





这篇文章将引导我们使用TensorRec(https://github.com/jfkirk/tensorrec)在Python中建立一个新的推荐系统原型,包括输入数据操作,算法设计和预测用法。
系统总览
TensorRec是一个用于构建推荐系统的Python包。TensorRec推荐系统使用三个输入数据:用户特征,项目特征和interactions。根据用户/项目特征,系统将预测要推荐的项目。在拟合模型时使用interactions:将预测与interactions进行比较,计算损失/惩罚,系统学习减少损失/惩罚。
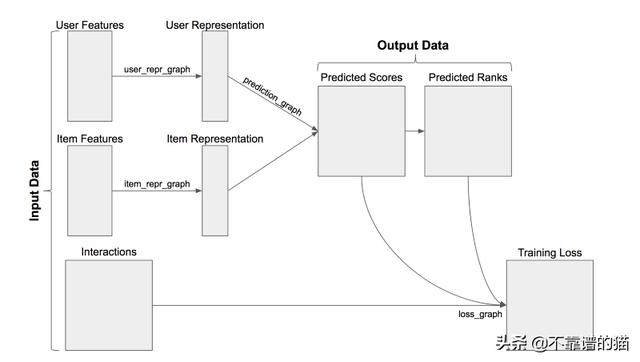
在我们对系统进行原型设计时,我们将解决三个主要问题:我们如何处理interactions,如何处理特征以及如何构建推荐器本身。
导入Python库
from collections import defaultdictimport csvimport numpyimport randomfrom scipy import sparsefrom sklearn.preprocessing import MultiLabelBinarizerimport tensorrecimport logginglogging.getLogger().setLevel(logging.INFO)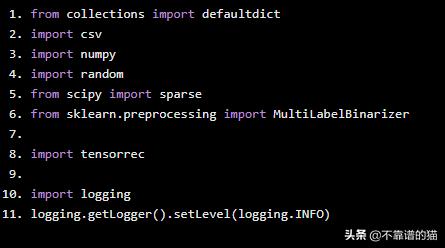
Interaction数据
对于此示例,我们将使用MovieLens数据集(https://grouplens.org/datasets/movielens/)。此数据集包含电影的1-5星评级,有关这些电影的元数据以及用户应用于电影的标签。对于我们的第一个原型,我们将专注于评级,但我们稍后将返回其他元数据。
评级看起来像这样:
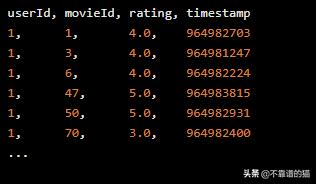
每行代表一个评级:一个用户对一部电影的想法。我们将使用这些评级作为我们的interactions。我们训练该系统的第一步是摄取和格式化这种交互数据。首先,我们在CSV文件中读取评级。Python代码如下:
# Open and read in the ratings fileprint('Loading ratings')with open('ratings.csv', 'r') as ratings_file: ratings_file_reader = csv.reader(ratings_file) raw_ratings = list(ratings_file_reader) raw_ratings_header = raw_ratings.pop(0)# Iterate through the input to map MovieLens IDs to new internal IDs# The new internal IDs will be created by the defaultdict on insertionmovielens_to_internal_user_ids = defaultdict(lambda: len(movielens_to_internal_user_ids))movielens_to_internal_item_ids = defaultdict(lambda: len(movielens_to_internal_item_ids))for row in raw_ratings: row[0] = movielens_to_internal_user_ids[int(row[0])] row[1] = movielens_to_internal_item_ids[int(row[1])] row[2] = float(row[2])n_users = len(movielens_to_internal_user_ids)n_items = len(movielens_to_internal_item_ids)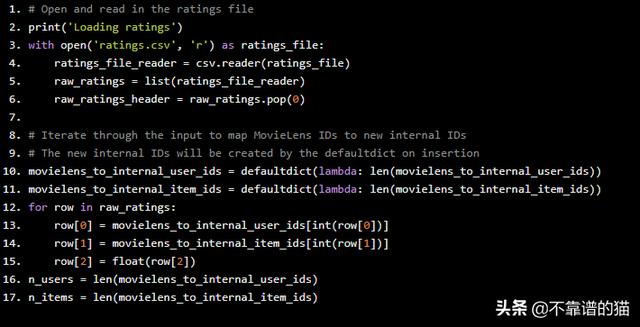
我们将通过shuffling 和拆分评级来将评级分解为一个训练和测试集。我们的原型将在训练集上进行训练,我们将使用测试集来评估它们的成功程度。像这样随机拆分训练/测试是粗糙的,还有更严格的模型评估技术,但是对于本示例的目的来说是快速和清晰的。
