








BERT 可能是目前最强的NLP模型
1. BERT简介
2. transformer
3. BERT架构与训练
4. BERT model的使用
5. BERT demo with pytorch
6. 总结
1. BERT简介
1.1 简介
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的encoder,于2018年由Google[^1]提出,获得了计算语言学协会(NAACL)北美分会2019年年度会议最佳长篇论文奖[^2],在11个NLP任务上的表现刷新了记录,是目前在NLP领域最火热,也可能是最好用的模型。
1.2 BERT特点
关于BERT的特点有非常多,但是我这里想说的是BERT的核心特点。
1.2.1提取特征
众所周知,在今天的CV领域,大家在处理具体的分类任务时,可以用一些训练好的model(如ResNet或更潮的EfficientNet)来充分提取图片的特征(feature),然后利用这些模型提取到的feature接上一个分类器(如一千维到两维的线性分类器),只训练后面分类器的部分,就可以很快完成任务。
在NLP领域,我们也希望有这样的model,来充分提取语言的特征,使其便于拼接一些其他网络结构来完成各种语言文本的分类预测等问题。类似的提取特征的模型还有ELMO,而BERT可能是目前最好用的此类模型。并且一些工作已经证明,在视频序列等cv领域,也有很好的表现。
1.2.2 无监督学习
NLP领域与CV领域的一个不同是,语料丰富,但是标注的语料很少,标注困难,因此如果可以无监督的进行训练,会使得模型更能充分训练。而BERT就是可以利用无需标注的语料来训练。这也是它的性能能如此优秀的原因。
1.2.3. 速度和长序列
RNN因为依赖与上层的输出,使得训练速度慢,同时语料过长,则不能进行很好的训练。而BERT可以并行计算,这使得他的速度大大提高,并且可以处理长序列的问题。
