






一、窗口函数
1、窗口函数的函义和作用
窗口函数也称为OLAP函数,可以对数据库数据进行实时分析处理;可以处理如下问题:
- 排名问题:每个部门按业绩来排名
- topN问题:找出每个部门排名前N的员工进行奖励
2、窗口函数的语法结构
<分析函数> over(PARTITION BY 列名 ORDER BY 列名 rows BETWEEN 开始位置 AND 结束位置)- PARTITION BY 分区
- ORDER BY 排序
- rows BETWEEN 开始位置 AND 结束位置 指定窗口范围
在使用over()窗口函数时,over()函数中的这三个函数可组合使用也可以不使用。
① ORDER BY
在窗口中排序
② PARTITION BY
可理解为 GROUP BY分组,over(PARTITION BY 列名)搭配分析函数时,分析函数按照每一组每一组的数据进行计算。
group by分组汇总后改变了表的行数,一行只有一个类别。而partiition by和rank函数不会减少原表中的行数。
③ rows BETWEEN 开始位置 AND 结束位置
是指定窗口范围,比如第一行到当前行。而这个范围是随着数据变化的。over(rows BETWEEN 开始位置 AND 结束位置)搭配分析函数时,分析函数按照这个范围进行计算。
我们尝试用的窗口范围是ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行),常用该窗口来计算累加。
3、常与over()一起使用的分析函数:
①聚合类
AVG()、SUM()、MAX()、MIN()
② 排名类
- row_number()按照值排序时产生一个自增编号,不会重复(如:1、2、3、4、5、6)
- rank()按照值排序时产生一个自增编号,值相等时会重复,会产生空位(如:1、2、3、3、3、6)
- dense_rank()按照值排序时产生一个自增编号,值相等时会重复,不会产生空位(如:1、2、3、3、3、4)
③其他类
- lag(列名,往前的函数,[行数为null时的默认值,不指定则为null]),可以计算用户上次购买时间。
- lead(列名,往后的行数,[行数为null时的默认值,不指定则为null]),可以计算用户下次购买时间。
- ntile(n)把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,ntile返回慈航所属组的编号
4、练习
①对表中每个班级的成绩进行排名
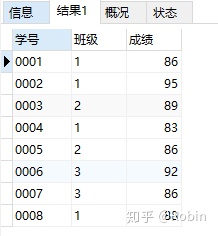
SELECT *,
dense_rank() over(PARTITION BY 班级 ORDER BY 成绩 DESC) ranking
FROM 班级表;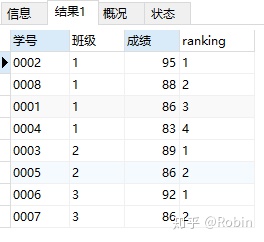
②从表中查找出每个学生最高的2个科目
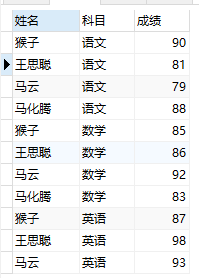
SELECT * FROM(
SELECT *,row_number() over(PARTITION BY 姓名 ORDER BY 成绩 DESC) ranking
FROM score2
) a
WHERE a.ranking<=2;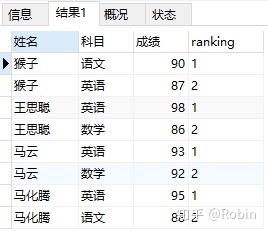
③查找单科成绩高于该科目平均成绩的学生名单
SELECT * FROM(
SELECT *,AVG(成绩) over(PARTITION BY 科目) 平均成绩
FROM score2) a
WHERE a.成绩>a.平均成绩;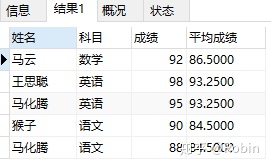
④计算从第一天到现在的所有score大于80分的用户总数(累积)
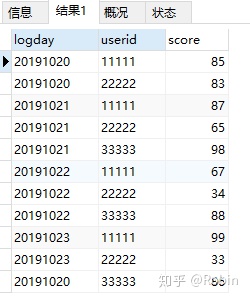
SELECT *,COUNT(userid) over(ORDER BY logday rows BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) total
FROM test_windows
WHERE score>80;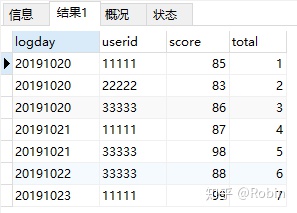
二、存储过程
含义:一组预先编译好的SQL语句的集合,理解成批处理语句
- 提高代码的重用性
- 简化操作
- 减少了编译次数并且减少了和数据库服务器的连接次数,提高了效率
1、创建语法
CREATE PROCEDURE 存储过程名(参数列表)
BEGIN
存储过程体(一组合法的SQL语句)
END注意:
①参数列表包含三部分:
参数模式、参数名、参数类型
举例:
IN stuname VARCHAR(20)
参数模式:
- IN:该参数可以作为输入,也就是该参数需要调用方传入值
- OUT:该参数可以作为输出,也就是该参数可以作为返回值
- INOUT:该参数既可以作为输入又可以作为输出,也就是该参数既需要传入值,与可以返回值
②如果存储过程体仅仅只有一句话, BEGIN END可以省略
存储过程提中的每条SQL语句的解为要求必须加分号,存储过程的解为可以使用DELIMITER重新设置
语法:
DELIMITER 结束标记(例如:DELIMITER $)
- 无参数的存储过程:
DELIMITER $
CREATE PROCEDURE 存储过程名称()
BEGIN
<sql语句>;
END $- 有参数的存储过程:
DELIMITER $
CREATE PROCEDURE 存储过程名称(IN/OUT/INOUT 参数名 参数类型)
BEGIN
<sql语句>;
END $2、调用语法
CALL 存储过程名(实参列表);3、删除存储过程
DROP PROCEDURE 存储过程名;4、查看存储过程的信息
SHOW CREATE PROCEDURE myp1;5、练习:
①无参数的存储过程:向课程列表中插入新课程“计算机”
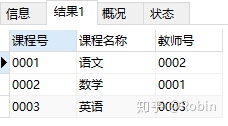
DELIMITER $
CREATE PROCEDURE insert_course()
BEGIN
INSERT INTO course
VALUES('0004','计算机','0004');
END $
CALL insert_course $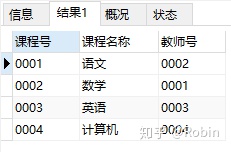
②有参数的存储过程:输入学生的学号,返回学生的姓名
DELIMITER $
CREATE PROCEDURE get_name(IN id VARCHAR(20),OUT `name` VARCHAR(20))
BEGIN
SELECT s.姓名 INTO `name`
FROM student s
WHERE s.学号=id;
END $
CALL get_name('0002',@name) $
SELECT @name $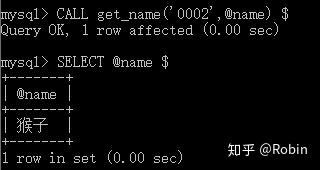














 3509
3509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









