






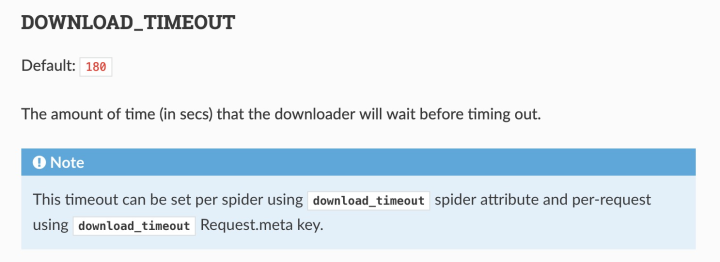
在scrapy我们可以设置一些参数,如DOWNLOAD_TIMEOUT,一般我会设置为10,意思是请求下载时间最大是10秒,文档介绍
如果下载超时会抛出一个错误,比如说
def start_requests(self):
yield scrapy.Request('https://www.baidu.com/', meta={'download_timeout': 0.1})日志设为DEBUG级别,重试设为3次,运行之后的日志
2019-05-23 19:38:01 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://www.baidu.com/> (failed 1 times): User timeout caused connection failure: Getting https://www.baidu.com/ took longer than 0.1 seconds..
2019-05-23 19:38:01 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://www.baidu.com/> (failed 2 times): User timeout caused connection failure: Getting https://www.baidu.com/ took longer than 0.1 seconds..
2019-05-23 19:38:01 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://www.baidu.com/> (failed 3 times): User timeout caused connection failure: Getting https://www.baidu.com/ took longer than 0.1 seconds..
2019-05-23 19:38:01 [scrapy.downloadermiddlewares.retry] DEBUG: Gave up retrying <GET https://www.baidu.com/> (failed 4 times): User timeout caused connection failure.
2019-05-23 19:38:01 [scrapy.core.scraper] ERROR: Error downloading <GET https://www.baidu.com/>
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/scrapy/core/downloader/middleware.py", line 43, in process_request
defer.returnValue((yield download_func(request=request,spider=spider)))
twisted.internet.error.TimeoutError: User timeout caused connection failure.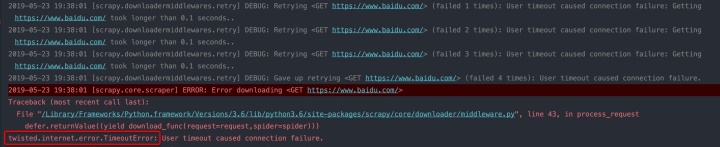
可以看到重试三次之后,抛出异常。今天讲的就是如何处理这个异常,也就是scrapy的errback。
重新改写下代码
def start_requests(self):
yield scrapy.Request('https://www.baidu.com/', meta={'download_timeout': 0.1},
errback=self.errback, callback=self.parse)
def errback(self, failure):
self.logger.error(repr(failure))使用errback必须要有callback函数,日志输出
2019-05-23 19:46:20 [51bushou_shop] ERROR: <twisted.python.failure.Failure twisted.internet.error.TimeoutError: User timeout caused connection failure: Getting https://www.baidu.com/ took longer than 0.1 seconds..>官方的例子
import scrapy
from scrapy.spidermiddlewares.httperror import HttpError
from twisted.internet.error import DNSLookupError
from twisted.internet.error import TimeoutError, TCPTimedOutError
class ErrbackSpider(scrapy.Spider):
name = "errback_example"
start_urls = [
"http://www.httpbin.org/", # HTTP 200 expected
"http://www.httpbin.org/status/404", # Not found error
"http://www.httpbin.org/status/500", # server issue
"http://www.httpbin.org:12345/", # non-responding host, timeout expected
"http://www.httphttpbinbin.org/", # DNS error expected
]
def start_requests(self):
for u in self.start_urls:
yield scrapy.Request(u, callback=self.parse_httpbin,
errback=self.errback_httpbin,
dont_filter=True)
def parse_httpbin(self, response):
self.logger.info('Got successful response from {}'.format(response.url))
# do something useful here...
def errback_httpbin(self, failure):
# log all failures
self.logger.error(repr(failure))
# in case you want to do something special for some errors,
# you may need the failure's type:
if failure.check(HttpError):
# these exceptions come from HttpError spider middleware
# you can get the non-200 response
response = failure.value.response
self.logger.error('HttpError on %s', response.url)
elif failure.check(DNSLookupError):
# this is the original request
request = failure.request
self.logger.error('DNSLookupError on %s', request.url)
elif failure.check(TimeoutError, TCPTimedOutError):
request = failure.request
self.logger.error('TimeoutError on %s', request.url)failure.request就是我们创建的Request对象,如果需要重试,直接yield即可
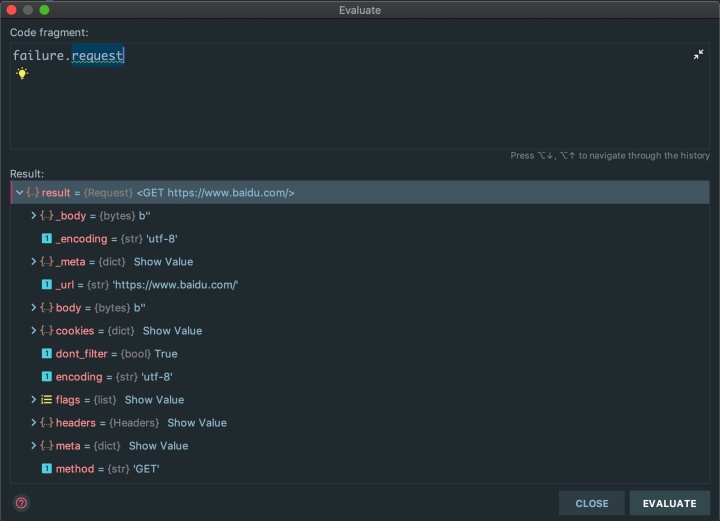
errback函数能捕获的scrapy错误有:连接建立超时,DNS错误等。也就是日志中类似
twisted.internet.error.TimeoutError: User timeout caused connection failure.源代码位置:error.py















 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









