






开始学习语音识别的时候,第一步工作就是把语音转为特征,有mfcc和fbank,fbank包含的信息量多,所以开始就用了fbank。有很多工具可以帮忙提取fbank特征,我常用的是kaldi和python_speech_features这两种方式。
但是这两种提取fbank的特征却差异很大,怀着对两者的敬畏之心,开启了探索比较的学习之路。由于python_speech_features的结构简单,所以从这里看起。可以简洁明朗的看到,python_speech_features的fbank特征提取分以下几个步骤:
1.预加重(pre-emphasis):y(n)=x(n)-ax(n-1), a = 0.97
2.分帧,对每帧计算功率谱(DFT,power-spectrum)
3.计算梅尔滤波器组(mel-filterbanks),计算功率谱和滤波器组的内积,并将内积转为db,即为特征
在python_speech_features的fbank特征提取方法熟悉了之后,开始查看kaldi的方法。
kaldi的复杂很多,首先看shell脚本(路径在:kaldi/egs/wsj/s5/steps/make_fbank_pitch.sh),其中136行有一句:
fbank_feats="ark:compute-fbank-feats $vtln_opts --verbose=2 --config=$fbank_config scp,p:$logdir/wav.JOB.scp
compute-fbank-feats是计算特征的函数,其中配置文件--config在kaldi/egs/aishell/s5/conf/fbank.conf, scp=$data/wav.scp,scp是语音文件地址
我的配置如下:
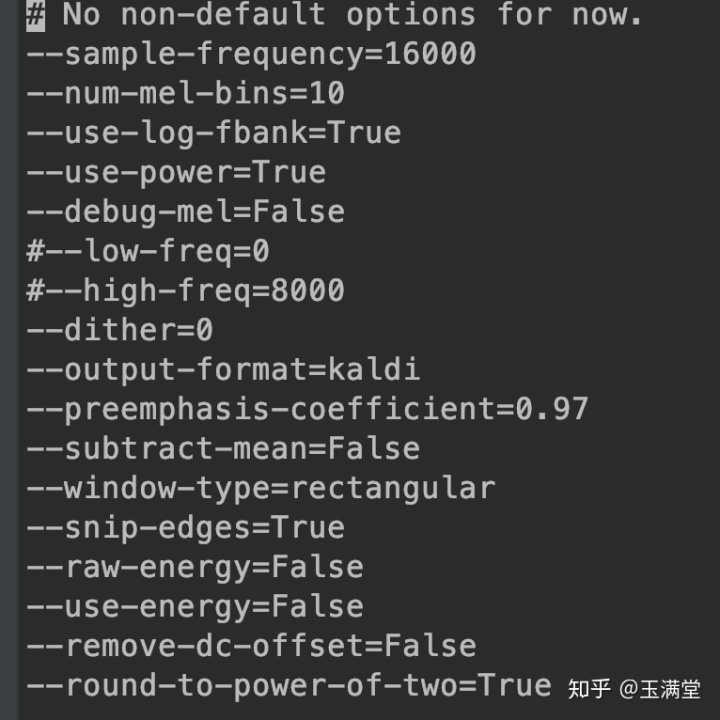
为了能单独运行compute-fbank-feats 这个bin文件,进入到kaldi/src/featbin这个目录下,可以看到可运行的bin文件:compute-fbank-feats,运行命令如下:
./compute-fbank-feats --verbose=2 --config="/disk1/code/kaldi/egs/aishell/s5/conf/fbank.conf" scp:/disk1/code/kaldi/egs/aishell/s5/data/wav.scp ark:/disk1/code/kaldi/egs/aishell/s5/data/a3.ark
wav.scp 只放了一个音频,a2.ark是生成的二进制特征,使用copy-feats可以将二进制特征转为txt文件:
./copy-feats ark:/disk1/code/kaldi/egs/aishell/s5/data/a3.ark ark,t:/disk1/code/kaldi/egs/aishell/s5/data/txt.ark
