






编者按:训练集/测试集划分和交叉验证一直是数据科学和数据分析中的两个相当重要的概念,它们也是防止模型过拟合的常用工具。为了更好地掌握它们,在这篇文章中,我们会以统计模型为例,先从理论角度简要介绍相关术语,然后给出一个Python实现的案例。
什么是模型过拟合/欠拟合
在统计学和机器学习中,通常我们会把数据分成两个子集:训练数据和测试数据(有时也分为训练、验证、测试三个),然后用训练集训练模型,用测试集检验模型的学习效果。但当我们这么做时,模型可能会出现以下两种情况:一是模型过度拟合数据,二是模型不能很好地拟合数据。常言道过犹不及,这两种情况都是我们要极力规避的,因为它们会影响模型的预测性能——预测准确率较低,或是泛化性太差,没法把学到的经验推广到其他数据上(也就是没法预测其他数据)。
过拟合
模型过拟合意味着我们把模型“训练得太好了”,通过一遍又一遍的训练,它已经把训练数据的特征都“死记硬背”了下来。这在模型过于复杂(和观察样本数相比,模型设置的特征/变量太多)时往往更容易发生。过拟合的缺点是模型只对训练数据非常准确,但在未经训练的数据或全新数据上非常不准确,因为它不是泛化的,没法推广结果,对其他数据作出任何推断。
更确切地说,过拟合的模型学习到的只是训练数据中的“噪声”,而不是数据中变量之间的实际关系。显然,这些“噪声”是训练数据独有的,这也决定了它不能准确预测任何新数据集。
欠拟合
和过拟合相比,欠拟合是另一个极端,它意味着模型连拟合训练数据都做不到,没能真正把握数据的趋势。毫无疑问,一个欠拟合的模型也是不能被推广到新数据的,它和过拟合恰恰相反,是模型过于简单(没有足够的预测变量/自变量)的结果。例如,当我们用线性模型(比如线性回归)拟合非线性数据时,模型就很可能会欠拟合。
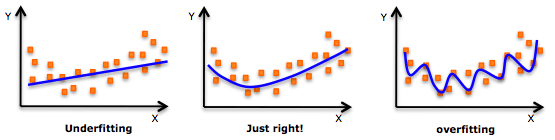
欠拟合、恰到好处和过拟合
值得注意的是,在实践中,欠拟合远不像过拟合那么普遍。但我们还是要做到在数据分析中同时警惕这两个问题,找到它们的中间地带。而解决问题的首选方案就是划分训练/测试数据和交叉验证。
划分训练/测试数据
正如之前提到的,我们使用的数据通常会被划分为训练集和测试集。其中训练集包含输入的对应已知输出,通过在上面进行训练,模型可以把学到的特征关系推广到其他数据上,而测试集就是模型性能的试金石。

那么在Python中,我们能怎么执行这个操作呢?这里我们介绍一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1482
1482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









