






- 排序中的算法思想:复杂度分析与各个经典排序算法的思想
- 分治与二分:能进行二分的前提、二分边界值的思考
- 搜索:包括深度优先搜索和广度优先搜索
- 贪心:几类典型的贪心问题
- 动态规划:dp的三个过程,背包,字符串等经典dp模型
- 面试必考之链表和二叉树:链表、二叉树、二分搜素树
- 刷题必知数据结构:并查集,单调队列,堆,哈希
- 选择排序
- 冒泡排序
- 计数排序
- 归并排序
- 快速排序

1. 复杂度分析
对于诸多算法,我们一般从时间和空间两个角度来进行评价,即时间复杂度和空间复杂度。复杂度分析有很多记号,比较常用的是大O记号。对于数据规模为n的问题,其时间复杂度可以近似认为是代码的执行次数,空间复杂度可以近似认为是存储数据所需要开辟的内存容量。例如:当程序执行如下for循环时,由于循环了n次,可以认为时间复杂度为O(n),而数组a的长度为n,因此空间复杂度也为O(n)
int a[n]; for(int i=0; i<=n; i++){ a[i] = i;}当然,例子只是用来说明问题,在真正分析算法的时候,会稍微复杂一些。一般分析时间复杂度时,只有这几类:
O(n^2):如选择排序,冒泡排序
O(nlogn):如归并排序,快速排序(平均意义),堆排序
O(n):如计数排序
O(1):常数级复杂度,如哈希map的查找
列出的时间复杂度依次降低,对O(n^2)来说,一般允许代码运行的时间最多是1秒,这意味着数据规模n最大只能到10万,如果n的规模超过10万,就必须对算法进行优化,如O(nlogn)才可以过。注意,复杂度只是一个近似刻画,如复杂度O(n^2+nlogn)可以直接记为O(n^2),因为nlogn 相比n^2 是小量,小量可以直接忽略。再比如O(2n+1),可直接记为O(n)
分析空间复杂度时要简单一些,只要看占用了多大空间即可,比如一维数组O(n),二维数组O(n^2)等。需要注意的是,算法题目一般会限制空间大小,如128M,512M等,我们要学会估算自己的代码是否会超过给定的内存空间。
假设内存为1GB,那么近似为1GB = 1e3 M = 1e6 KB = 1e9 B,而一个int对象占用4字节,所以当数据规模为10万时,我们就不能直接开n*n的二维数组来进行处理了。
