





本期AI论道想跟大家分享一些关于BERT的模型压缩技术。
众所周知,大规模的预训练语言模型已经成为各种自然语言处理任务(NLP)的新驱动力,例如BERT在对下游任务进行微调后,显著提高了模型的表现。尽管这些模型在各种NLP任务上获得了最先进的结果,但是通常内存占用和功耗过高,以此带来很高的延迟,包括训练阶段和推断阶段。这反过来又限制了这些模型在移动和物联网等嵌入式设备上的部署。模型压缩旨在解决这类问题。但需注意的是在对原有模型使用模型压缩技术的同时,大多情况下会不可避免的对模型表现造成影响,这时需要对参数效率与模型表现之间做出权衡。
我们按照应用于BERT的主要的三种模型压缩技术类别,即低秩因式分解、量化和知识蒸馏,对该研究领域的进展进行简明扼要的介绍。
1.低秩因式分解
该方法基本思想是将原始的大矩阵分解为两个或多个低秩矩阵的乘积。就模型压缩技术而言主要用于全连接层和卷积层。更详细的说明,权重矩阵被分解为用两个矩阵的乘积来表示,其中, 当时,可以减少参数数量。在众多使用模型压缩技术的Bert变体中用到低秩因式分解技术的代表为ALBERT,接下来我们来简明介绍。
ALBERT: A Lite Bert for self-supervisedLearning of Language Representations
论文地址: https://openreview.net/forum?id=H1eA7AEtvS
代码地址: https://github.com/google-research/ALBERT
该论文已被 ICLR 2020 spotlight presentation收录。
ALBERT 结合了两种模型压缩的技术:
第一种是低秩因式分解:在Bert中,词嵌入大小和隐藏层大小是恒等的,但是ALBERT中分析这种决定是次优的。可将输入层和输出层的权重矩阵分解为两个更小的参数矩阵。这也可以理解为在输入层和输出层使用嵌入大小远小于原生Bert的嵌入大小,再使用简单的映射矩阵使得输入层的输出或者最后一层隐藏层的输出可以通过映射矩阵输入到第一层的隐藏层或者输出层。这种举措将词嵌入的大小和隐藏层大小分开,带来的好处是可以使得在不显著增加词嵌入大小的情况下能够更容易增加隐藏层大小。
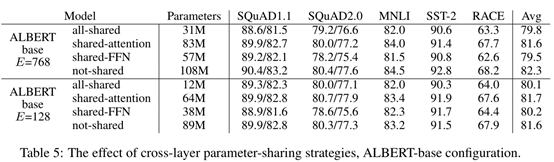
从嵌入层因式分解的消融分析实验结果来看,该方法能在稍微降低模型表现的情况下能一定程度的降低模型的参数量,这也是由于Bert的参数量大部分集中于模型的隐藏层架构上,在嵌入层中只有30,000词块,其所占据的参数量只占据整个模型参数量的小部分。
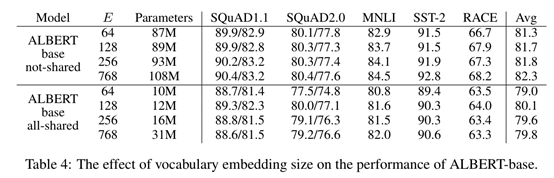
第二种是跨层参数共享:即隐藏层中的每一层都使用相同的参数,这可由多种方式共享参数,例如只共享每层的前馈网络参数或者只共享每层的注意力子层参数。默认情况是共享每层的所有参数。这种策略可以防止参数随着网络深度的增加而增大。
观察到跨层参数共享的消融分析实验结果,该方法能大幅降低模型参数量,但比较于基准模型,其表现略微降低。
除了上述两种方法用于模型压缩,该工作提出句子顺序预测损失(SOP)代替Bert中的下一句预测损失(NSP),即由预测两个句子是否连续出现在原文中替换为两个连续的句子是正序或是逆序,用于进一步提高下游任务的表现。
