






一:简介
Wide&Deep全文围绕着“记忆”(Memorization)与“扩展(Generalization)”两个词展开。实际上,它们在推荐系统中有两个更响亮的名字,Exploitation & Exploration,即著名的EE问题。分为wide和deep两个部分,其实就是LR和DNN的组合
wide侧就是普通的LR模型,需要根据人工经验构建常用特征喂入模型中,让wide侧记住这些信息,deep侧就是DNN,主要用来对category特征进行embedding处理,将稀疏矩阵映射为稠密矩阵,让DNN学习特征的深度交叉,易于扩展。
二:模型结构
与传统搜索类似,推荐系统的一个挑战是如何同时获得推荐结果准确性和扩展性。推荐的内容都是精准内容,用户兴趣收敛,无新鲜感,不利于长久的用户留存;推荐内容过于泛化,用户的精准兴趣无法得到满足,用户流失风险很大。相比较推荐的准确性,扩展性倾向与改善推荐系统的多样性。
2.1:Wide部分
Wide部分就是基础的线性模型,表示为y=WX+b。X特征部分包括基础特征和交叉特征。交叉特征在wide部分很重要,可以捕捉到特征间的交互,起到添加非线性的作用。交叉特征可表示为:
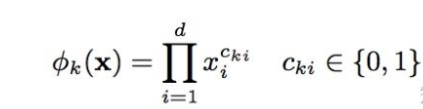 |
2.2:Deep部分
Deep部分就是个前馈网络模型。特征首先转换为低维稠密向量,维度通常O(10)-O(100)。向量随机初始化,经过最小化随时函数训练模型。激活函数采用Relu。前馈部分表示如下:
2.3. 联合训练(Joint Trainning)
在训练的时候,根据最终的loss计算出gradient,反向传播到Wide和Deep两部分中,分别训练自己的参数。也就是说,两个模块是一起训练的(也就是论文中的联合训练),注意这不是模型融合。
- Wide部分中的组合特征可以记住那些稀疏的,特定的rules
- Deep部分通过Embedding来泛化推荐一些相似的items
Wide模块通过组合特征可以很效率的学习一些特定的组合,但是这也导致了他并不能学习到训练集中没有出现的组合特征。所幸,Deep模块弥补了这个缺点。 另外,因为是一起训练的,wide和deep的size都减小了。wide组件只需要填补deep组件的不足就行了,所以需要比较少的cross-product feature transformations,而不是full-size wide Model。 具体的训练方法和实验请参考原论文。
三:代码实现
import tensorflow as tf
_CSV_COLUMNS = [
'age', 'workclass', 'fnlwgt', 'education', 'education_num',
'marital_status', 'occupation', 'relationship', 'race', 'gender',
'capital_gain', 'capital_loss', 'hours_per_week', 'native_country',
'income_bracket'
]
_CSV_COLUMN_DEFAULTS = [[0], [''], [0], [''], [0], [''], [''], [''], [''], [''],
[0], [0], [0], [''], ['']]
_NUM_EXAMPLES = {
'train': 32561,
'validation': 16281,
}
# 1. Read the Census Data
# 2. Converting Data into Tensors
def input_fn(data_file, num_epochs, shuffle, batch_size):
"""为Estimator创建一个input function"""
assert tf.gfile.Exists(data_file), "{0} not found.".format(data_file)
def parse_csv(line):
print("Parsing", data_file)
# tf.decode_csv会把csv文件转换成很a list of Tensor,一列一个。record_defaults用于指明每一列的缺失值用什么填充
columns = tf.decode_csv(line, record_defaults=_CSV_COLUMN_DEFAULTS)
features = dict(zip(_CSV_COLUMNS, columns))
labels = features.pop('income_bracket')
return features, tf.equal(labels, '>50K') # tf.equal(x, y) 返回一个bool类型Tensor, 表示x == y, element-wise
dataset = tf.data.TextLineDataset(data_file) \
.map(parse_csv, num_parallel_calls=5)
if shuffle:
dataset = dataset.shuffle(buffer_size=_NUM_EXAMPLES['train'] + _NUM_EXAMPLES['validation'])
dataset = dataset.repeat(num_epochs)
iterator = dataset.make_one_shot_iterator()
batch_features, batch_labels = iterator.get_next()
return batch_features, batch_labels
# 3. Select and Engineer Features for Model
## 3.1 Base Categorical Feature Columns:离散特征的两种处理情况
# 如果我们知道所有的取值,并且取值不是很多
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
'relationship', [
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried',
'Other-relative'
]
)
# 如果不知道有多少取值
occupation = tf.feature_column.categorical_column_with_hash_bucket(
'occupation', hash_bucket_size=1000
)
education = tf.feature_column.categorical_column_with_vocabulary_list(
'education', [
'Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'
]
)
marital_status = tf.feature_column.categorical_column_with_vocabulary_list(
'marital_status', [
'Married-civ-spouse', 'Divorced', 'Married-spouse-absent',
'Never-married', 'Separated', 'Married-AF-spouse', 'Widowed']
)
