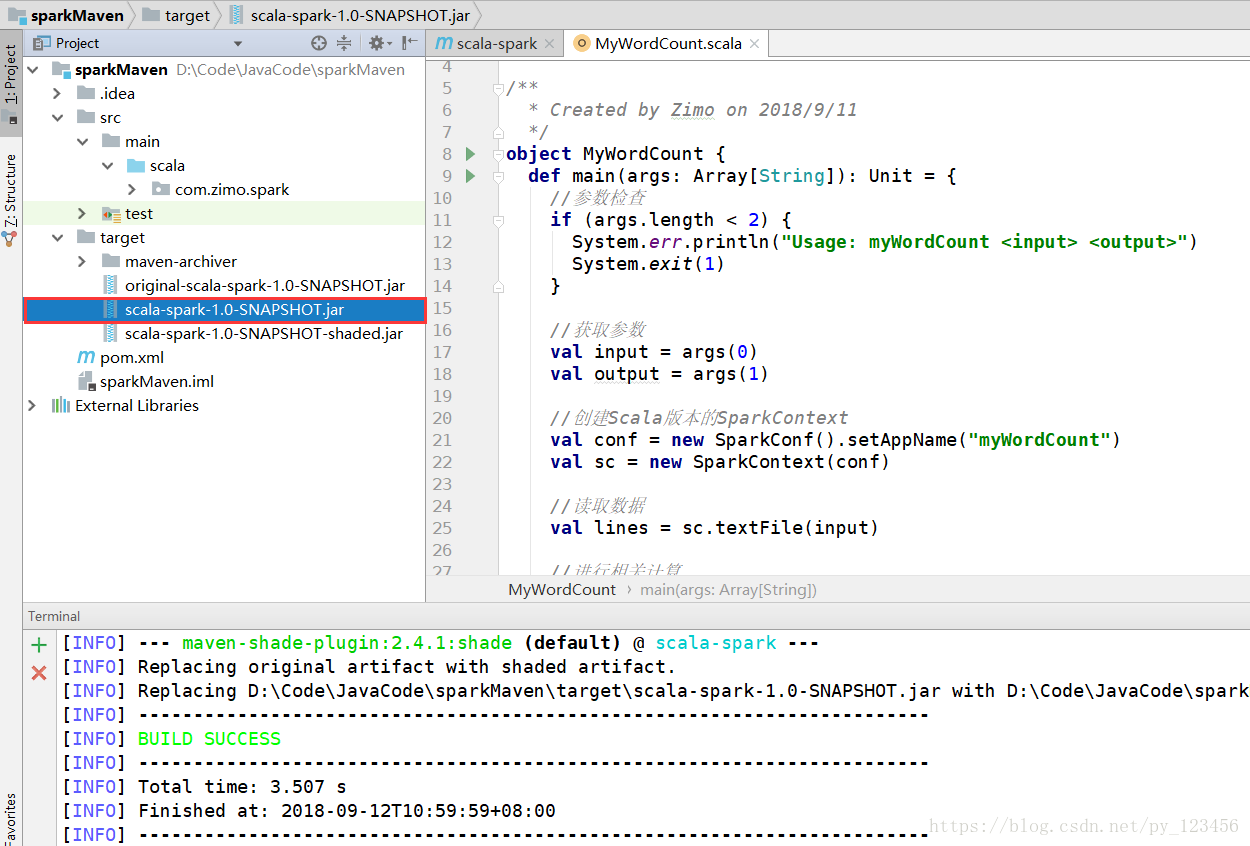
打包完成后把上图中的文件上传到spark集群上去,然后执行。
[hadoop@masternode testSpark]$ rz
[hadoop@masternode testSpark]$ ll
total 8
-rw-r--r--. 1 hadoop hadoop 1936 Sep 12 10:59 scala-spark-1.0-SNAPSHOT.jar
-rw-rw-r--. 1 hadoop hadoop 104 Sep 12 10:26 word.txt
[hadoop@masternode testSpark]$ cd ../app/spark-2.2.0/
[hadoop@masternode spark-2.2.0]$ cd bin/
[hadoop@masternode bin]$ ll
total 92
-rwxr-xr-x. 1 hadoop hadoop 1089 Jul 1 2017 beeline
-rw-r--r--. 1 hadoop hadoop 899 Jul 1 2017 beeline.cmd
-rwxr-xr-x. 1 hadoop hadoop 1933 Jul 1 2017 find-spark-home
-rw-r--r--. 1 hadoop hadoop 1909 Jul 1 2017 load-spark-env.cmd
-rw-r--r--. 1 hadoop hadoop 2133 Jul 1 2017 load-spark-env.sh
-rwxr-xr-x. 1 hadoop hadoop 2989 Jul 1 2017 pyspark
-rw-r--r--. 1 hadoop hadoop 1493 Jul 1 2017 pyspark2.cmd
-rw-r--r--. 1 hadoop hadoop 1002 Jul 1 2017 pyspark.cmd
-rwxr-xr-x. 1 hadoop hadoop 1030 Jul 1 2017 run-example
-rw-r--r--. 1 hadoop hadoop 988 Jul 1 2017 run-example.cmd
-rwxr-xr-x. 1 hadoop hadoop 3196 Jul 1 2017 spark-class
-rw-r--r--. 1 hadoop hadoop 2467 Jul 1 2017 spark-class2.cmd
