





感觉自己对CTR的论文读的太少,因此后续会在专栏记录一下阅读论文的笔记和心得。
2016年Google发表了文章《Wide & Deep Learning for Recommender Systems》,本文主要记录了在读论文时的笔记和一些心得。
一、论文笔记
1、目的:同时解决Memorization和Generalization问题。
Memorization:根据人工经验和业务背景,选择可能对label有较大影响的原始特征和组合特征输入到模型,让模型通过训练记忆数据中重要的特征。典型代表是LR,使用大量的原始特征和交叉特征作为输入。优点是可解释性高、实现快速高效。缺点是人工设计较多,输入过于细粒度的特征交叉会导致过拟合,模型记忆的只有部分通过训练得到高权重的组合特征而已,对于输入中未添加过的组合特征以及添加过的但是由于训练数据中共现频次为0的组合特征,模型的权重都为0,即没有记忆,无法“扩展”。
Generalization:为高维稀疏的输入特征学习低维稠密的Embedding向量表示,然后将Embedding向量输入到神经网络做深层交互。正如NLP里的词向量一样,通过Embedding将特征向量化,显示特征之间相关性,使模型具备了“扩展”的能力。Generalization的代表是FM、DNN。其优点是人工设计少,可以“扩展”。缺点是存在过度扩展的可能,例如在推荐系统中,用户评分矩阵极度稀疏,大部分的user和item应该是没有关联的,但是经过Embedding向量表示,大部分的user和item之间的评分预测并不为0。
2、模型结构图:
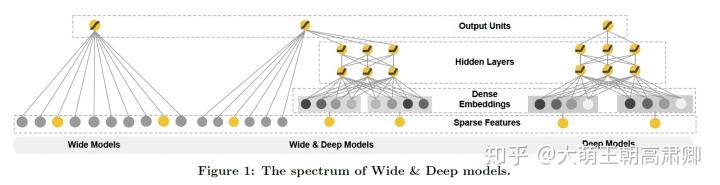
3、预测公式:
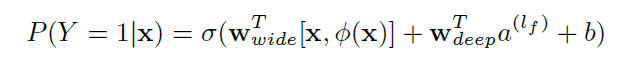
其中
在具体实现时,wide侧的输入是一些原始特征尤其是类别特征以及组合特征,数值型特征如年龄也会分桶转化为类别输入,分桶的目的在于CTR问题label与数值型特征并不会是线性关系,往往与分段有关。比如年龄对是否下载腾讯动漫APP的影响,20岁与22岁无差别,但是20岁与30岁差别就挺大的。deep侧主要是输入原始的数值型特征、类别特征(类别多的做Embedding),然后在深层神经网络做隐式深层交互。
4、具体实现:
TensorFlow官方有实现的类tf.estimator.DNNLinearCombinedClassifier。但是我运行官方的TensorFlow Wide & Deep Learning Tutorial总是出错,所以我换了其他的教程
TensorFlow Wide & Deep Learning Tutorial(广泛深入的学习教程)cloud.tencent.com还有不使用TensorFlow的numpy实现:
石塔西:用NumPy手工打造 Wide & Deepzhuanlan.zhihu.com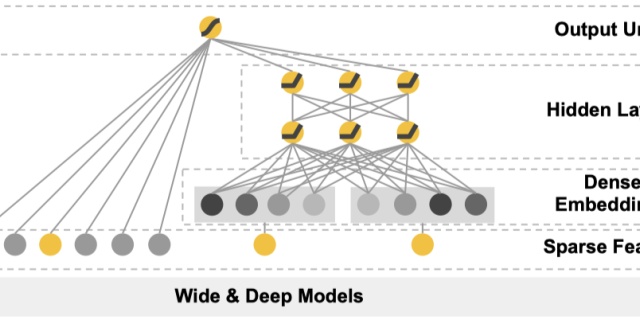
二、心得:
这里主要记录了在阅读论文之前和阅读过程中产生的一些问题以及自己的理解。
问题1:为啥wide侧是记忆,deep侧是扩展?
答:wide侧输入特征固定,后续并没有再进行特征交叉,且历史上未出现的特征对则对应权重会是0,因此是记忆。deep侧由于使用低维稠密向量表示特征,特征之间的相关性就可以由向量之间计算得到,如计算向量的余弦夹角。由于向量是低维稠密的,因此任意两个特征之间的相关性基本不为0,甚至会有想不到的特征之间相关性很高,这样就具备了良好的扩展能力。PS:我也不知道当初为什么明白NLP里的词向量原理以及推荐系统的矩阵分解,却不明白deep侧可以扩展,就像初中高中有些数学题答案里面有显然二字,当时想不通,最后弄明白了再一想可不就是显然嘛,但是当时为什么想不到就不知道了。可能是当时没有这样的思维方式吧。
三、总结:
Wide&Deep论文的原理并不复杂,我的时间主要耗在那个numpy实现上。建议阅读论文原文
https://arxiv.org/abs/1606.07792arxiv.org,然后看看一些详解即可。
石塔西:看Google如何实现Wide & Deep模型(1)zhuanlan.zhihu.com














 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