上述是生成特征的过程,会发现kaldi的特征和python_speech_features的特征差异很大,下面正式开始kaldi的特征生成过程深入挖掘。
这期间需要使用到gdb,c的调试工具,以前玩过c的人肯定很熟悉,这里有几个常用命令需要在这里复习一下:
b(break):设置断点
c(continue):继续
n(next):下一步(不进入函数)
r(run):运行
print:打印变量
s(step) :下一步(进入函数)
bt(backtrace): 查看堆栈
finish :退出函数
list : 查看当前运行到的位置
以上的信息基本够用了,如果还想看更多详细命令,可以去官网查看
大概说一下gdb调试的过程:
首先 :
gdb compute-fbank-feats
然后 :
set args --verbose=2 --config="/disk1/code/kaldi/egs/aishell/s5/conf/fbank.conf" scp:/disk1/code/kaldi/egs/aishell/s5/data/wav.scp ark:/disk1/code/kaldi/egs/aishell/s5/data/a3.ark
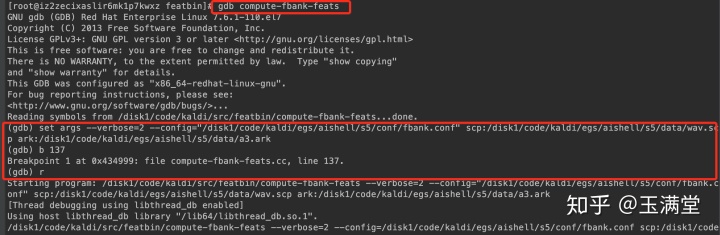
当然,为了能够看kaldi自定义的变量内容,需要对变量权限修改一下,将protected改为public
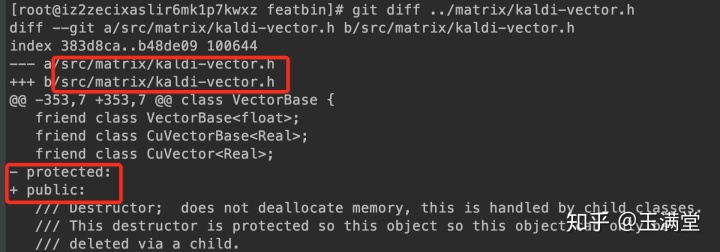
修改完成后,需要重新编译一下compute-fbank-feats ,进入/disk1/code/kaldi/src/featbin,该目录下自带Makefile,直接make就okay了~
make完成之后,重新gdb启动,然后就可以看data_这个内部变量啦!
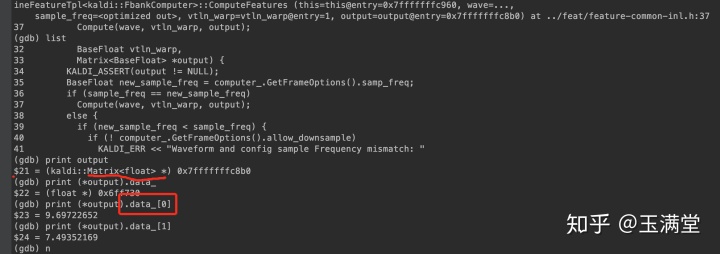
好了,下面开始进入主题,讲不同!
————————————————————————————————————————————————————————————————————————————————————
kaldi 和 python_speech_features 生成fbank特征的不同地方在于以下几点:
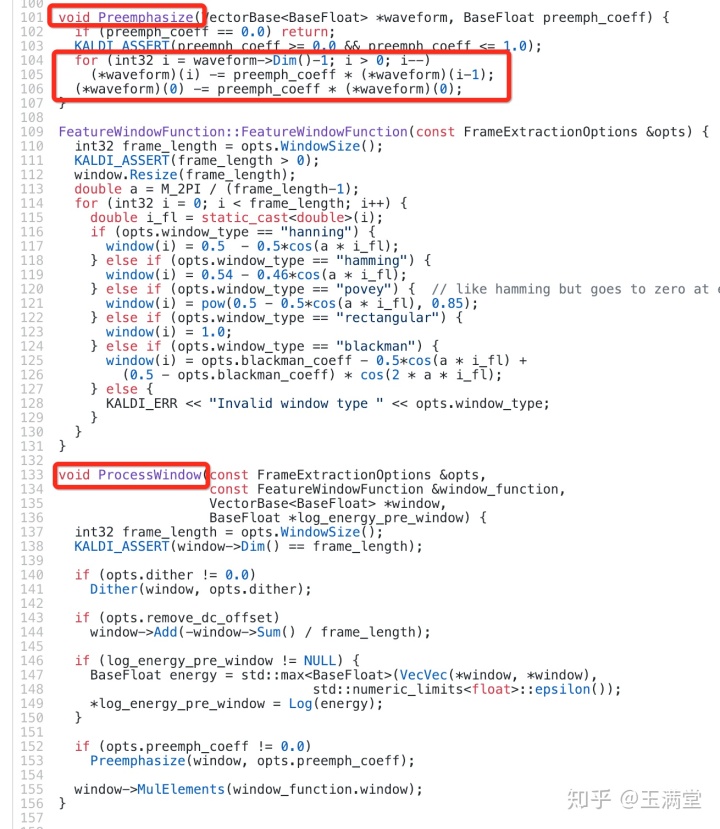
- 预加重不同:
* kaldi是先加窗分帧,再对帧内进行预加重;python_speech_features是全体先预加重,然后再分帧;
* 再看预加重,会发现,对于音频数据(譬如10,17,13,15, ...)第一个数据10,python_speech_features是不变(预加重系数0.97,预加重后是 10,7.3,-3.489,2.39,...),kaldi是第一个数据也做预加重(预加重后是 0.3,7.3,-3.489,2.39,...)