为了简洁性,本系列中的代码将只聚焦于核心部分,对不影响理解的部分一律省略处理,假设下面排序数组长度为n。
2. 选择排序
思想:从前往后依次选择最小的数字,放在最前面。每次排好一个,因此排列n个数字一共需要排n次。每次最多需要进行(n-1)次比较。该算法直接在原数组上操作,没有使用额外空间,因此是原地排序。
时间复杂度: O(n^2)
空间复杂度: O(n)
依次确定a[0],a[1],...a[i]应该放的数。比如,当前正在排a[i]处的数字,需要在[i,n-1]之间查找出最小值的索引,然后进行交换
for(int i=0; i int min_index = i; for( int j=i; j if(a[j] < a[min_index]) min_index = j; } swap(a[i], a[min_index]);}3. 冒泡排序
思想:从前往后依次两两比较,将大的往后挪,这样一次扫描后,最大值就会被挪到数组末尾。同样,这个算法一次扫描只能排好一个数字,排好n个数字需n次操作。对第i次操作,扫描范围是[0,i-1],原地排序

优化:当某次扫描时,没有发生swap操作,则说明剩余的元素已经有序,可提前终止
时间复杂度:O(n^2)
空间复杂度: O(n)
for(int i=1; i for(int j=0; j if( a[j+1] > a[j]) swap(a[j+1], a[j]); }}// 优化for(int i=1; i bool flag = true; for(int j=0; j if( a[j+1] > a[j]) { swap(a[j+1], a[j]); flag = !flag; } } if(flag) break;}4. 计数排序
思想:观察到待排序的数字都是整数,可以用一个空数组count,记录各个数字出现的频次。整个排序过程为,先扫描原数组a,将a中的所有元素在count数组中记录,然后再扫描count数组,依次输出。本质上,count数组充当了哈希表的功能。很显然,这里引入了新的数组,需要额外的空间,所以这种算法是非原地的。假设a数组中的最大值为a_max
