





本文适合有点Python基础阅读,(没基础的话,相对的比较蒙蔽,争取能让小白能一步一步跟上来)
2019-03-05 14:53:05
前几天由于需要到一个网站进行签到~~听说Python能够模拟请求,模仿点击,模仿浏览,于是突发奇想Python,能不能用Python模拟我点击呢?
说干就干:
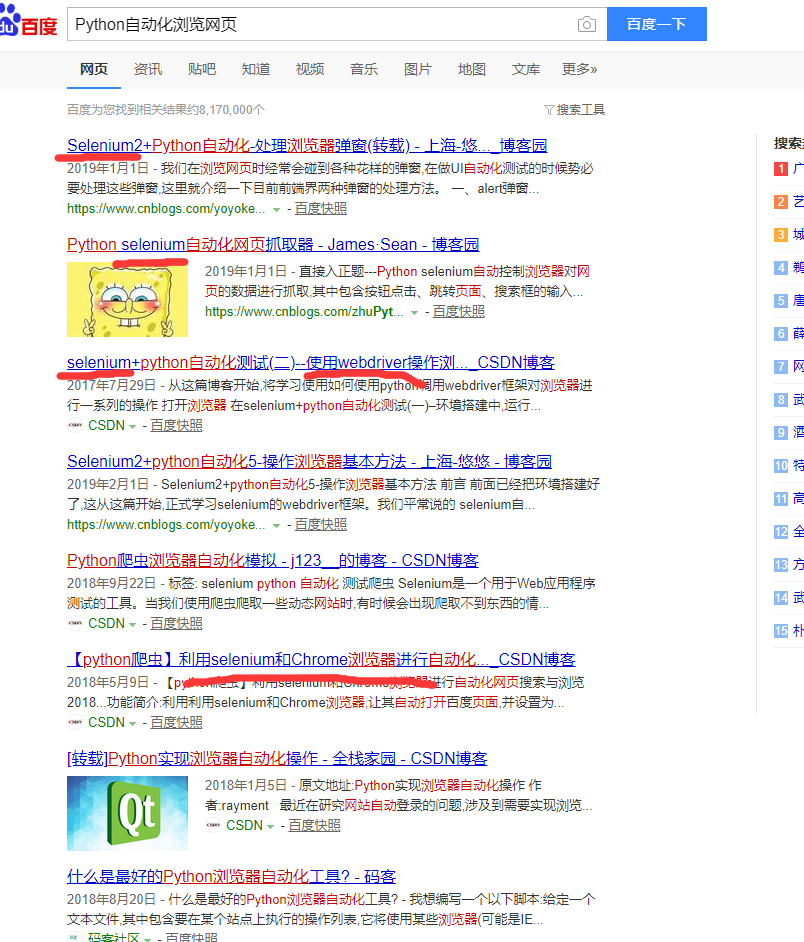
了解完毕,需要 的模块有 selenium 的webdriver
引用部分可点击参考文章查看详情,再次谢谢文章作者
先说一下selenium 的定位方法
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
前八种是大家都熟悉的,经常会用到的
1.id定位:find_element_by_id(self, id_)
2.name定位:find_element_by_name(self, name)
3.class定位:find_element_by_class_name(self, name)
