



 本文围绕Jmeter的HTML报告扩展展开,介绍了90%Line、QPS、吞吐量、TPS等指标的扩展方法,给出计算公式与关键代码。还指出Jmeter聚合结果中‘总体’一行在某些情况计算不准确,通过分样式表处理解决。最后对扩展指标进行测试,提及扩展中的难点。
本文围绕Jmeter的HTML报告扩展展开,介绍了90%Line、QPS、吞吐量、TPS等指标的扩展方法,给出计算公式与关键代码。还指出Jmeter聚合结果中‘总体’一行在某些情况计算不准确,通过分样式表处理解决。最后对扩展指标进行测试,提及扩展中的难点。
这里主要是获得时间元素的集合,以及90%line的位置,有了这两个参数后就可以进行后续的扩展了,扩展后的效果图如下:
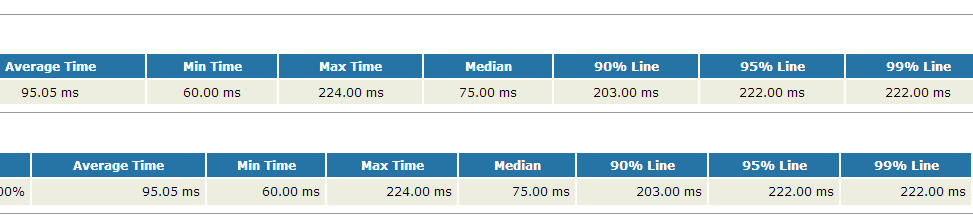
因为90%Line和95%Line,99%Line计算原理都是一致的,因此只要计算出一个值其他的值也很好计算
QPS扩展
Jmeter的具合报告有Throughput这个值,这个在loadrunner中是表示为吞吐量的,这里可以表示QPS或者TPS(在使用了事务的情况下),个人把这个称为QPS,因为更直观。
和%90Line同样的道理,首先必须知道这个值是怎么计算出来,经过查找资料和官网的比较,发现这个值是通过如下的公式计算出来的:
官网的截图:

Throughput = (number of requests) / (total time)
total time = 测试结束时间 - 测试开始时间
测试结束时间 = MAX(请求开始时间 + Elapsed Time)
测试开始时间 = MIN(请求开始时间)
知道了公式,那么计算就容易了,以下是关键代码:
扩展后的结果如下:
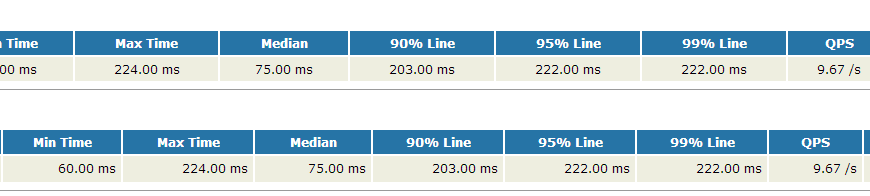
吞吐量扩展
在loadrunner中吞吐量就是Throughput,在Jmeter的聚合报告中最后一列的值就是loadrunner中的Throughput,为了便于区分,我把这里的值称为Throughput,
也就是吞吐量。
经过查找资料发现吞吐量的计算和QPS的计算公式是一样的,因为也就是如下的公式:
Throughput = (请求的总字节数) / (total time)
这里的total time计算和QPS是一样的,而总字节数直接把所有请求的加起来即可,关键代码如下:
因为这里显示的字节,最后的结果我打算以KB的单位显示,因此这里需要除以1024,扩展后的结果如下

TPS扩展
TPS在Jmeter中虽然某些情况和QPS是一致的,但是还是有不一致的地方,因此这里也需要扩展,这样的结果看着更清晰明了。
首先和其他的参数扩展一样,需要知道计算公式,这里的计算公式和QPS也是一样的,只是数据的集合不一样,以下是扩展后的效果。
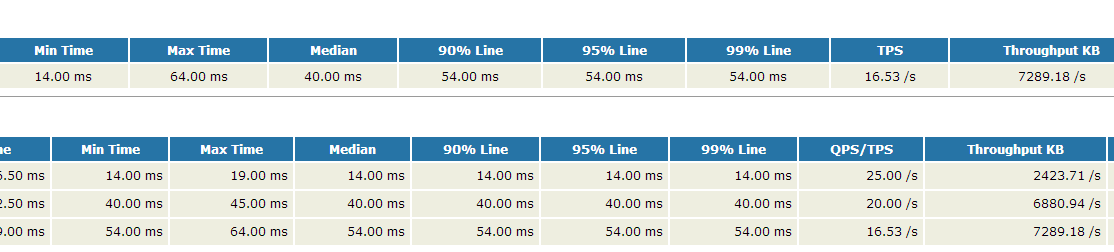
在扩展的过程中进一步发现Jmeter的聚合结果中最后的”总体“一行在某些情况下计算的数值是不准确的。如果脚本中不包含事务,那么这里的结果是准确的,如果都包含事务并且把
Generate parent sample选中后这里的结果也是准确的,在脚本中有事务并且没有选中Generate parent sample,或者有些有事务有些没有时,这时的结果就不准确了,因为查看计算
方式发现它把所有的请求都算进去了。
比如,一个jtl文件中即包含HTTP请求也包含事务,因为事务只是对之前请求的一个统计,本身是不发送请求的,所以计算总的吞吐量、QPS,TPS时是不能这么算的。
所以在扩展的过程中分成了两个样式表,一个样式表处理包含事务,或者没有事务的情况,这时的结果以QPS衡量;一个样式表处理全都是事务的情况,这时候的结果以TPS衡量,这样
就准确了。
测试
扩展了好几个指标,这些指标的正确性如何呢?需要在多种情况下进行测试,经过测试后各个指标都是正确的。但是还没有在大的数据量级别下测试,如果测试后发现哪里会有问题,会及时
更改。
切记:由于样式表中是按照lb进行请求区分的,因此这里的lable不能重复,本身也不应该重复,包括Jmeter的聚合报告都是以lable进行区分的
PS:在扩展过程中的难点一是公式如何计算的,二是xls这个 指扩展样式表语言不是很熟悉,本身也有很多限制,会在下个博客中说明。但是用过后感觉还是很不错的既熟悉了xpath还熟悉了xls。
三是需要对Jmeter的测试结果文件每个字段戴表什么意思熟悉,这样才能定制更多的指标,这个也会在单独的博客中说明

















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