时间复杂度:O(n) + O(a_max)
空间复杂度:O(n+a_max)
总体上,这种算法牺牲了额外的空间,将时间复杂度降低了线性,这是一种典型的时空权衡思想,这种思想在动态规划部分也得到了充分运用
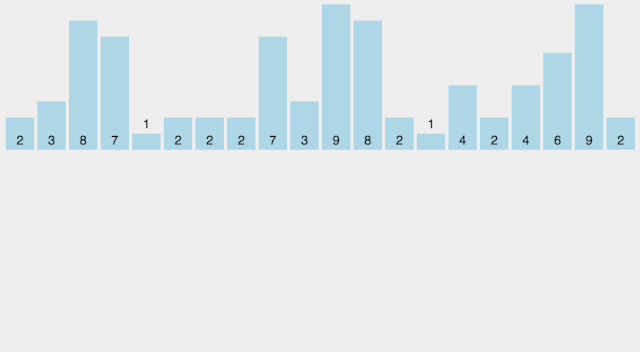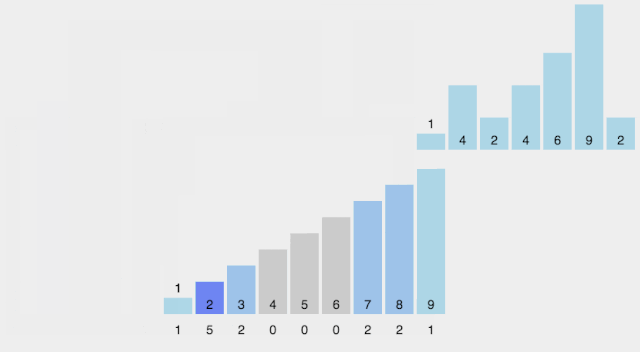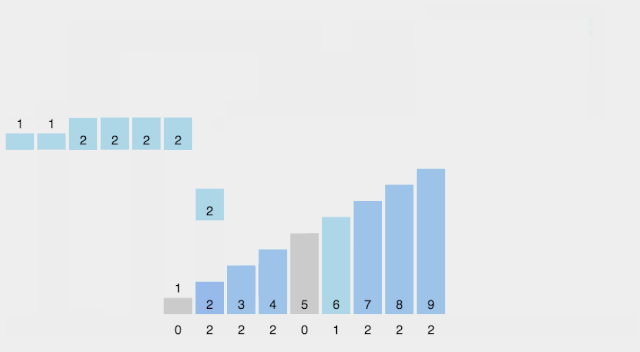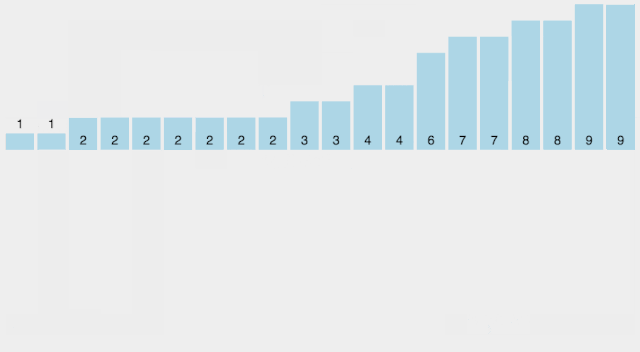
// 计数a_max = -1;for(int i=0; i < n; i++){ count[a[i]]++; a_max = max(a_max, a[i]);}// 输出for(int i=0; i <= a_max; i++) for(int j=1; j<= count[i]; j++) cout<< i;该方法不仅可以排序,还可以去重,这是其他算法不具备的
该方法有很多优化。比如,这里有个很致命的问题,只能排正整数。对于负数和小数该怎么排序呢?这里留给大家思考和探索
5. 归并排序
思想:分治思想的典型应用,即按照分、解、合三个步骤的解决问题
分:将一个原问题分解成规模较小的子问题
解:问题规模足够小时,可以直接求解。如数组只有一个元素时,自然有序
合:将子问题的解,合并成原问题的解
对应到这里的排序问题,假设l,r,mid分别代表左、右、中
分:将数组a[l,r]分为两个更小的数组 a[l, mid]、a[mid, r]
解:l==r时,a[l, r]只要一个元素,自然是有序的
合:两个各自有序的数组,L和R,怎么合并成一个大的有序数组
显然,前两个步骤非常简单,因此归并归并排序的重点在归并。归并解决思路是,利用第三个暂存数组,将L和R中的元素依次填充进去,因此该算法需要额外空间,非原地排序。
从下图是一个长度为8的数组进行归并排序的过程,可以看到,分这一步产生的树深度为log2(8),即O(log(n))复杂度,而每次合并涉及的数量为2,4,8,即O(n)复杂度,因此总体上是O(nlogn)时间复杂度