-rw-r--r--. 1 hadoop hadoop 1012 Jul 1 2017 spark-class.cmd
-rwxr-xr-x. 1 hadoop hadoop 1039 Jul 1 2017 sparkR
-rw-r--r--. 1 hadoop hadoop 1014 Jul 1 2017 sparkR2.cmd
-rw-r--r--. 1 hadoop hadoop 1000 Jul 1 2017 sparkR.cmd
-rwxr-xr-x. 1 hadoop hadoop 3017 Jul 1 2017 spark-shell
-rw-r--r--. 1 hadoop hadoop 1530 Jul 1 2017 spark-shell2.cmd
-rw-r--r--. 1 hadoop hadoop 1010 Jul 1 2017 spark-shell.cmd
-rwxr-xr-x. 1 hadoop hadoop 1065 Jul 1 2017 spark-sql
-rwxr-xr-x. 1 hadoop hadoop 1040 Jul 1 2017 spark-submit
-rw-r--r--. 1 hadoop hadoop 1128 Jul 1 2017 spark-submit2.cmd
-rw-r--r--. 1 hadoop hadoop 1012 Jul 1 2017 spark-submit.cmd
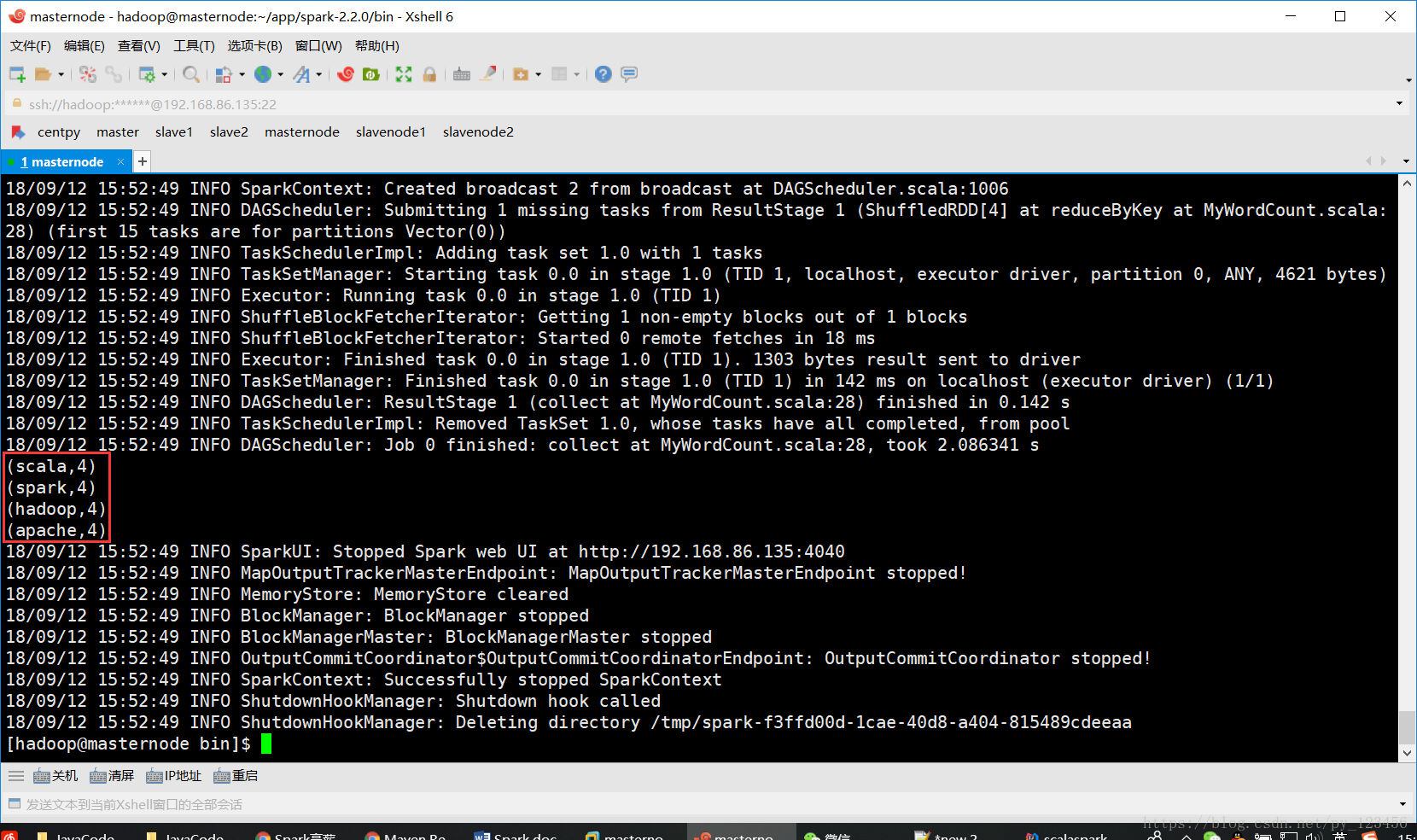
[hadoop@masternode testSpark]$ ./spark-submit --class com.zimo.spark.MyWordCount ~/testSpark/scala-spark-1.0-SNAPSHOT.jar ~/testSpark/word.txt ~/testSpark/ 运行结果如下图所示:
以上操作是把结果直接打印出来,下面我们尝试一下将结果保存到文本当中去。修改以下代码:
//进行相关计算
//lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
val resultRDD = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//保存结果
resultRDD.saveAsTextFile(output)再次执行:
