





背景
在爬虫的过程中,我们需要很准确的定位到页面元素的位置。
定位元素最简单的方法就是通过xpath和css。本文主要介绍xpath相关的笔记。
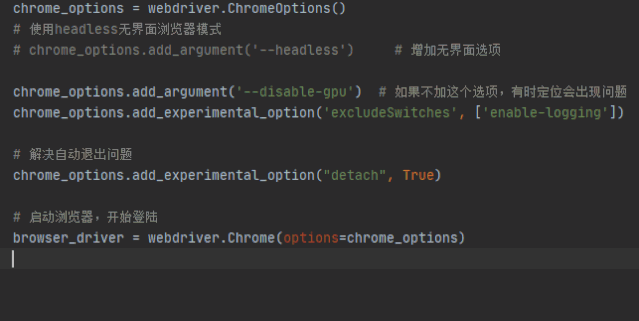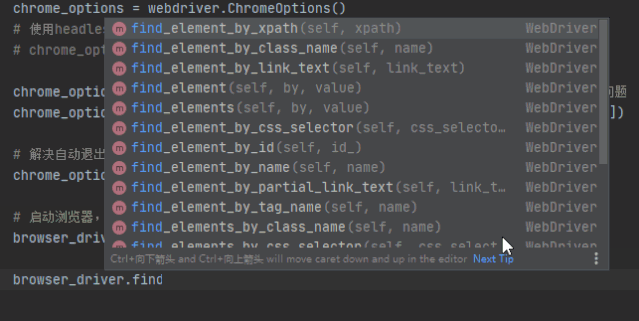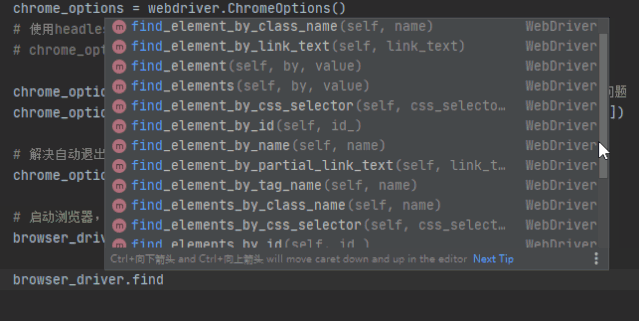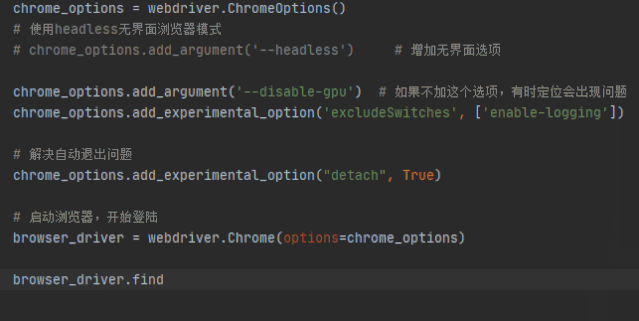
比如用selnium的时候,可以这样
xpath 简介
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
以上的信息如何决定晦涩难懂,那本文推荐一个xpath的利器xpath helper
xpath helper介绍
这里摘取一下,官方介绍
XPath Helper makes it easy to extract, edit, and evaluate XPath queries on any webpage.
xpath helper使从页面获取信息更简单了
xpath helper是chrome的一个插件,如果要使用这个工具,必须使用chrome浏览器。
安装
如果能够访问google应用商店,直接在chrome地址栏输入https://chrome.google.com/webstore/detail/xpath-helper/hgimnogjllphhhkhlmebbmlgjoejdpjl?hl=zh_CN
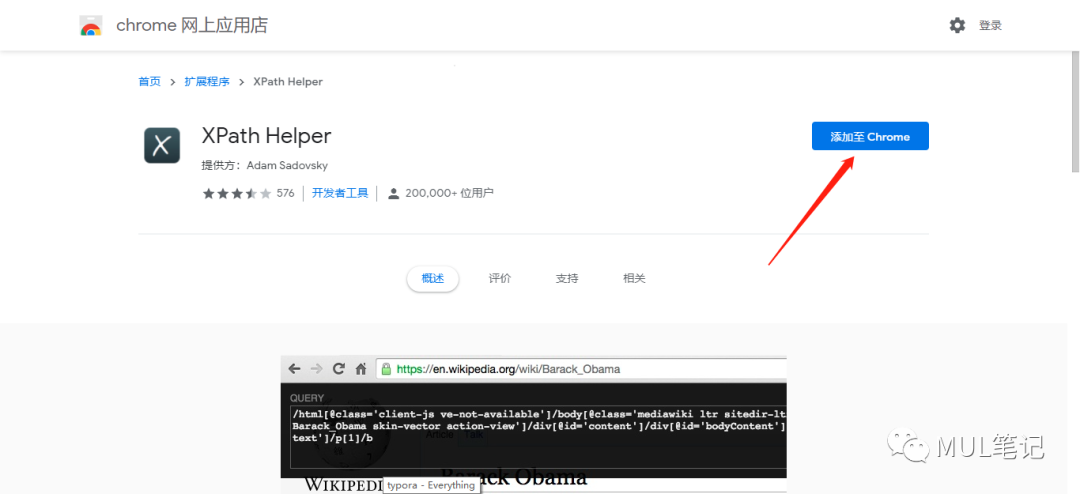
点击添加到chrome就可以了。
- 离线安装
- 如果不能访问google,就需要将这个插件下载下来,下载之后试一下ctx格式的文件,直接用rar工具将其解压到一个文件夹。
- 在浏览器输入
chrome://extensions/,右上角切换打开开发者模式。选择“加载已解压的的扩展程序”,选择刚刚解压的文件夹即可