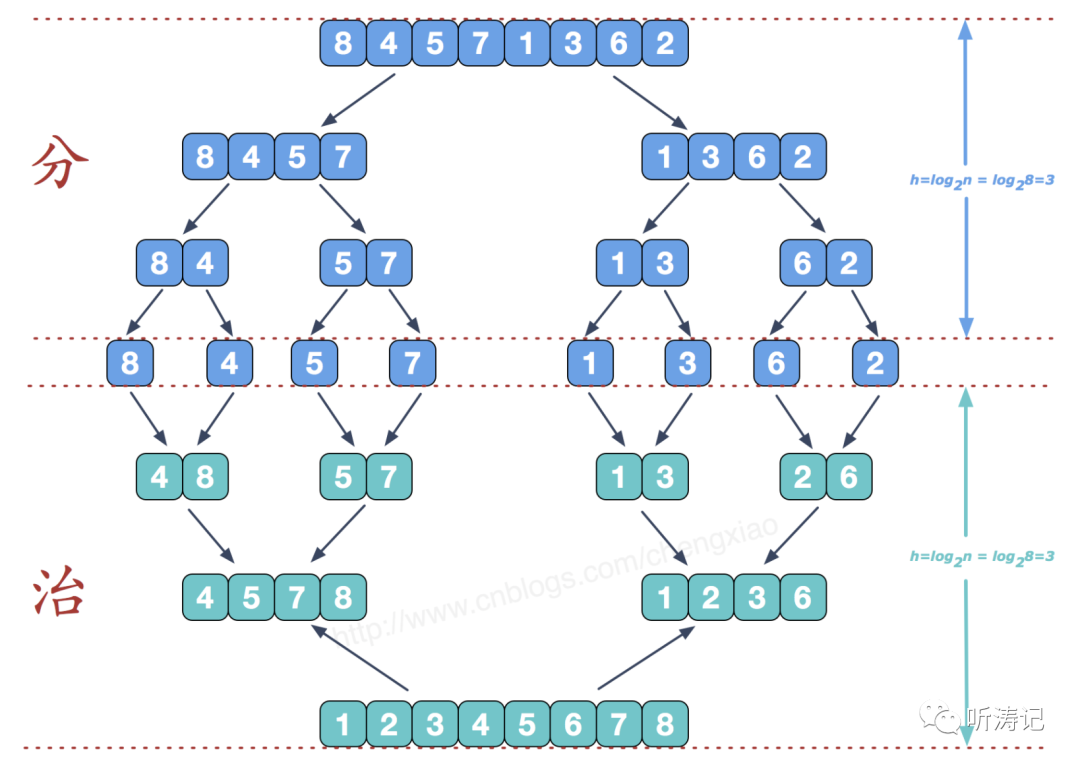
图片来源:博客园dreamcatcher-cx
时间复杂度:O(nlogn)
空间复杂度:O(n)

思考1:为什么归并排序能够比选择排序和冒泡排序快?
答案:这里涉及到一个逆序对的概念,如希望数组升序排列,如果ia[j],这就构成一个逆序对。如果数组有序,则逆序对总数就是0。因此,排序过程本质上就是一个消除逆序对的过程。
对于冒泡来说,每次交换,只消除了一个逆序对;而对于归并排序来说,一次动作可能消除多个逆序对
例如,下图中的2,在原数组中,与前面的3,5,9都构成了逆序对,但是当2放到暂存数组(图中红框)后,与之相关的逆序对便全部消失了,这是归并能够更快的根本原因
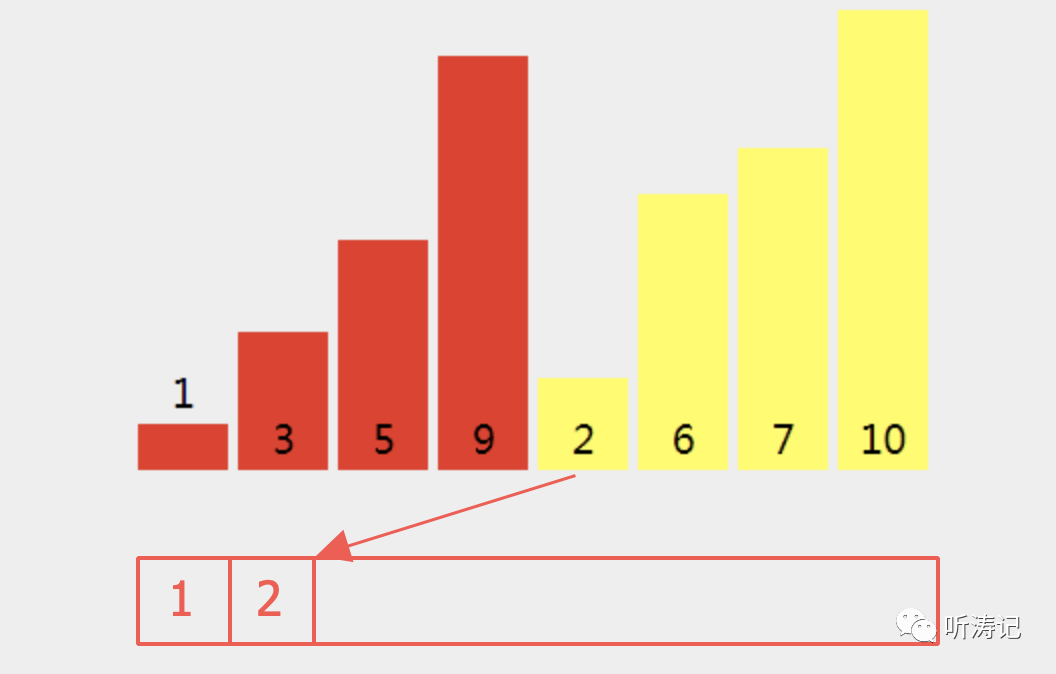
int a[n]; // 长度为n的原数组void Devide(int l, int r){ // 分 if(l>=r) return; // 解 int mid = (l+r)/2; // 未到边界,继续分 devide(l,mid); devide(mid+1,r); merge(l, r); // 合并}void Merge(int l, int r){ // 合 int mid = (l+r)/2; int temp[n]={0}; // 暂存数组 int i=l,j=mid; // 两个子数组的当前指针 for(int k = l; k <= r; k++){ // 填充temp数组 // 右边数组放完,或者左右都没放完,但左边当前值较小 if(j>r || i else temp[k]=a[i++]; } //此时a[l,r]依然无序,将数据从暂存数组放回原数组 for(int k = l; k <= r; k++) a[k]=temp[k]; }思考2:如果让你统计一个数组的逆序对数,怎么利用归并的思想来做呢?
答案:在merge函数里,从右子数组中放元素到temp数组中时,会使逆序对数减少。因此,只需加一行代码进行计数即可