./spark-submit --class com.zimo.spark.MyWordCount ~/testSpark/scala-spark-1.0-SNAPSHOT.jar ~/testSpark/word.txt ~/testSpark/result
//输出目录一定要为不存在的目录!结果如下:
[hadoop@masternode testSpark]$ ll
total 5460
drwxrwxr-x. 2 hadoop hadoop 4096 Sep 12 16:02 result
-rw-r--r--. 1 hadoop hadoop 5582827 Sep 12 16:00 scala-spark-1.0-SNAPSHOT.jar
-rw-rw-r--. 1 hadoop hadoop 104 Sep 12 15:52 word.txt
[hadoop@masternode testSpark]$ cd result/
[hadoop@masternode result]$ ll
total 4
-rw-r--r--. 1 hadoop hadoop 42 Sep 12 16:02 part-00000
-rw-r--r--. 1 hadoop hadoop 0 Sep 12 16:02 _SUCCESS
[hadoop@masternode result]$ cat part-00000
(scala,4)
(spark,4)
(hadoop,4)
(apache,4)
**
Java编程实现WordCount
**
在同样目录新建一个java目录,并设置为”Sources Root”。
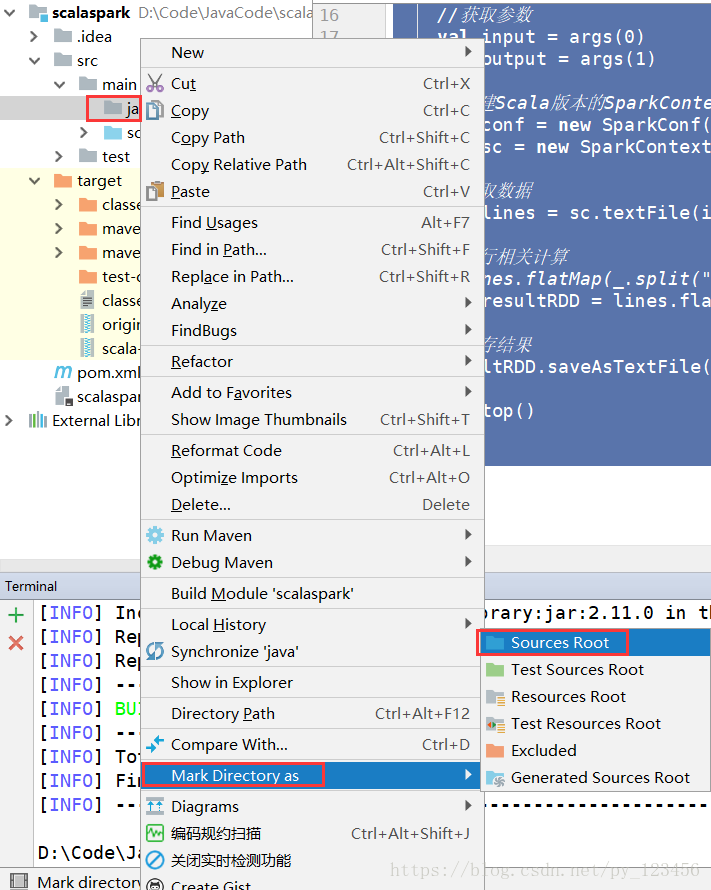
单元测试目录”test”同样需要建一个java文件夹。
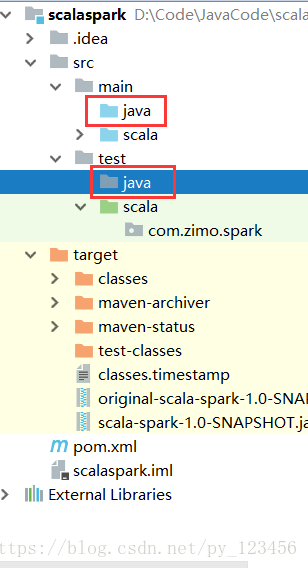
同理设置为”Test Sources Root”。然后分别再创建resources目录(用于存放配置文件),并分别设置为“Resources Root”和“Test Resources Root”。
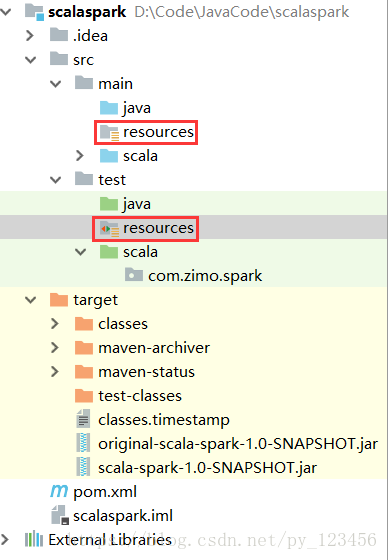
最后,创建一个“com.zimo.spark”包,并在下面新建一个MyJavaWordCount.Class类(如果右键New下面没有“Java Class”选项请参看博文https://blog.csdn.net/py_123456/article/details/82628612下的详细讲解),其中的代码为如下:
