






对于explore-first和epsilon-greedy算法,他们都存在一个缺陷,那就是没有根据历史信息去调整探索时间。一般而言,根据观察到的reward去调整exploration时间会使算法的regret降低。本部分将介绍两种自适应exploration的算法。
算法1:消除算法
首先考虑K=2的特殊情况。对于这种情况一种很自然的想法就是当我们知道一个arm远远优于另一个arm时,我们将抛弃那个较差的arm,而去重复选择那个较好的arm。
那么定义一个arm远远优于另一个arm的标准是什么?这个就是我们接下来需要讨论的问题了。假定
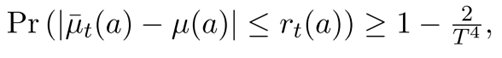
其中,
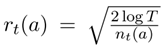
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5389
5389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