从整体实验结果观察到比BERT-large具有更少参数量的ALBERT-xxlarge的模型表现更优,取得NLP多项任务的最优结果,其训练速度也有所提升。
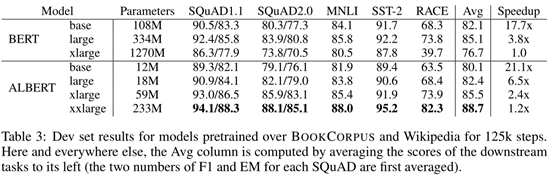
最后,值得注意的是ALBERT在参数效率上获得了令人满意的结果,但是其加速指标仅展示了训练过程,由于ALBERT的隐藏层架构采用跨层参数共享策略并未减少训练过程的计算量,加速效果更多来源于低维的嵌入层。
2.量化
量化技术通过减少用于表示每个权重值的精度来压缩模型。例如模型使用float32标准定义参数的精度进行训练,然后我们可以使用量化技术选择float16,甚至int8表示参数的精度用于压缩模型。
在众多使用模型压缩技术的Bert变体中用到量化技术的有Q8BERT [1]和Q-BERT,接下来我们简要地介绍下Q-BERT。
Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
论文地址: http://arxiv.org/abs/1909.05840
该论文已被AAAI 2020收录。
Q-BERT提出两种量化方法:
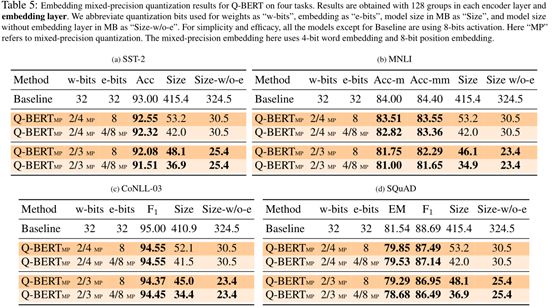
第一种是混合精确量化:由于不同的编码器层负责不同的语义表示,预计他们表现出不同的灵敏度。因此该工作为更敏感的层分配更高的精度以保证模型表现。通过海森关注量化(HAWQ)计算每一层参数的海森频谱(例如特征值),具有更高海森频谱的网络层是对量化更敏感的,需要更高的精度。详细地,在执行海森关注量化时对于不同的训练数据获得每一层的平均最大特征值和其方差作为指标来决定每一层的量化精度。然后根据所选的精度设置执行量化包括每一层的参数和激活函数,并微调模型。
观察到下图的混合精确量化方法的消融分析实验结果,该方法能大幅降低模型参数量,并且比较于基准模型,其表现仅略微降低。
第二种是分组量化:在编码器层中的每一个自注意力头有四个参数矩阵,即和输出权重矩阵。将此四个矩阵作为一个具有相同量化范围的整体直接量化会显著降低模型准确性。该工作将每个自注意力头对应的四个权重矩阵作为一个组,所以有12个组(12个自注意力头)。此外,在每一组中,将顺序的输出神经元分组,比如每一自注意力子层有4*12*64=3072个神经元,其中64为输出神经元,每6个输出神经元为一个子组,所以总共有12×64/6= 128个子组,每个子组可以有自己的量化范围。分层量化以及分组量化可由下图阐述。
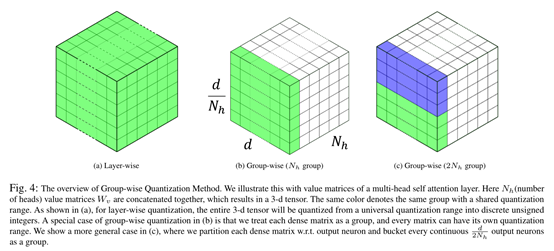
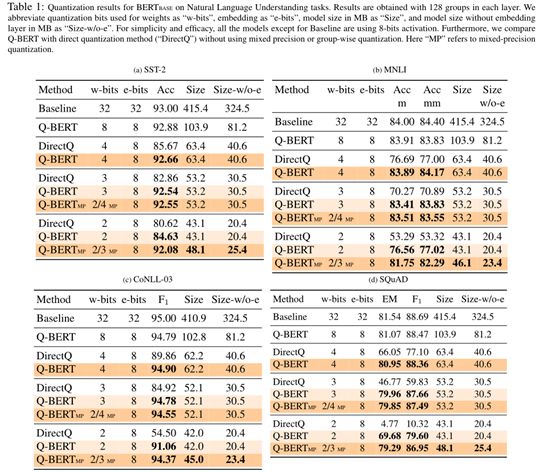
从下表的整体实验结果观察到Q-BERT取得明显的压缩率,而在模型表现上的损失在可接受范围之内。即使在低至2位的超低精度量化情况下,相应的模型取得最高13倍的压缩率,同时可以达到与基准相当的性能。