使用
安装完成之后,就可以使用了。
打开/关闭 在windows下使用快捷键:Ctrl+Shift+X ,打开xpath窗口

获取页面元素 打开窗口之后,鼠标移动到具体的位置,按住shit键即可
如何使用xpath 这里以selenium + chrome为例
比如拿到百度搜索页面,搜索案例的xpath是
'wrapper']/div[@id=那么我们在selenium下可以这样定位到这个元素,并调用比如click方法,模拟点击。
"/html/body/div[@id='wrapper']/div[@id='head']/div[@id='head_wrapper']/div[@class='s_form s_form_nologin']/div[@class='s_form_wrapper soutu-env-nomac soutu-env-index']/form[@id='form']/span[@class='bg s_btn_wr']/input[@id='su']").click()通过浏览器获取xpath
现在的浏览器大部分都是chrome内核,都提供了开发者工具(浏览器页面打开F12),里面可以看到页面元素以及请求的地址。同时也提供如xpath的定位方法。同样以chrome浏览器为例
首先F12开发者工具,然后选到element,在根据层级,找到需要元素的位置,比如这里找“百度一下”,鼠标选中之后,页面上会跟着变化选择的区域。找到之后,直接右键copy,选择xpath也可以。
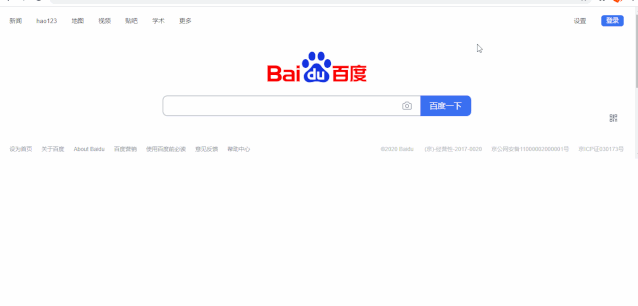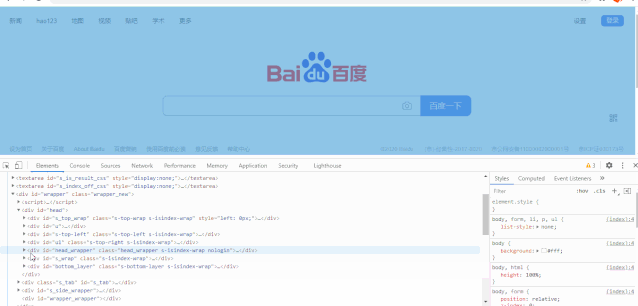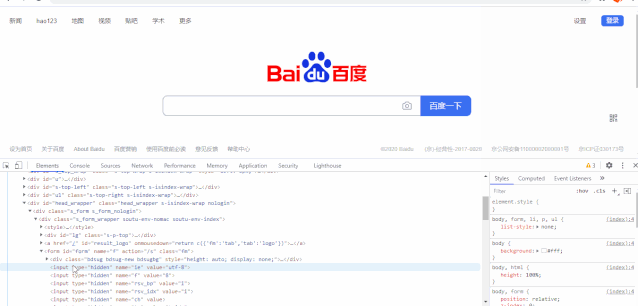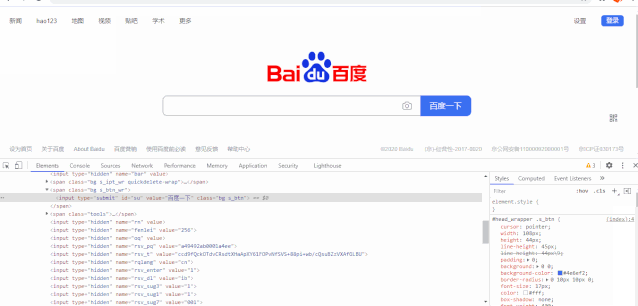
通过xpath helper和浏览器获取到xpath的区别:xpath是从第一个














 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