1.3 BERT 用途
常规的NLP任务,如文本分类,文本聚类,语言翻译,问答系统,文本特征提取等,BERT都可以胜任,而且BERT还具有一些新的功能,比如google利用BERT来自动地通过新闻资讯生成一个词条的维基百科。
接下来,就让我们开启BERT学习之旅吧!!!
2. Transformer
2.1 简介
想了解BERT,我们首先要熟悉Transformer,也就是那篇鼎鼎有名的文章Attention Is All You Need[^3]。这里需要注意的时,在这篇论文之前已经Attention(注意力机制)已经广泛应用于NLP领域,主要是与RNN结合来处理问题。而这篇论文正如题目所说(你只需要Attention),完全抛弃了RNN,只使用Attention机制,使得NLP的处理可以并行计算,大大加快了模型的训练和计算速度,并且表现非常好,成为NLP领域的新思路。
2.2 self-attention 架构
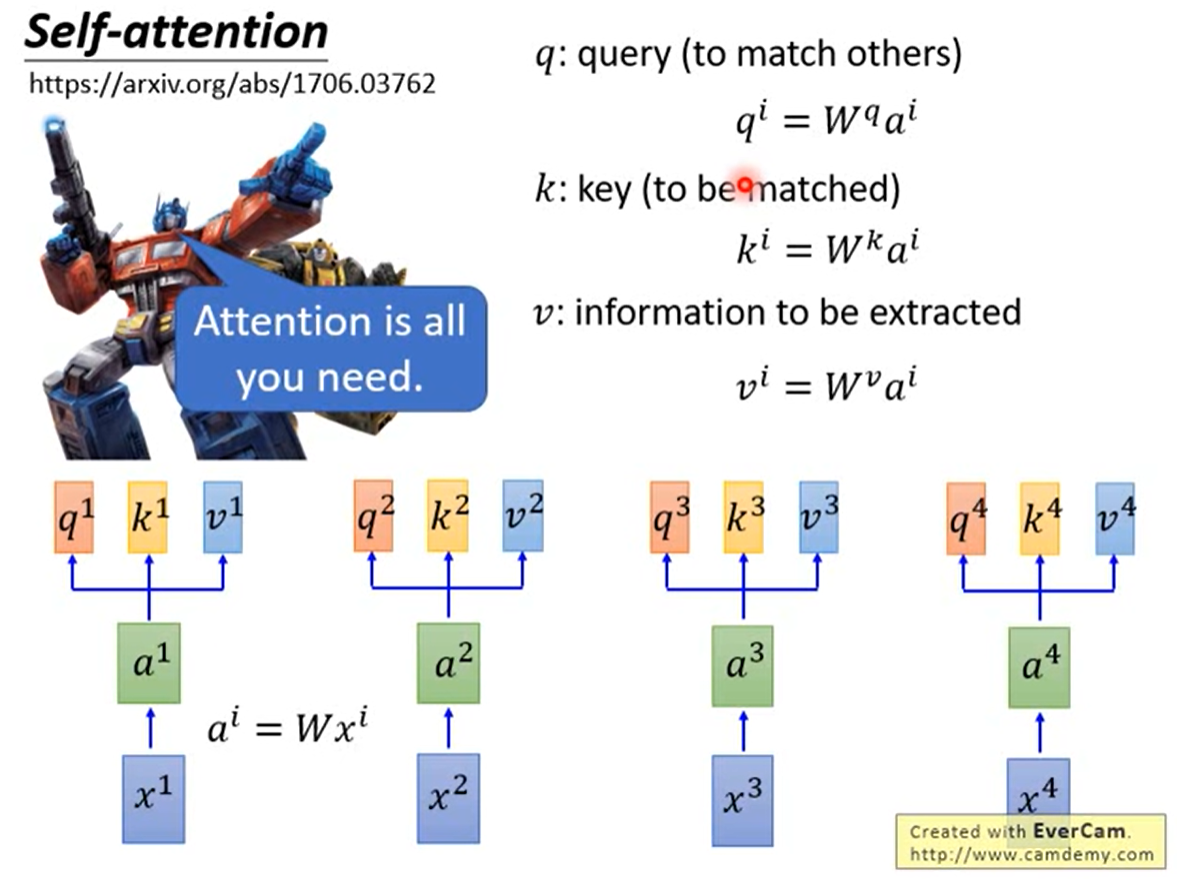
上图(图源自李宏毅老师youtube关于transformer的讲解课件,非常建议去看[^4])给出了架构的第一层。
我们首先需要确定的是我们需要的时找到序列之间的关系信息,使其具有RNN的特点,同时保证序列的运算可以并行化,这是目的,架构是为了这个目的而服务的。
首先transformer通过三个矩阵
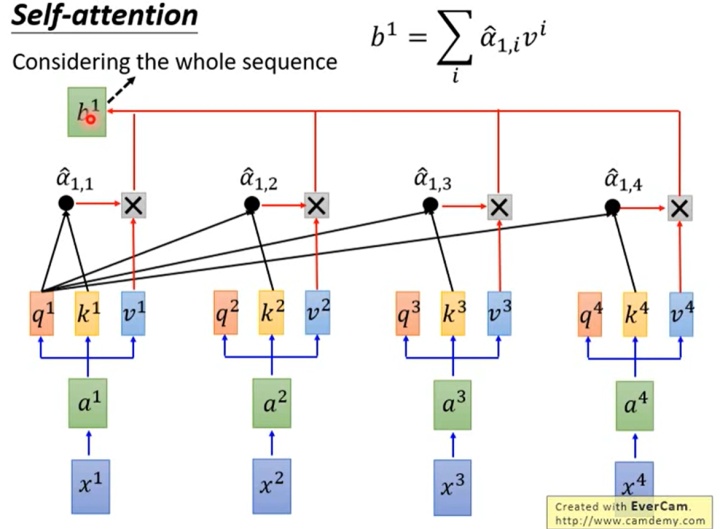
在得到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2573
2573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









