






我们先看看百度百科对聚集索引的定义:

天呐,这是什么??
新技术人被英语差、技术又菜的前辈的可怕翻译迫害,想想都是一件可怕的事。
我们看个正常的定义:
A clustered index is a special type of index that reorders the way records in the table are physically stored. Therefore table can have only one clustered index. The leaf nodes of a clustered index contain the data pages.
A nonclustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on disk. The leaf node of a nonclustered index does not consist of the data pages. Instead, the leaf nodes contain index rows.
其实很简单,我们的sql数据库是行数据库,数据是一行一行存储的,而聚集索引是个特殊的索引,相当于这一行行记录的物理编号,描述这一行行数据的物理存储顺序。所以,一张表只会有一个聚集索引。
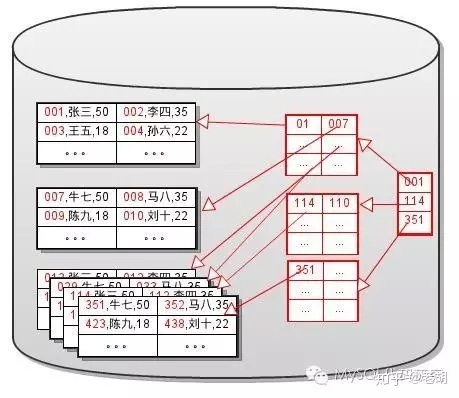
如图,聚集索引的叶子节点指向的就是实际数据页,两个相邻的聚集索引1和2,它们指向数据块上的位置——张三和李四,也得给我住两隔壁。
拿mysql来说,聚集索引通常是表的主键,若无主键则为表中第一个非空的唯一索引,还是没有就采用innodb存储引擎为每行数据内置的ROWID作为聚集索引。
再来,不是聚集索引的就是非聚集索引,两个相邻排排站的非聚集索引,它们实际指向的数据可能隔了十万八千里。天呐,其实它就是二级索引啊。
举个例子吧:
create table people (
`id` INT UNSIGNED AUTO_INCREMENT,
`name` VARCHAR(20),
PRIMARY KEY(`id`),
KEY(`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;该表主键id就是该表的聚集索引,name就是非聚集索引;表中每行数据都是按id排序存储的;
比如要查找名字是'Aa'和'Ab'这两个人,他们在name索引表中的位置可能是相邻的,但实际的存储位置则不然。
通过name索引最终只能查出数据的主键,然后再按主键捞出来。















 1621
1621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









