






表结构如下
sqlite> .schema exam
CREATE TABLE exam (id int primary key, name text, exam_time int, score int, age int, income int);其中exam_time保存的是UNIX时间戳(1970年1月1号以来的秒数)。
为了让superset能正常识别时间,需要修改exam表的字段定义。
Sources>Tables

选择Edit record,进入编辑界面:
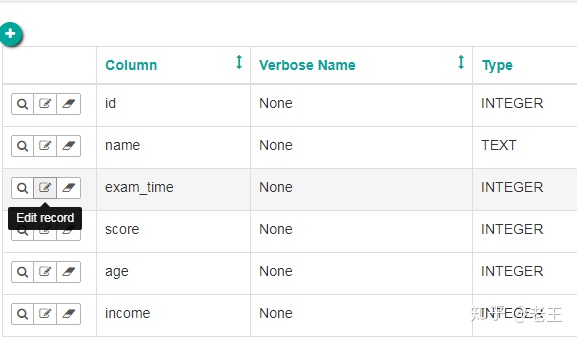
编辑exam_time字段的定义
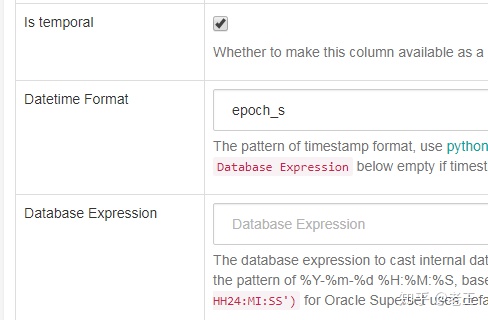
选中is temporal,在Datetime Format中设置格式为epoch_s。
这样,exam_time字段就可以在Time-Series类型的图表中,用作时间字段了。
这是以“day”为粒度,Superset在查询时生成的sqlite3 SQL语句:
SELECT DATE(datetime(exam_time, 'unixepoch')) AS __timestamp, AVG(score) AS "AVG(score)"
FROM exam GROUP BY DATE(datetime(exam_time, 'unixepoch')) ORDER BY "AVG(score)" DESC
LIMIT 10000 OFFSET 0改成以“week”为粒度:
SELECT DATE(datetime(exam_time, 'unixepoch'), -strftime('%W', datetime(exam_time, 'unixepoch')) || ' days') AS __timestamp, AVG(score) AS "AVG(score)"
FROM exam GROUP BY DATE(datetime(exam_time, 'unixepoch'), -strftime('%W', datetime(exam_time, 'unixepoch')) || ' days') ORDER BY "AVG(score)" DESC
LIMIT 10000 OFFSET 0以"month"为粒度:
SELECT DATE(datetime(exam_time, 'unixepoch'), -strftime('%d', datetime(exam_time, 'unixepoch')) || ' days', '+1 day') AS __timestamp, AVG(score) AS "AVG(score)"
FROM exam GROUP BY DATE(datetime(exam_time, 'unixepoch'), -strftime('%d', datetime(exam_time, 'unixepoch')) || ' days', '+1 day') ORDER BY "AVG(score)" DESC
LIMIT 10000 OFFSET 0这是以"month"为粒度时的效果:

另,构造测试数据时,用python自动写了一个csv文件,exam_time的数字前面有空格,在sqlite里.import 文件名 表名,能导入。但是执行select date(datetime(exam_time, 'unixepoch')) from exam limit 10转换出来的日期为空。
后来去掉csv文件中的空格,再次导入,date(datetime(exam_time, 'unixepoch'))才能正常转换。















 9021
9021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









