






原标题:逆向工程 | C 语言之 if-else 分支
460500587
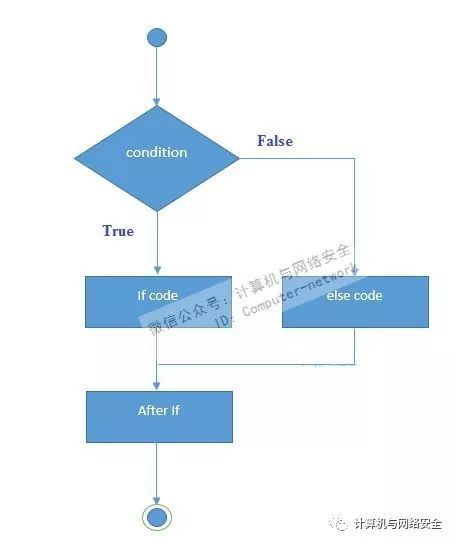
if-else分支几乎是所有学习的人首先要接触的知识点之一,那么学习理所当然从这里开始了。
在学习的时候,始终要记住我们是在与编译器打交道,大致将if-else分支的分为4种状态。
一、以常量为判断条件的简单if-else分支
我们先来看一个例子,如代码清单1所示。

代码清单1 简单的if-else
先以Debug方式编译生成,用OllyDbg打开后找到main()函数,看到的汇编代码如下:

通过以上代码可知,if-else分支用的都是反比(例如JLE 00411A64这类指令),按照我们的代码逻辑这些地方应该使用JAE(大于等于0)才对。其实编译器这么做是有其道理的,因为我们以Debug方式生成代码肯定是要注重可读性、健壮性的。但是除此之外还有一点也非常重要,那就是汇编代码与高级语言代码的对应性。我们可以想想,按照C/C++的语言描述来看,肯定是显示"Hello world!"的这个分支在上面的,但是如果按照我们的逻辑使用JAE指令,那么这个分支很显然就要在下面了。
通过总结我们可以知道,Debug版的if-else分支特征如下:

接下来我们再看看Release版是什么样的。

没有删减任何代码,但是通过上面的代码可知,确实有代码被剪掉了。这正是Release版的强大之处,更确切地说应该是编译优化的强大之处。由于编译器在编译前进行扫描时检测到了if语句后面的判断条件是一个常量,编译器在编译时就剪掉了那个永远不可达的分支,并且去掉了判断,因此这个if-else分支的执行结果肯定是不会发生变化的。
看到这里也许有的朋友会感到迷惑,我们如何才能将原来的代码还原出来呢?答案是:还原不出来。Release版编译出来的程序是不能还原出与原来完全相同的源代码的,只能还原出功能相同的代码。
二、以变量为判断条件的简单if-else分支
以Debug方式编译后汇编代码如代码清单2所示。

代码清单2 以变量为判断条件的简单if-else分支
上述代码基本上与前面的版本无异,现在我们再看看Release版。

Release版为每一个分支后面都添加上了结束代码,难道这不会使程序的体积增加吗?
首先编译器这样做其实仅增加了一个字节的体积,其次这些细节行为都是由编译选项决定的,Release版的默认选项采取的是速度优先,因此编译器在权衡之后,认为牺牲一个字节的体积换取减少一个跳转指令还是非常划算的。
由以上特点我们可以总结出Release版的简单if-else分支特征如下:

三、以常量为判断条件的复杂if-else分支
在大多数的情况下我们还会碰到一些复杂的if-else分支,如代码清单3所示。

代码清单3 以常量为判断条件的复杂if-else分支
以上代码的Release版的汇编代码如下:

从Release版生成的代码上看来,与上一个例子没有太大区别,不可达的分支都由编译器在编译初期给剪掉了。唯一不同的地方就是本例中调用函数的方法比较特别,先将其保存在寄存器中,然后在使用时直接调用寄存器即可。一般在多次重复调用某个函数时会出现这样的优化方案。
四、以变量为判断条件的复杂if-else分支
如果if-else分支的条件判断不是常量,那么编译器就无法对某些分支进行裁剪了。但是事实真的是这样吗?先看代码清单4。

