





文章目录
前言
欢迎来到我们的圈子
小爬虫踢到钢板了
任务需求
需求分析
1.
2.
3.
方案一:
方案二:
数据类型
正则表达式
什么是正则表达式?
基础语法
普通字符
演示
限定符
定位符
选择
python正则表达式
解决问题
前言
前期回顾:你要偷偷学Python(第九天)
依旧是这段啊
本系列文默认各位有一定的C或C++基础,因为我是学了点C++的皮毛之后入手的Python。
本系列文默认各位会百度,学习‘模块’这个模块的话,还是建议大家有自己的编辑器和编译器的,上一篇已经给大家做了推荐啦?
然后呢,本系列的目录嘛,说实话我个人比较倾向于那两本 Primer Plus,所以就跟着它们的目录结构吧。
本系列也会着重培养各位的自主动手能力,毕竟我不可能把所有知识点都给你讲到,所以自己解决需求的能力就尤为重要,所以我在文中埋得坑请不要把它们看成坑,那是我留给你们的锻炼机会,请各显神通,自行解决。
1234567
今天干嘛呢?是不是以为我要写小饼干了?非也非也,前天踢到钢板了,爬下来一堆乱码,请教了一下前辈,用正则表达式。
很多时候吧,并不是你能力不行,就是因为你没那个见地,没那个眼界而已。
所以要多向不同领域的,见多识广的学长学姐、老师、长辈们请教。
所以,这里还是要说一下我们这个学习群啊。

欢迎来到我们的圈子
如果大家在学习中遇到困难,想找一个python学习交流环境,可以加入我们的python圈,裙号947618024,可领取python学习资料,会节约很多时间,减少很多遇到的难题。
小爬虫踢到钢板了
事情的经过是这样的,昨天我的小爬虫可怜兮兮的爬回来,看样子是受委屈了。那我怎么能忍呐?那必须一顿操作猛如虎啊,于是我就去看到底是何方神圣。
任务需求
爬取林志炫的歌词,哪首歌?你跟我说哪首?这点小事自己决定就好了。
需求分析
1.
首先就判断肯定不可能给你从网页上直接抓下来的,于是我们打开network。为什么不可能?那肯定是我失败过了嘛。
2.
有两个页面能拿歌词,
一个是还没放歌的页面:https://y.qq.com/n/yqq/song/001PGGQ81Xxw9l.html
另一个是歌词播放的页面:https://y.qq.com/portal/player.html
第二个页面经过尝试,效果不如第一个页面,可以抓一下当做练习。
于是我们选用第一个页面:
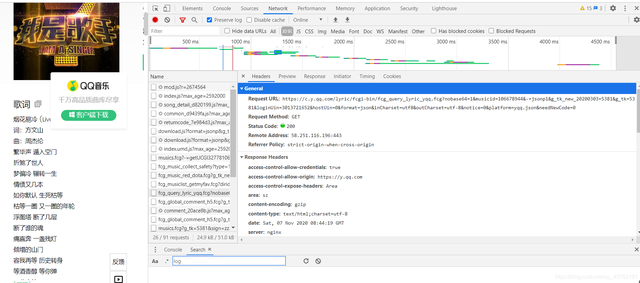
3.
此处跳过一波查找操作,具体见《第九天》
直接上结果:
import requests
import json
from bs4 import BeautifulSoup
headers = {
'origin':'https://y.qq.com',
# 请求来源,本案例中其实是不需要加这个参数的,只是为了演示
'referer':'https://y.qq.com/n/yqq/song/004Z8Ihr0JIu5s.html',
# 请求来源,携带的信息比“origin”更丰富,本案例中其实是不需要加这个参数的,只是为了演示
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
# 标记了请求从什么设备,什么浏览器上发出
}
# 伪装请求头
#url = 'https://y.qq.com/n/yqq/song/001PGGQ81Xxw9l.html'
url = 'https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg?nobase64=1&musicid=106678944&-=jsonp1&g_tk_new_20200303=5381&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'
res_song = requests.get(url,headers = headers)
# 方案一
soup = BeautifulSoup(res_song.text,'html.parser')
print(soup)
#方案二
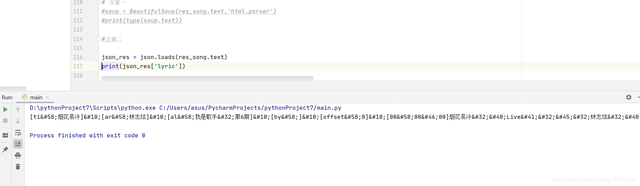
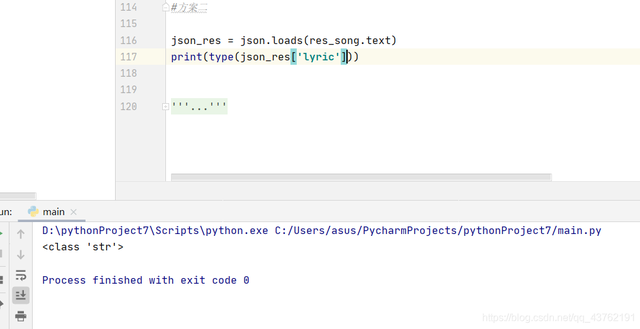
# json_res = json.loads(res_song.text)
# print(json_res['lyric'])
1234567891011121314151617181920212223242526
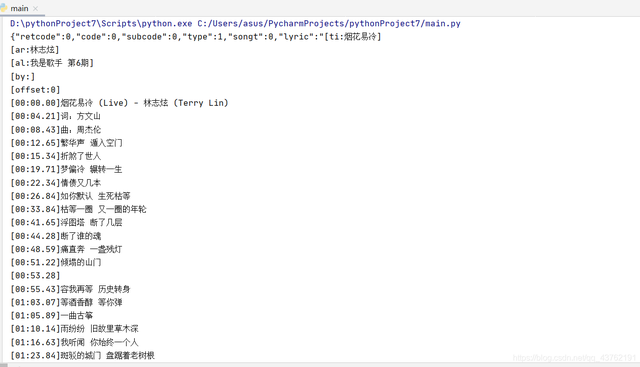
好极,我们来看一下这两个方案会有什么结果:
方案一:
方案二:
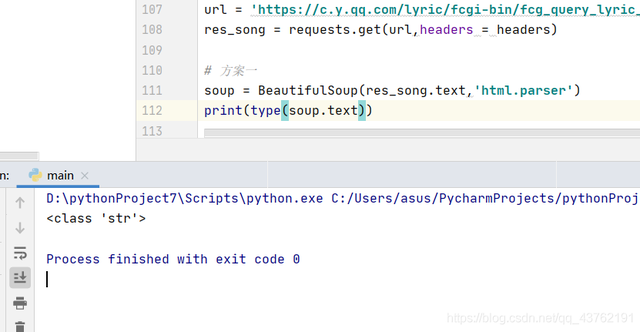
那怎么办?好在这俩玩意儿都能当字符串处理,那就,正则吧。
数据类型
正则表达式
好,接下来我们来看正则表达式。
什么是正则表达式?
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
基础语法
普通字符
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
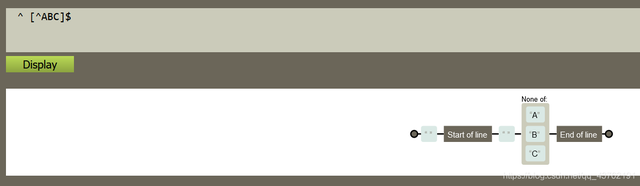
字符释义[ABC]匹配 […] 中的所有字符,例如 [aeiou] 匹配字符串 “google runoob taobao” 中所有的 e o u a 字母。[^ABC]匹配除了 […] 中字符的所有字符,例如 [^aeiou] 匹配字符串 “google runoob taobao” 中除了 e o u a 字母的所有字母。[A-Z][A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。.匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。[\s\S]匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,包括换行。\w匹配字母、数字、下划线。等价于 [A-Za-z0-9_]
演示