for(int k = l; k <= r; k++){ // 填充temp数组// 右边数组放完,或者左右都没放完,但左边当前值较小 if(j>r || i cnt += mid - i + 1; // 记录此次消除的逆序对数 temp[k]=a[j++]; } else temp[k]=a[i++];}思考3:如果给你20亿个int类型的整数,但是内存只有2GB,怎么排序?
答案:一个int整数为4个字节,20个意味着需要8GB内存,显然电脑内存不够。可以将原数据分为4份,一份份地排序,然后再两两合并输出到硬盘
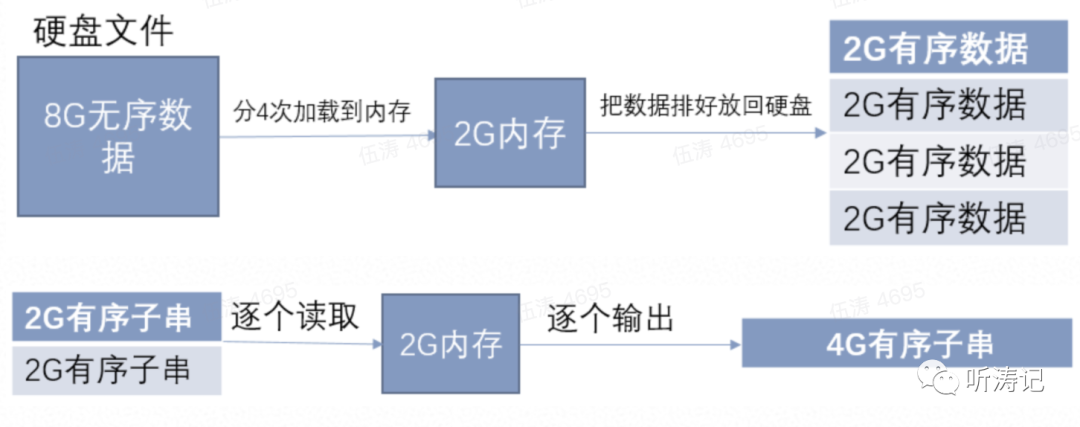
4个长度为2GB的有序子串,先两两归并成两个4GB有序子串,再归并成一个8GB有序子串。归并过程的细节如下:


因此上述过程中,有三次归并动作,意味着三次硬盘读写过程,虽然满足要求,但效率比较低
优化1:从二路归并,到n路归并
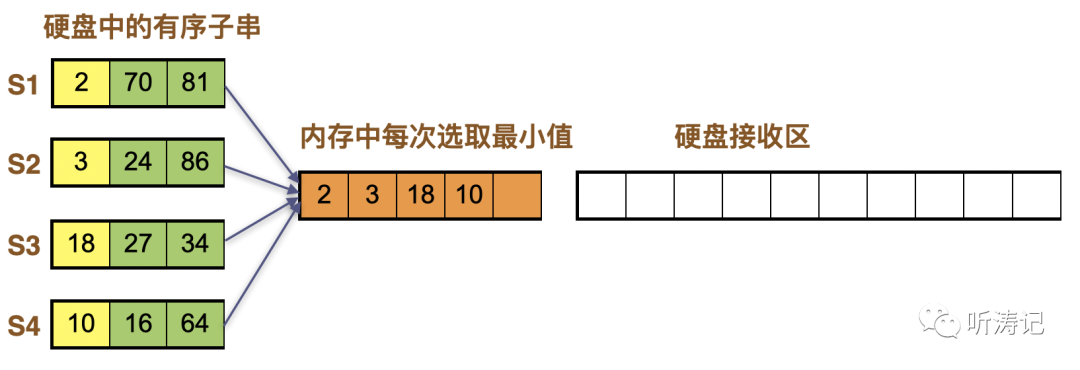
4个字串一起归并,内存里每次四个数取最小。如果n个子串同时一起归并,则内存中有n个数字。动画示意图如下:
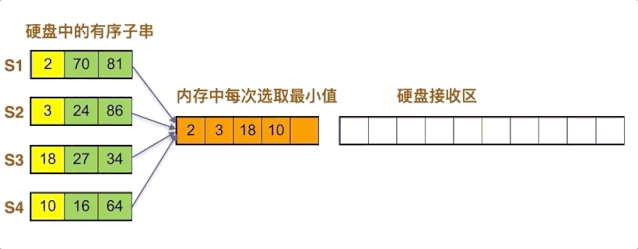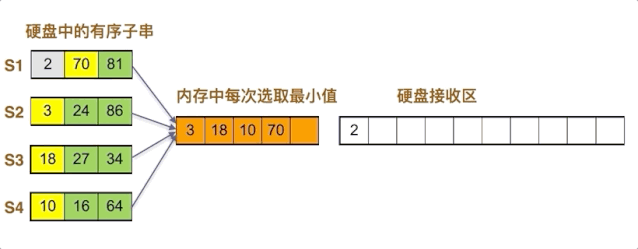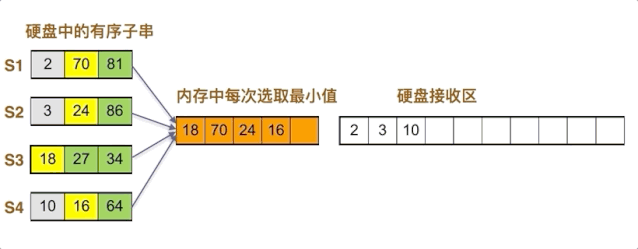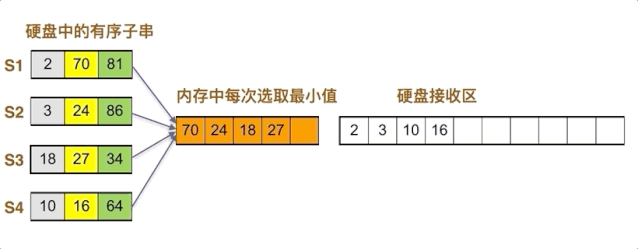
点击观看动画
图例解释如下:
首先将每个子串的第一个数写入内存,即2,3,18,10
内存中当前最小值为2,移入硬盘,2位于S1子串中,其后数字为70,补充入内存
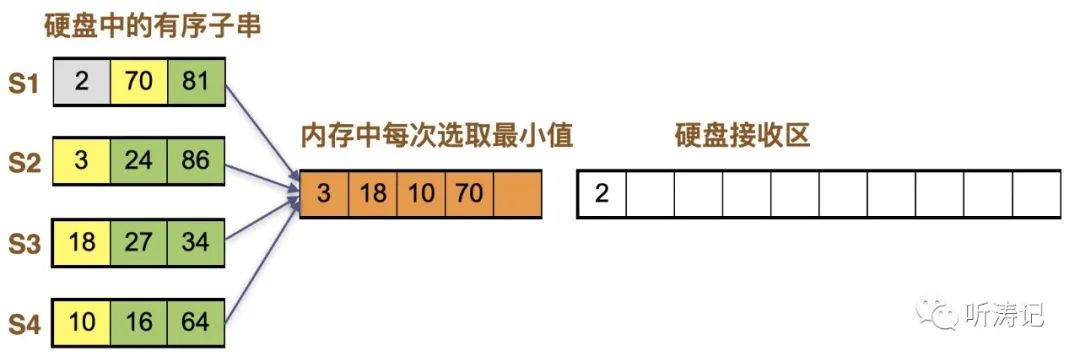
内存中当前最小值为3,移入硬盘,3位于S2子串中,其后数字为24,补充入内存

内存中当前最小值为10,移入硬盘,10位于S4子串中,其后数字为24,补充入内存

内存中当前最小值为16,移入硬盘,16位于S4子串中,其后数字为27,补充入内存

如此循环,直到四个子串全部放入归并
优化2: n是否越大越好?
