






PS: 每篇文章力求 短小而精悍,简单易懂,每天Look一眼,增长技术实力,欢迎指导关注。
面试官:
知道HashMap吗 描述一下底层原理
回 答:
先简单描述一下: HashMap 是基于key-value的方式存储,允许key和value为null。他是非同步的,线程不安全。存储数据速度快,效率高。 底层是基于数组和链表的实现方式。
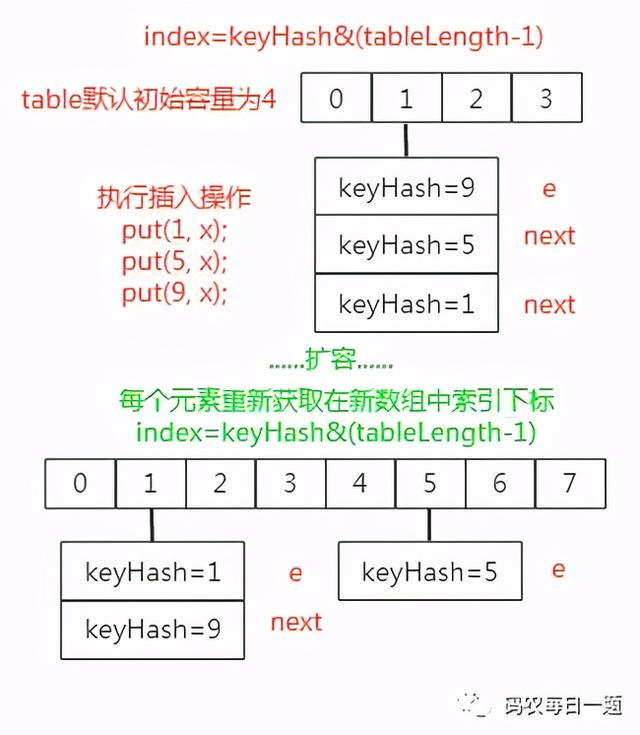
HashMap 存储数据是使用put方法,先根据key元素的hashcode 值去得到Entry元素在数组中的位置(下标),然后把Entry元素放到对应的位置上面。如果这个 Entry 元素所在的位子上已经存放有其他元素就在同一个位子上的 Entry 元素以链表的形式存放,新加入的放在链头。从 HashMap 中 get Entry 元素时先计算 key 的 hashcode,找到数组中对应位置的某一 Entry 元素,然后通过 key 的 equals 方法在对应位置的链表中找到需要的 Entry 元素,所以 HashMap 的数据结构是数组和链表的结合,此外 HashMap 中 key 和 value 都允许为 null,key 为 null 的键值对永远都放在以 table[0] 为头结点的链表中。
HashMap 采用的是链表的数组实现方式,这里唠一唠,数组对于数据的查询很快插入和删除比较慢,而链表存储区间离散,占用内存比较宽松,故空间复杂度小,但时间复杂度大(O(N)),查询比较慢,但是删除和插入比较快,他俩组合到一起所以就形成了哈希表的东西。
但是 JDK 1.8 开始 HashMap 实现原理变成了数组+链表+红黑树的结构。数组链表部分基本不变,红黑树是为了解决哈希碰撞后链表索引效率的问题。JDK 1.8 中当链表的节点大于 8 个时就会将链表变为红黑树。
面试官:
HashMap知道初始容量是多少吗?他是怎么扩容的?
回 答:
JDK中的HashMap的初始容量是16,而安卓中的HashMap初始容量是4,并且默认的扩容因子都是2的幂次方。
如下源码可以参考计算方法:

put元素方法里面扩容计算
获取数组索引的计算方式为 key 的 hash 值按位与运算数组长度减一,必须是2的幂次方。即使负载因子和 hash 算法设计的再合理也免不了哈希冲突碰撞的情况,一旦出现过多就会影响 HashMap 的性能,所以在 JDK 1.8 中官方对数据结构引入了红黑树,当链表长度太长(默认超过 8)时链表就转为了红黑树,而红黑树的增删改查都比较高效,从而解决了哈希碰撞带来的性能问题。
面试官:
HashMap 构造方法中 initialCapacity(初始容量)、loadFactor(加载因子)有什么理解?
回 答:
initialCapacity 初始容量代表了哈希表中桶的初始数量,即 Entry< K,V>[] table 数组的初始长度,每次都会通过 roundUpToPowerOf2(initialCapacity) 方法来保证为 2 的幂次,也就是说你所传递的参数如果不是2的幂次方,系统会默认重置你的初始化参数。
loadFactor 加载因子是哈希表在其容量自动增加之前可以达到多满的一种饱和度百分比。使用这个加载因子计算每一次扩容的容量大小。系统默认负载因子为 0.75,一般情况下无需修改。
面试官:
HashMap怎么扩容,举例说明扩容的容量计算大小。
回 答:
HashMap 中默认的负载因子为 0.75,默认情况下第一次扩容阀值是 12(16 * 0.75),故第一次存储第 13 个键值对时就会触发扩容机制变为原来数组长度的二倍,以后每次扩容都类似计算机制。
面试官:
简单说说 JDK 1.8 中 HashMap 是如何扩容的?与 JDK 1.7 有什么区别?
回 答:
JDK1.7源码扩容中最核心的方法存在一个transfer的方法,源码如下:

扩容核心方法
整个扩容过程就是一个取出数组元素(实际数组索引位置上的每个元素是每个独立单向链表的头部,也就是发生 Hash 冲突后最后放入的冲突元素)然后遍历以该元素为头的单向链表元素,依据每个被遍历元素的 hash 值计算其在新数组中的下标然后进行交换(即原来 hash 冲突的单向链表尾部变成了扩容后单向链表的头部)
JDK1.7

JDK1.8
JDK1.8中核心的扩容方法有个resize()方法具体的会把哈希冲突的点重新分配到不同的索引中。
在 JDK1.7 中扩容操作时哈西冲突的数组索引处的旧链表元素扩容到新数组时如果扩容后索引位置在新数组的索引位置与原数组中索引位置相同,则链表元素会发生倒置。JDK1.8 则不会。
在JDK1.8 中为了性能在同一索引处发生哈西冲突到一定程度时链表结构会转换为红黑数结构存储冲突元素,故在扩容时如果当前索引中元素结构是红黑树且元素个数小于链表还原阈值(哈西冲突程度常量)时就会把树形结构缩小或直接还原为链表结构。
面试官:
你了解红黑树吗?简单说下红黑树的相关知识。
回 答:
你问的太多了,哈哈都唠饿了,有问题详细描述等我吃饱了再交流交流。欢迎关注下一篇文章,了解了解红黑树的秘密,以及相关的面试回答。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