代码清单4 以变量为判断条件的复杂if-else分支
再看Release版的反汇编代码。

通过上面的反汇编代码我们不难发现,虽然两个打印"Hello!"的代码还在,但是打印"Hello everybody!"的代码只剩一处了,可见编译器将重复的分支合并了。图1简单明了地说明这种优化。
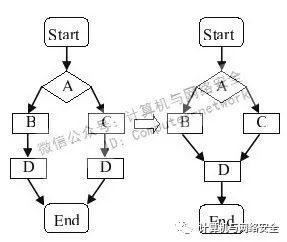
图1 if-else分支的合并优化
编译器很聪明地将两个相同的D流程合并为一个了,这样做无疑大大减少了编译器生成代码的体积,但是同时这也是初学的朋友最难理解的地方。有的朋友可能还未看出它的难点在哪里,因此在这里提醒一下,如果你不知道编译器有这种优化方案,那么在需要将此段代码转为C代码时,应该怎么做呢?用goto吗?仔细想想,虽然用goto可以达到还原出“等价高级语言”的效果,但是这并不是我们想要的。最起码,goto转为指令毫无疑问就是jmp了,但是上述反代码中并没有jmp。所以本着认真求实的态度,我们一定要记住,这是编译器的一种优化结果。
五、识别三目运算符
不知您是否还记得初学C语言时接触三目运算符的那种感觉?相信每个人在学习三目运算符时或多或少都会有一些奇妙的或不寻常的感觉。当时在学完三目运算符时感觉它很有魅力,因此在学完后就开始不停地幻想各种三目运算符的应用场景。
我们都知道三目运算符的本质就是if-else。但是真是如此吗?下面让我们一探究竟。
1、有序常量的三目运算
所谓有序常量的三目运算是指其常量是有章可循的,具体如代码清单5所示。

代码清单5 有序常量的三目运算
下面是它的反汇编代码:

这看起来似乎并不易懂,首先对于setne这个指令有可能会让一部分汇编不扎实的朋友困惑,其次那个add eax,2也显得不一般,它们的意义何在呢?
通过阅读源码可知,程序最后的返回结果只能有两种,即2与3,而setne指令则会根据ZF位的影响来决定是给al(也可以理解为eax)赋1还是0。当然,这要取决于上面的比较结果。
其实分析到这里已经很清晰了:如果比较相等,则eax的值会被置为0,加上2之后正好返回2;而如果不等的话自然就会返回3了。看到这里相信很多朋友会对编译器作者有了新的认识。
但是这似乎并不算什么,为了更好地证明,让我们再看一个更复杂一些的例子,如代码清单6所示。

代码清单6 稍复杂的有序常量的三目运算
下面是它的反汇编代码:

看懂上一个例子的朋友会很容易看懂这个例子,由于这个三目运算只可能等于6或8,因此,编译器使用了一个lea指令对其进行了一个稍显复杂的加法运算。如果条件为假,那么eax里的值为0,执行完lea指令后的最终结果为6;如果条件为真,那么eax里的值为1,执行完lea指令后的最终结果为8。
有序常量的三目运算的特征如下:

2、无序常量的三目运算
无序常量的三目运算一般是比较多见,如代码清单7所示。

代码清单7 无序常量的三目运算
它的反汇编代码如下:

这是一段比较“绕”的代码,而且是一环套一环的,最终的结果取决于与0x3E做与运算的是什么值,而这个值又取决于CF位是否为1,并且其参数是否相等还影响着CF位的状态为何。但是这看似复杂的流程其实是有规律可循的,以下就是总结出来的公式。
逻辑公式,具体如下:
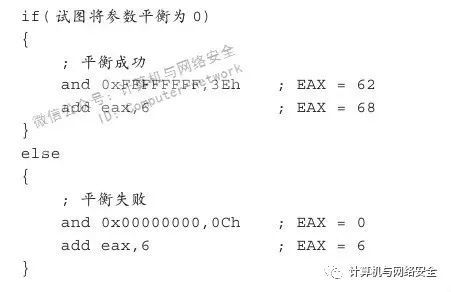
数学公式,具体如下:

如果变量为1的话,那么代入公式后结果如下:

如果变量为2012的话,那么代入公式后结果如下:
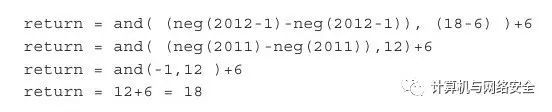
由此可知,即便是结果再复杂,编译器总能找到某种组合来应对,足见编译器作者用心良苦。
无序常量的三目运算特征如下:

3、值为变量的三目运算
现在我们再来看一种返回值为变量的三目运算的例子,如代码清单8所示。

代码清单8 值为变量的三目运算
上述代码的反汇编代码如下:
虽然上述代码与典型的if-else分支有些相似,但还是可以发现不同之处的:其中一个分支无论如何都会被执行,如果je未执行则分支一的执行结果会被分支二覆盖,这样我们得到的值仍然是正确的。
编译器之所以这样做是因为,每执行一次寄存器赋值操作要比偶尔一次的流程转移操作更加高效,所需付出的代价更小。对于这个推论并不十分赞同,但是如果我们不能找出一个更有利的例子证明它是错的,那么就只能接受这种行为了。返回搜狐,查看更多
责任编辑:















 27万+
27万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