n越大,硬盘读写次数就越少,但内存中的数字就越多,从中选取最小值的耗时也会增加。因此,n不是越大越好。因为每次内存只选取最小值,因此可以用堆来加速
这其实也是一道典型的面试题,给你n个有序数组,如何归并成一个有序数组?
如果没有内存限制,可以两两归并,直到最后只剩一个;如果有内存限制,可以利用堆排序来实现
优化3:减少有序子串数量
有序子串数量越少,n路归并的n就越小,那么内存选取最小值的耗时就越短。之前的做法是先用内存最大容量去装,再装下的数据在内存中进行排序,排好后再依次写入硬盘。这种做法意味着,子串最长为内存容量。
但内存其实只需要扮演好比较者这个角色即可,一种比较好的做法是,将原数据依次放入内存,每次取内存中的不小于当前要生成子串末尾数字的最小值,放入子串中。
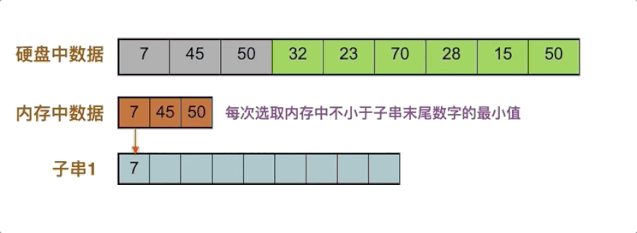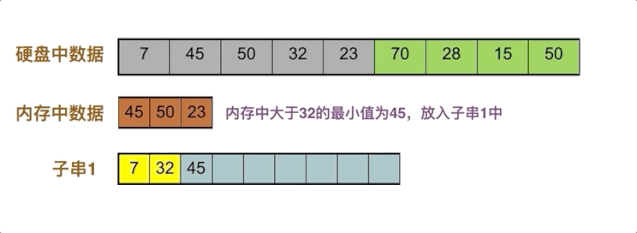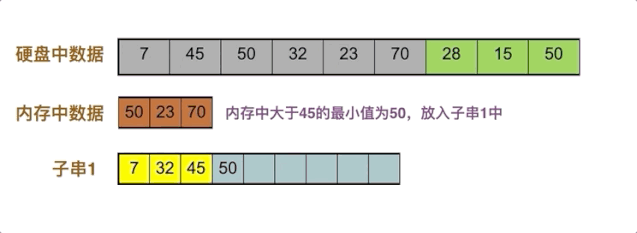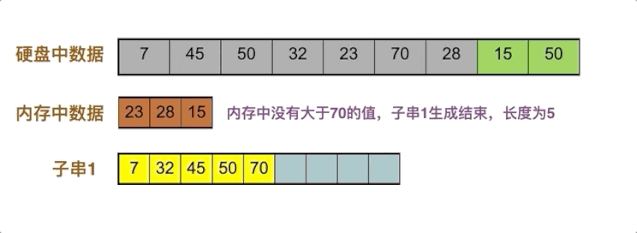
点击观看动画
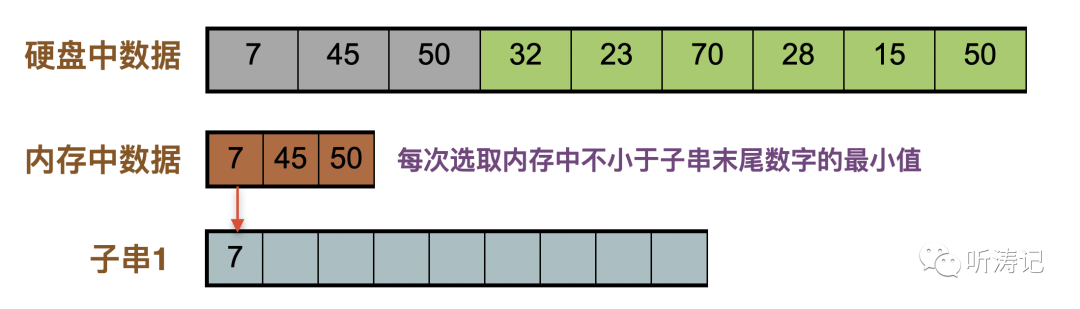
假设内存大小为3,首先取前三个数字放入内存,取内存中的最小值7放入子串
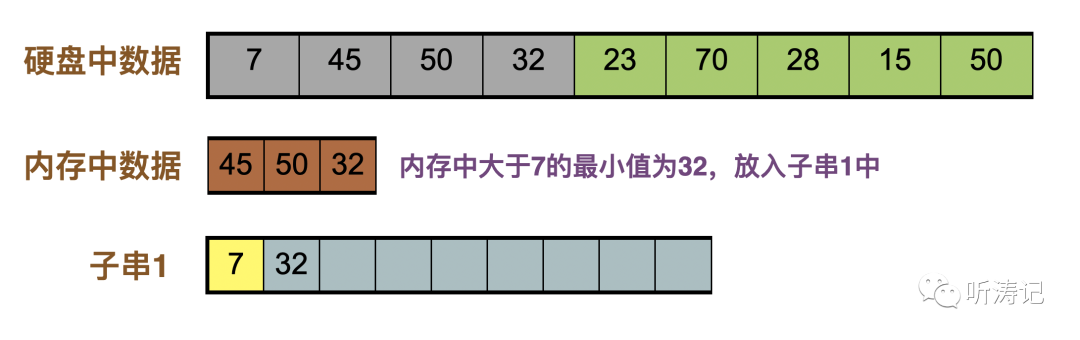
32补充进内存,内存中大于7的最小值是32,放入子串
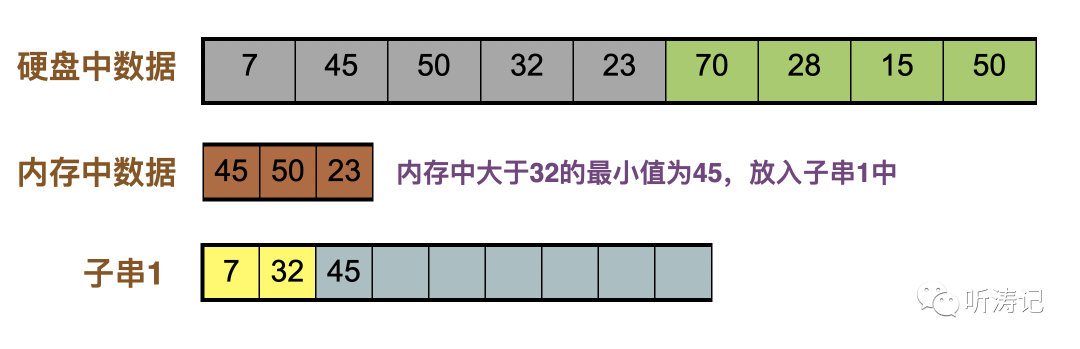