限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
正则表达式的限定符有:
限定符表达式*匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。+匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。?匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 、 “does” 中的 “does” 、 “doxy” 中的 “do” 。? 等价于 {0,1}。{n}n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。{n,}n 是一个非负整数。至少匹配n 次。例如,‘o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o*’。{n,m}m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。






定位符
定位符使您能够将正则表达式固定到行首或行尾。它们还使您能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
定位符用来描述字符串或单词的边界,^ 和 $ 分别指字符串的开始与结束,\b 描述单词的前或后边界,\B 表示非单词边界。
正则表达式的定位符有:
字符描述^匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。$匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。\b匹配一个单词边界,即字与空格间的位置。\B非单词边界匹配。
注意:不能将限定符与定位符一起使用。由于在紧靠换行或者单词边界的前面或后面不能有一个以上位置,因此不允许诸如 ^* 之类的表达式。
若要匹配一行文本开始处的文本,请在正则表达式的开始使用 ^ 字符。不要将 ^ 的这种用法与中括号表达式内的用法混淆。
若要匹配一行文本的结束处的文本,请在正则表达式的结束处使用 $ 字符。
选择
用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔。
python正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
传送门
回头再练练吧,还不是很熟练。。。
解决问题
今天脑壳疼,就直接放代码吧,还有点瑕疵,比方说那个:‘词’ 和填词人名字应该用:分隔,‘曲’也是这样。
import re
import requests
from bs4 import BeautifulSoup
headers = {
'origin':'https://y.qq.com',
# 请求来源,本案例中其实是不需要加这个参数的,只是为了演示
'referer':'https://y.qq.com/n/yqq/song/004Z8Ihr0JIu5s.html',
# 请求来源,携带的信息比“origin”更丰富,本案例中其实是不需要加这个参数的,只是为了演示
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
# 标记了请求从什么设备,什么浏览器上发出
}
# 伪装请求头
url = 'https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg?nobase64=1&musicid=106678944&-=jsonp1&g_tk_new_20200303=5381&g_tk=5381&loginUin=0&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0'
res_song = requests.get(url,headers = headers)
# 方案一
soup = BeautifulSoup(res_song.text,'html.parser')
#print(soup.text)
pat=re.compile(r'[\u4e00-\u9fa5]+')
result=pat.findall(soup.text)
result = '\n'.join(result[5:])
print(result)
最后多说一句,想学习Python可联系小编,这里有我自己整理的整套python学习资料和路线,想要这些资料的都可以进q裙947618024领取。
本文章素材来源于网络,如有侵权请联系删除。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