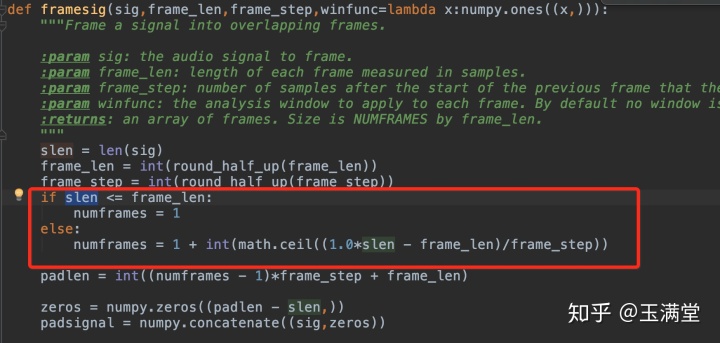
2. 分帧数不同,功率谱计算不同
python_speech_features 对最后还剩余的数据,不足帧长的,按照一帧计算补齐;
kaldi 如果选择不切断最后剩余数据(snip-edged = False),会发现多了一帧(个人认为这里kaldi错了,python_speech_features正确);如果snip-edged = True,两者一致
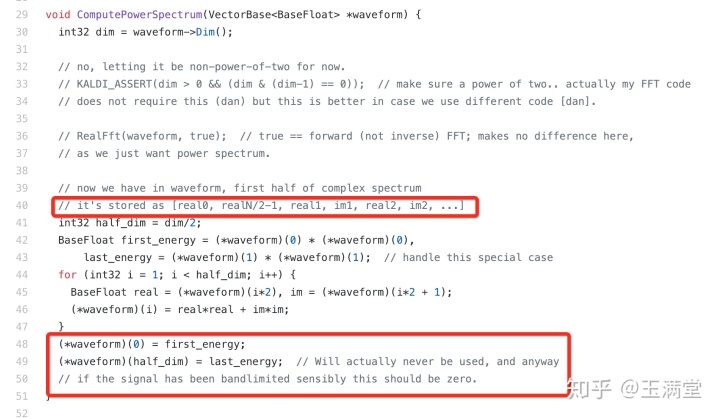
功率谱计算不同:
python_speech_features 计算功率谱是:1.0/NFFT * numpy.square(magspec(frames,NFFT))
kaldi 没有乘1.0/NFFT


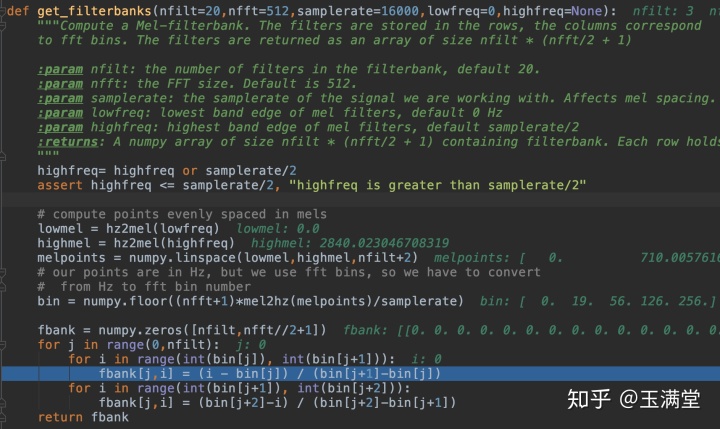
3. 梅尔滤波器组计算方法不同
kaldi是在梅尔坐标转换后的梅尔值域计算,index是hz的定义域,通过梅尔转换后比较(个人认为计算量偏大,每次计算都要经过一次转换);
而python_speech_features是先将linspace后的梅尔值统一转成了hz,再进行计算,index也是hz的定义域,计算量小
其实上述两种的本质是一样的,计算方法不同会导致系数存在差异

















 7051
7051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