workclass = tf.feature_column.categorical_column_with_vocabulary_list(
'workclass', [
'Self-emp-not-inc', 'Private', 'State-gov', 'Federal-gov',
'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'])
# 3.2 Base Continuous Feature Columns:原始的连续特征
age = tf.feature_column.numeric_column('age')
education_num = tf.feature_column.numeric_column('education_num')
capital_gain = tf.feature_column.numeric_column('capital_gain')
capital_loss = tf.feature_column.numeric_column('capital_loss')
hours_per_week = tf.feature_column.numeric_column('hours_per_week')
#Sometimes the relationship between a continuous feature and the label is not linear. As a hypothetical example, a person's income may grow with age in the early stage of one's career, then the growth may slow at some point, and finally the income decreases after retirement. In this scenario, using the raw age as a real-valued feature column might not be a good choice because the model can only learn one of the three cases:
# 3.2.1 连续特征离散化:age分桶:规范化到{0,1}的连续特征
# 之所以这么做是因为:有些时候连续特征和label之间不是线性的关系。可能刚开始是正的线性关系,后面又变成了负的线性关系,这样一个折线的关系整体来看就不再是线性关系。
# bucketization 装桶
# 10个边界,11个桶
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
# 3.3 组合特征/交叉特征: 两组
education_x_occupation = tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000)
age_buckets_x_education_x_occupation = tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000
)
# 4. 模型:组装线性模型这块,这里主要用了离散特征+组合特征
"""
之前的特征:
1. CategoricalColumn
2. NumericalColumn
3. BucketizedColumn
4. CrossedColumn
这些特征都是FeatureColumn的子类,可以放到一起
"""
base_columns = [
education, marital_status, relationship, workclass, occupation,
age_buckets,
]
crossed_column = [
tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000
),
tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000
)
]
model_dir = "./model/wide_component"
model = tf.estimator.LinearClassifier(
model_dir=model_dir, feature_columns=base_columns + crossed_column
)
train_file = './data/adult.data'
val_file = './data/adult.data'
test_file = './data/adult.test'
# 5. Train & Evaluate & Predict:训练和评估
model.train(input_fn=lambda: input_fn(data_file=train_file, num_epochs=1, shuffle=True, batch_size=512))
results = model.evaluate(input_fn=lambda: input_fn(val_file, 1, False, 512))
for key in sorted(results):
print("{0:20}: {1:.4f}".format(key, results[key]))
pred_iter = model.predict(input_fn=lambda: input_fn(test_file, 1, False, 1))
for pred in pred_iter:
print(pred)
break #太多了,只打印一条
test_results = model.evaluate(input_fn=lambda: input_fn(test_file, 1, False, 512))
for key in sorted(test_results):
print("{0:20}: {1:.4f}".format(key, test_results[key]))
# 6. 正则化
model = tf.estimator.LinearClassifier(
feature_columns=base_columns + crossed_column, model_dir=model_dir,
optimizer=tf.train.FtrlOptimizer(
learning_rate=0.1,
l1_regularization_strength=1.0,
l2_regularization_strength=1.0
)
)
四:总结
缺点:Wide部分还是需要人工特征工程。
优点:
1. 详细解释了目前常用的 Wide 与 Deep 模型各自的优势:Memorization 与 Generalization。实现了对memorization和generalization的统一建模。能同时学习低阶和高阶组合特征
2. 结合 Wide 与 Deep 的优势,提出了联合训练的 Wide & Deep Learning。相比单独的 Wide / Deep模型,实验显示了Wide & Deep的有效性,并成功将之成功应用于Google Play的app推荐业务。















 4352
4352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