最后,值得注意的是该工作需要一定的硬件实现,虽然文章中已经采取一系列方法缓解了这一缺点,但是简单的硬件实现不可避免。最近PyTorch 1.3宣布通过使用熟悉的eager模式Python API支持8位模型量化。当前的实验特性包括对训练后量化、动态量化和量化感知训练的支持。有兴趣的可前去尝试(https://pytorch.org/blog/pytorch-1-dot-3-adds-mobile-privacy-quantization-and-named-tensors/)。
3.知识蒸馏
基于知识蒸馏的模型压缩的基本思想是将知识从大型的,经过预训练的教师模型转移到通常较小的学生模型中,常见的学生模型根据教师模型的输出以及分类标签进行训练。
在使用模型压缩技术的Bert变体中以知识蒸馏为主要技术的论文众多,例如DistilBERT [2]、TinyBERT [3]、MobileBERT [4]以及[5-6],我们在这里介绍一篇比较具有代表性的。
Extreme Language Model Compression withOptimal Subwords and Shared Projections
论文地址: https://openreview.net/forum?id=S1x6ueSKPr
该工作基于知识蒸馏技术将知识从大型的教师模型迁移到小型的学生模型,与传统的知识蒸馏压缩模型不同的是,主要从减少学生模型的词汇表中词块的数量和隐藏层大小两个方面达到模型压缩的效果。
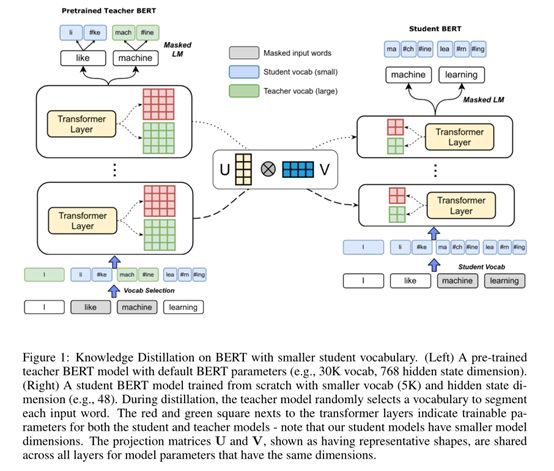
1. 为使得学生模型在蒸馏的过程中学习到一个更小的词汇表,该工作使用对偶训练:在蒸馏过程中,对于给定的输入到教师模型的训练序列,该工作混合使用教师词汇表和学生词汇表。通过从序列中随机选择部分单词,使用学生词汇表来分割,对于其它单词使用教师词汇表来分割,这鼓励根据老师和学生的词汇表来对齐同一单词的表示形式。这也是通过掩码语言建模任务来实现的该策略的效果。需要注意的是我们仅对教师模型执行对偶训练。在使用掩码语言建模训练时,模型针对老师和学生的词汇表使用不同的softmax层,具体取决于需预测的单词使用了哪一个词汇表来分割。
2. 为减少隐藏层大小,同时尽量不损害模型性能,仅仅依靠教师模型的输出去训练学生模型并不具备高泛化能力,该工作使用共享映射:将教师模型和隐藏层大小较小的学生模型的参数投影到相同的空间再最小化两者的信息损失。详细地,该工作将教师模型的每一层中的每个可训练变量投影为与学生模型中相应变量相同的形状,记为向下映射,并计算2-范式损失,相似地,将学生模型的每一层中的每个可训练变量投影为与教师模型中相应变量相同的形状,记为向上映射,并计算2-范式损失,最后将损失相加作为目标函数的一部分,另外一部分为掩码语言建模预测损失。
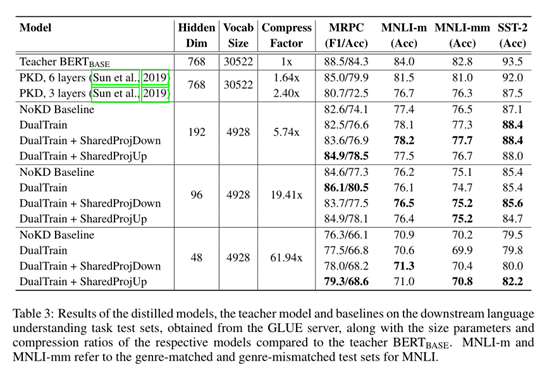
从下图的蒸馏模型的实验结果看该工作取得惊人的参数效率,最高可超60倍的压缩率,该模型的内存占有低于7MB,但是其模型表现也相应的明显下降。
总结:
上述的各项对BERT进行模型压缩的工作都在该领域取得一定的进展,例如参数效率都取得很好的成果,但每一项工作还是有的各种限制,例如训练与推断速度在多种场景下也是极其重要的,所幸的是,以上所介绍的方法并不完全互相冲突,在工业界应用中尝试将多种方法协同使用也是不错的选择。除此之外,上述工作的共有限制是由经验老道的作者针对BERT模型的各项缺点进行定向分析来提出模型压缩的办法,即以手动的启发式或者规则的方法,这种方式往往是次优的。那么能不能由机器去自动学习如何压缩和加速模型,这可以从AutoML [7]等领域研究,我们期待并努力着。