package com.zimo.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* Created by Zimo on 2018/9/12
*/
public class MyJavaWordCount {
public static void main(String[] args) {
//参数检查
if (args.length < 2) {
System.err.println("Usage: MyJavaWordCount <input> <output>");
System.exit(1);
}
//获取参数
String input = args[0];
String output = args[1];
//创建Java版本的SparkContext
SparkConf conf = new SparkConf().setAppName("MyJavaWordCount");
JavaSparkContext sc = new JavaSparkContext(conf);
//读取数据
JavaRDD<String> inputRDD = sc.textFile(input);
//进行相关计算
JavaRDD<String> words = inputRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
JavaPairRDD<String, Integer> result = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer x, Integer y) throws Exception {
return x+y;
}
});
//保存结果
result.saveAsTextFile(output);
//关闭sc
sc.stop();
}
}注意:此处要做一点点修改。注释掉pom.xml文件下的此处内容

此处是默认Source ROOT的路径,所以打包时就只能打包Scala下的代码,而我们新建的Java目录则不会被打包,注释之后则会以我们之前的目录配置为主。
然后就可以执行打包和集群上的运行操作了。运行和Scala编程一模一样,我在这里就不赘述了,大家参见上面即可!只是需要注意一点:output目录必须为不存在的目录,请记得每次运行前进行修改!

















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