23补充进内存,内存中大于32的最小值是45,放入子串
70补充进内存,内存中大于45的最小值是50,放入子串
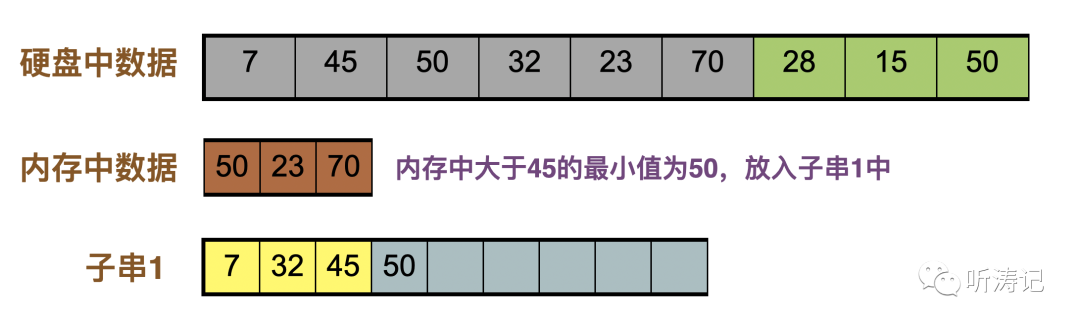
28补充进内存,内存中大于50的最小值是70,放入子串
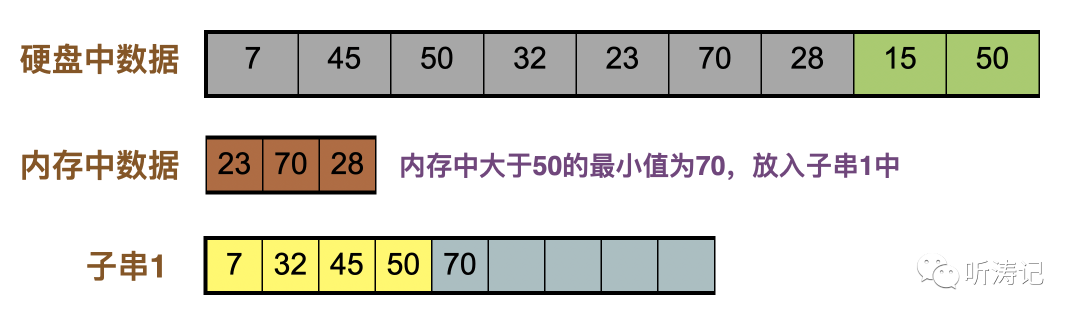
15补充进内存,内存中没有大于70的数字,子串1生成结束。我们得到了一个比内存长的多的子串。生成的子串长度越长,归并的子串数量就越少,意味着归并时硬盘的读写更少。
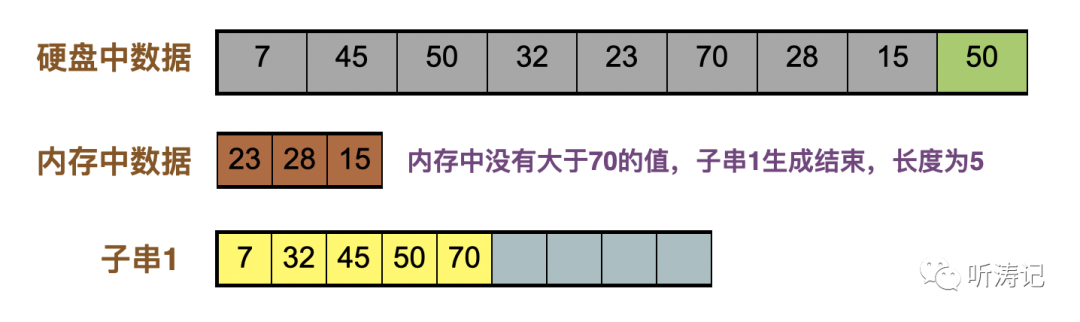
总结:对于这个问题,原型就是归并排序,但面试官可以问的非常深入,最佳方案描述如下:
利用优化3将原数据分成若干子串
对子串进行多路归并,并且在内存中维护一个最小堆
6. 快速排序
思想:也是基于分治思想,复杂度与归并排序一样,但为原地排序
分:根据某个元素x,将数组重排成两部分,左半部分都小于某元素x,另一部分都大于x,这样元素x的位置就排好了
解:左右两部分分别再进行排序
合:不用合并,因为此时数组已经完全有序
可以看到,快排的核心,是分这一步。对于当前a[L,R],划分依据的元素k一般取a[L],该元素也称为主元。具体实现方式为:分别从左右两端向中间扫描
从左向右的指针i:从a[L+1]开始,跳过所有小于x的元素,直到遇到一个大于x的数a[i]
从右向左的指针j:从a[R]开始,跳过所有大于x的元素,直到遇到一个小于x的数a[j]
将a[i]与a[j]交换,i,j 继续向中间扫描,直到相遇
点击观看视频演示
int Devide(int L, int R) { int i=L+1,j=R,x=a[L]; while(1){ while(a[i] while(a[j]>x && j>=L) j--; if(i>=j) break; swap(a[i],a[j]); i++;j--; } swap(a[L],a[j]); return j; //返回分界位置,以便继续向下划分}int QuickSort(int l, int r){ if(l>=r) return; // 解 int m = devide(l, r); // 分 QuickSort(l,m-1); QuickSort(m+1,r);}该方法又称为双路快排,即使用两个指针由两边向中间扫描。对于含有重复元素的case,可以使用三路快排,大家可以自行探索,这也是面试官比较喜欢问的
但在极端情况下,例如初始数组为倒序,快速排序的复杂度会退化到O(n^2),即每次都只能划分出一个数,
思考:根据快排原理,如何O(n)复杂度寻找数组中第k大的数字?
答案:假设数组下标从1开始,devide(l,r)返回的m即为第m大元素。与k进行比较,若m>k,则只对左边进行递归;若m
时间复杂度 = n + n/2 + n/4 + ... + 1 = O(2n)7. 总结
 下期预告:动态规划
下期预告:动态规划
全文完,如有帮助,请点在看❤️
















 754
754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