References.
[1] Zafrir O, Boudoukh G, Izsak P, et al.Q8bert: Quantized 8bit bert[J]. arXiv preprint arXiv:1910.06188, 2019.
[2] Sanh V, Debut L, Chaumond J, et al.DistilBERT, a distilled version of BERT: smaller, faster, cheaper andlighter[J]. arXiv preprint arXiv:1910.01108, 2019.
[3] Jiao X, Yin Y, Shang L, et al.Tinybert: Distilling bert for natural language understanding[J]. arXiv preprintarXiv:1909.10351, 2019.
[4] Sun Z, Yu H, Song X, et al. MOBILEBERT:TASK-AGNOSTIC COMPRESSION OF BERT FOR RESOURCE LIMITED DEVICES[J].
[5] Mukherjee S, Awadallah A H. DistillingTransformers into Simple Neural Networks with Unlabeled Transfer Data[J]. arXivpreprint arXiv:1910.01769, 2019.
[6] Sun S, Cheng Y, Gan Z, et al. Patient knowledge distillation for bert model compression[J]. arXiv preprint arXiv:1908.09355,2019.
[7] He Y, Lin J, Liu Z, et al. Amc: Automlfor model compression and acceleration on mobile devices[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 784-800.
中国科学院深圳先进技术研究院自然语言处理组正在招收实习/硕士/博士同学,对NLP感兴趣的同学欢迎发送简历至min.yang@siat.ac.cn!
We (NLP team at SIAT, Chinese Academy of Sciences) are hiring a few intern/master/PhD students. Send a resume to min.yang@siat.ac.cn if interested.















 434
434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