4.tag定位:find_element_by_tag_name(self, name)
5.link定位:find_element_by_link_text(self, link_text)
6.partial_link定位find_element_by_partial_link_text(self, link_text)
7.xpath定位:find_element_by_xpath(self, xpath)
8.css定位:find_element_by_css_selector(self, css_selector)
这八种是复数形式
9.id复数定位find_elements_by_id(self, id_)
10.name复数定位find_elements_by_name(self, name)
11.class复数定位find_elements_by_class_name(self, name)
12.tag复数定位find_elements_by_tag_name(self, name)
13.link复数定位find_elements_by_link_text(self, text)
14.partial_link复数定位find_elements_by_partial_link_text(self, link_text)
15.xpath复数定位find_elements_by_xpath(self, xpath)
16.css复数定位find_elements_by_css_selector(self, css_selector
本次demo 演示:使用selenium 打开浏览器百度搜索: Cgrain (也就是我 /嘿嘿)
我们一步一步来:
名字你随意~~
导入 :
from selenium import webdriver
这个模块需要自己去pip
语法:pip install selenium
我这里已经弄好了,具体的可以查看此篇博文 Python安装selenium 作者 :夏晓旭
看到这一步默认前期工作已经完毕
接下来,进入下一个环节
(这里我用.Net 思维来简介一下~)
当你调用Dll,是不是想要声明,引用(类似我们刚刚的 pip install selenium ,from selenium import webdriver) ,当我们引用完毕,都需要先初始化需要引用的方法
XXX a =new XXX()
这里也是
我这里没有火狐浏览器,使用谷歌的
最初,导入所需的所有基本模块。该单元测试模块是内置Python基于Java的JUnit。该模块提供了组织测试用例的框架。该selenium.webdriver模块提供了所有的webdriver实现。目前支持的WebDriver实现是Firefox,Chrome,Ie和Remote。该键类提供键在键盘像RETURN,F1,ALT等。
#webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器,这里以Chrome为例
#1 在这里需要一个自动化插件 : https://sites.google.com/a/chromium.org/chromedriver/home (下载地址),我这里已经配置好了
browser = webdriver.Chrome()


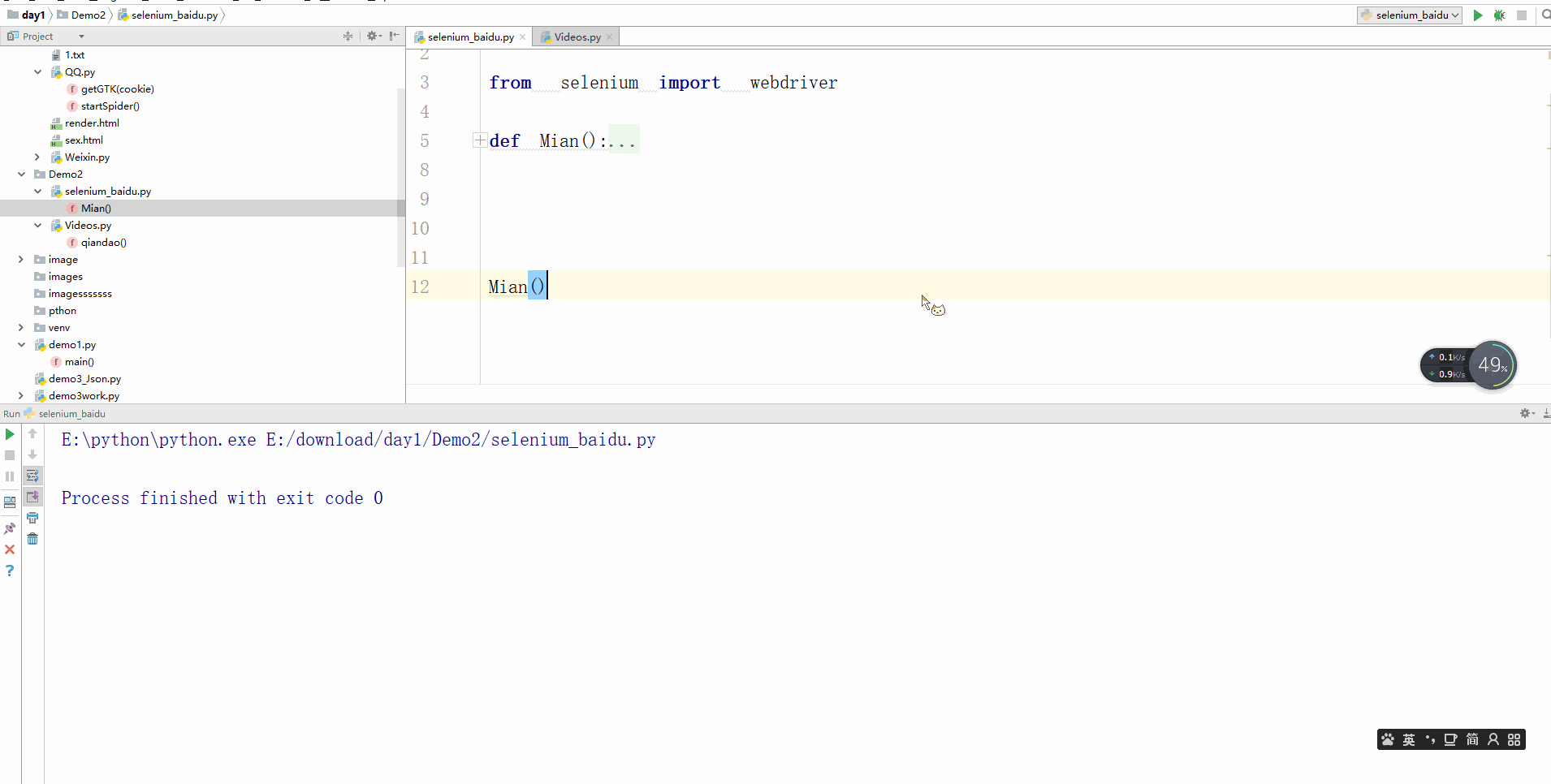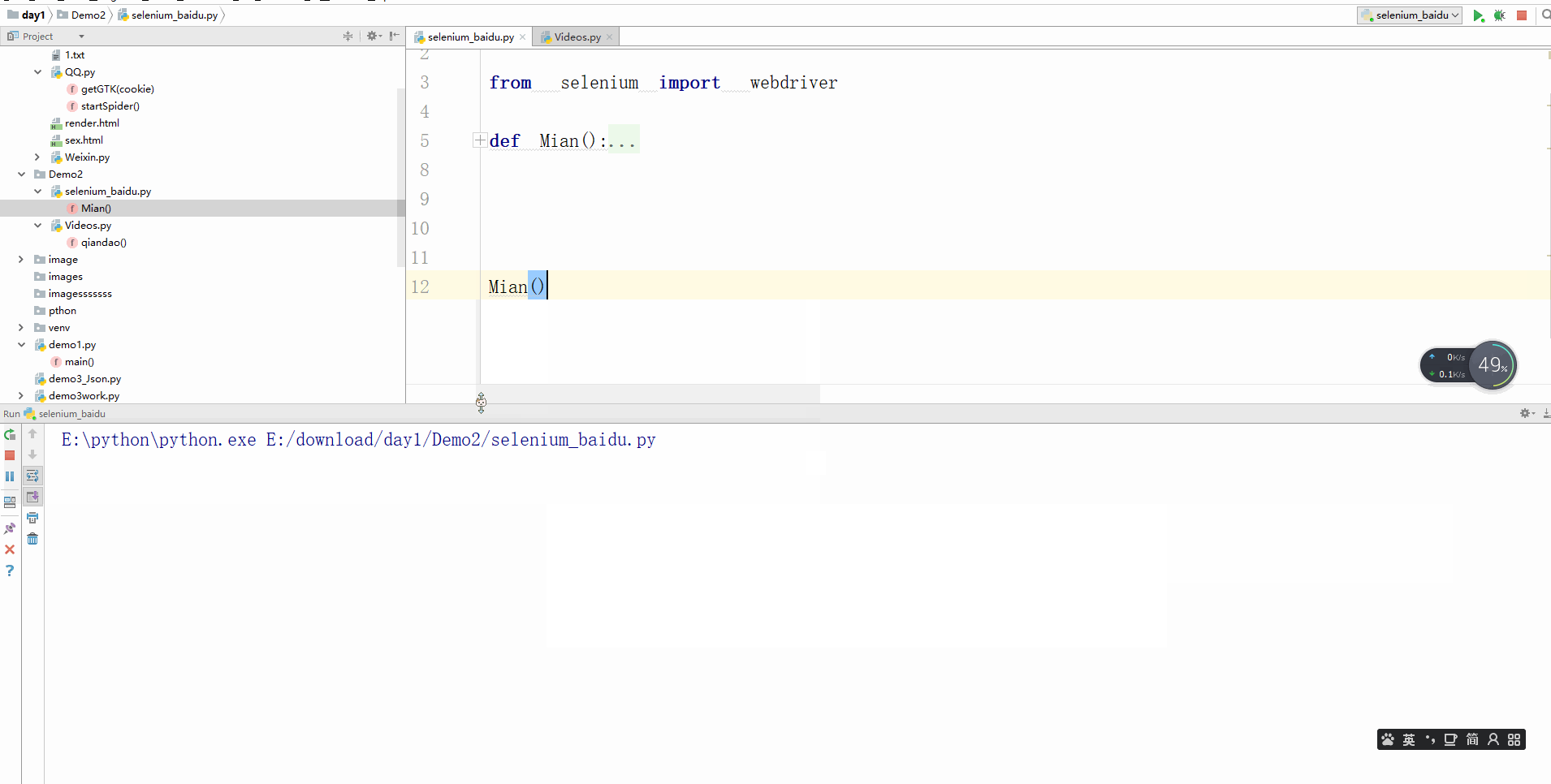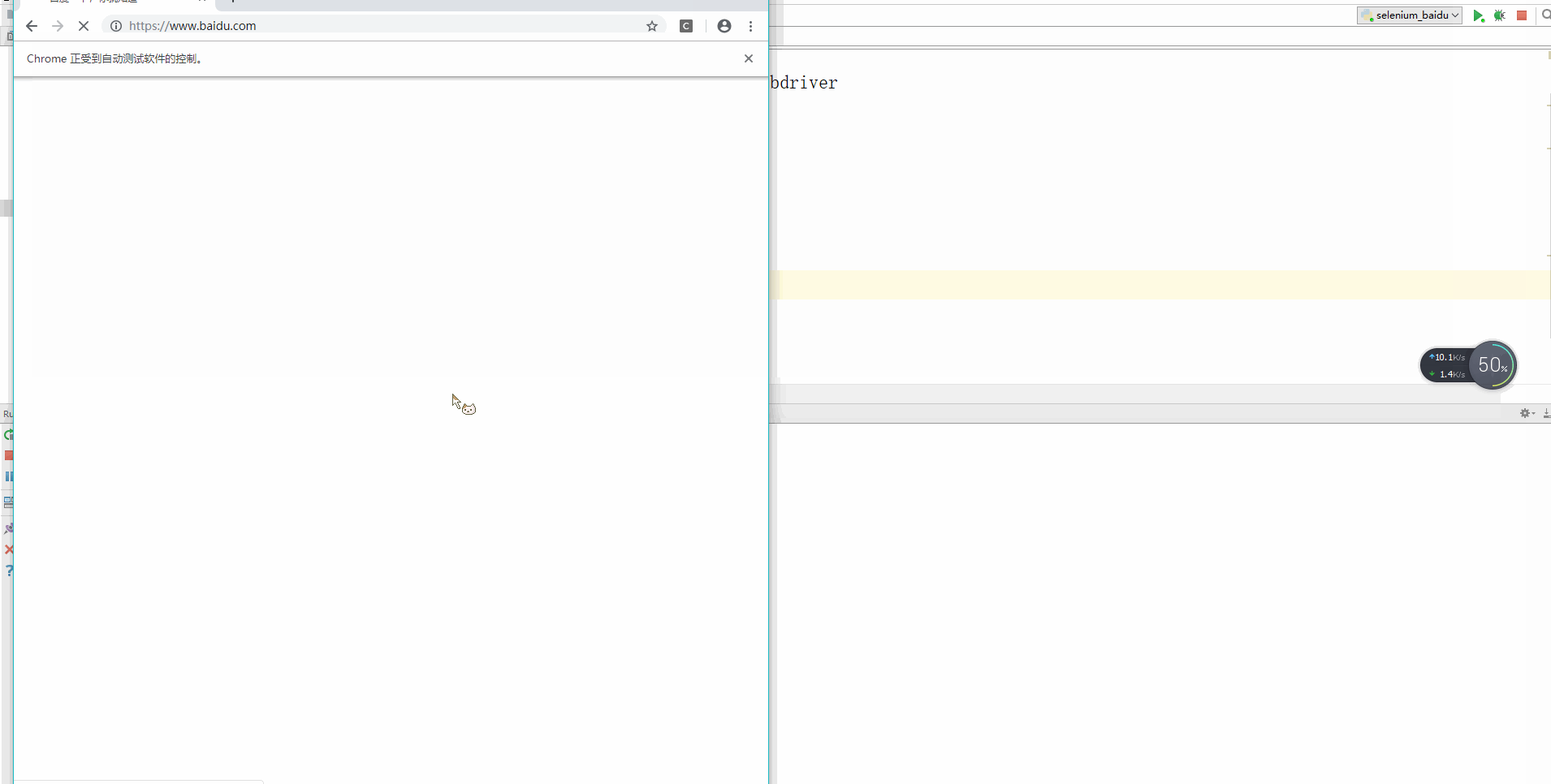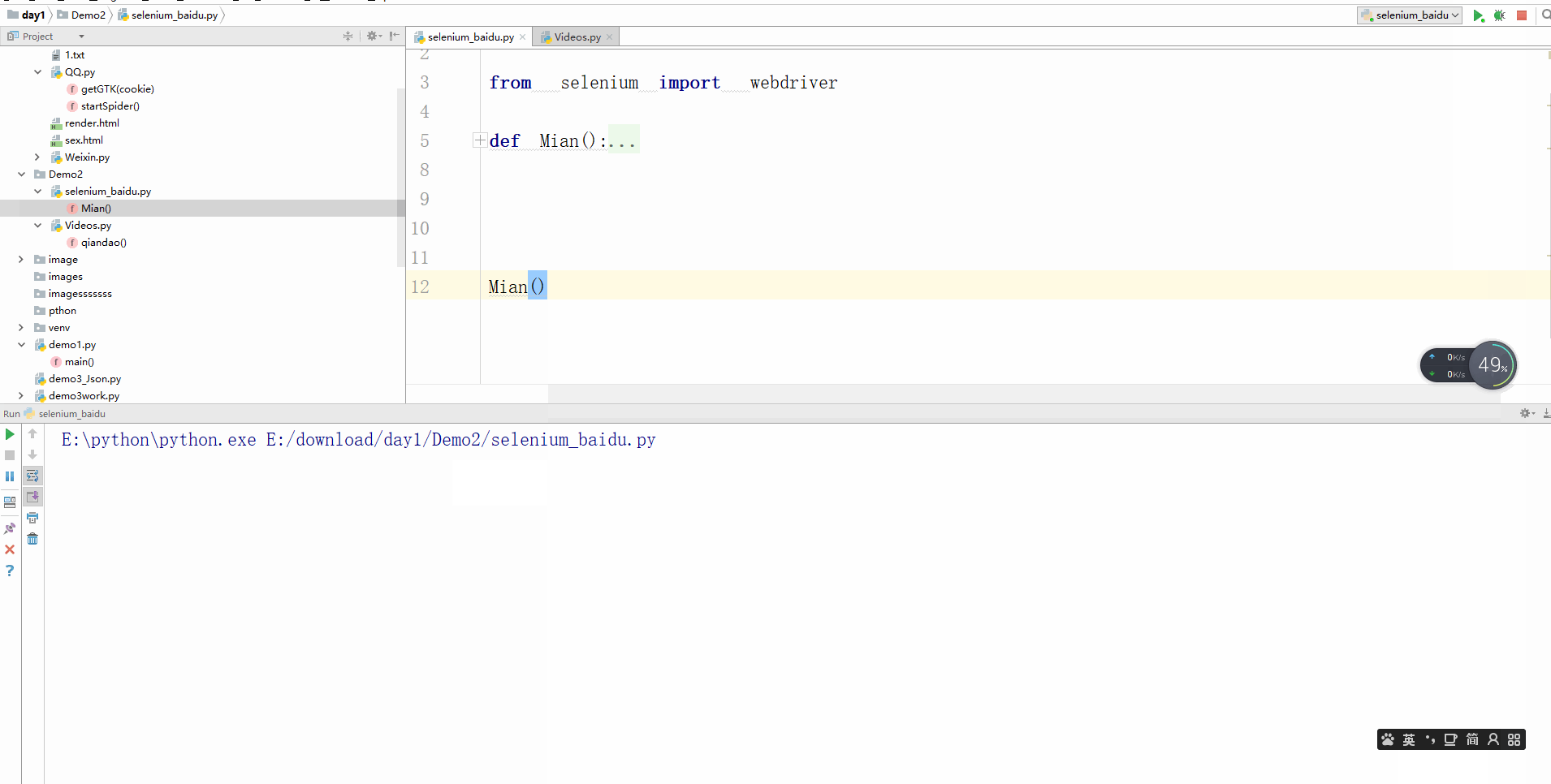
defMian():
seleniumGoo=webdriver.Chrome("")
seleniumGoo.get("https:www.baidu.com")
Mian()
No.1
好了,接下来我们使用百度搜索,Cgrain

检查文本框位置,id是“kw”
seleniumGoo.find_element_by_id("kw").send_keys("Cgrain博客园")
button按钮位置
seleniumGoo.find_element_by_id('su').click()

End ,到这里,本篇博文就结束了。下面我们讲的大概是:搜索完毕之后点进来
觉得好看就点个赞,关注我哦















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