# Shuffle the ratings and split them in to train/test sets 80%/20%random.shuffle(raw_ratings) # Shuffles the list in-placecutoff = int(.8 * len(raw_ratings))train_ratings = raw_ratings[:cutoff]test_ratings = raw_ratings[cutoff:]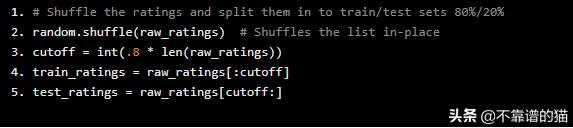
接下来,我们将这些评级重新组织为Scipy稀疏矩阵。在此矩阵中,每一行代表一个用户,每一列都是一部电影。此矩阵中的[ i,j ]值是User i与Movie j的interaction。
# This method converts a list of (user, item, rating, time) to a sparse matrixdef interactions_list_to_sparse_matrix(interactions): users_column, items_column, ratings_column, _ = zip(*interactions) return sparse.coo_matrix((ratings_column, (users_column, items_column)), shape=(n_users, n_items))# Create sparse matrices of interaction datasparse_train_ratings = interactions_list_to_sparse_matrix(train_ratings)sparse_test_ratings = interactions_list_to_sparse_matrix(test_ratings)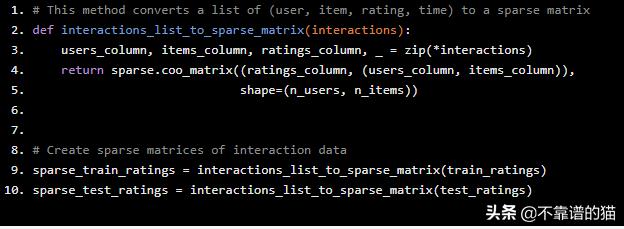
协同过滤器原型
协同过滤是一种算法,它可以了解哪些用户有相似的品味,并根据相似用户的喜好向用户推荐商品。一种常见的方法是通过矩阵分解。在矩阵分解中,我们必须学习两个矩阵(用户表示和项目表示),当它们相乘时,近似于interactions:
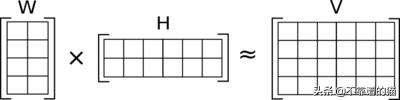
在这种情况下,W的行是用户表示,H的列是项目表示,V中的值是interactions。需要学习W和H以产生V的最佳近似值。
W的宽度和H的高度是相同的 - 这个共享的尺寸被称为“number of components”。具有更多components的模型将学习更复杂的用户和项目表示,但这可能导致过度拟合训练数据。一般来说,我们希望尝试将大量信息压缩到小的表示中。出于这个原因,在我们的原型中,我任意选择使用5个components。在进一步进行原型设计时,我们应该尝试增加和减少components的数量,并警惕过度拟合。
在默认情况下,TensorRec将执行矩阵分解,如果它只作为用户/项目特征给出单位矩阵。这些单位矩阵通常被称为“指标特征”。
# Construct indicator features for users and itemsuser_indicator_features = sparse.identity(n_users)item_indicator_features = sparse.identity(n_items)# Build a matrix factorization collaborative filter modelcf_model = tensorrec.TensorRec(n_components=5)# Fit the collaborative filter modelprint("Training collaborative filter")cf_model.fit(interactions=sparse_train_ratings, user_features=user_indicator_features, item_features=item_indicator_features)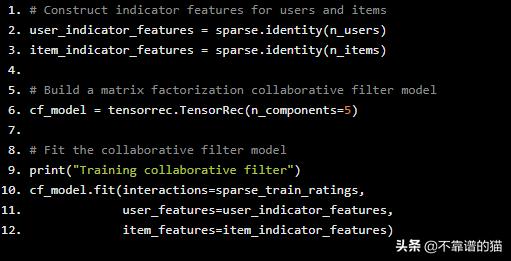
我们现在已经创建了两个指标特征矩阵,用5个components构建了一个简单的协同过滤模型,并对模型进行了拟合!
接下来,我们希望看到该模型的表现如何。
为了做到这一点,我们来看看一个叫做"recall at K"的指标。用Recall @ K表示,对于普通用户,他们的测试项目中有多少百分比在预测的排名中进入了前K。换句话说,如果我们得到recall@10值为.06,那么我喜欢的特定电影将有6%的可能性进入我的前10个推荐。
Recall@K是许多推荐系统的一个很好的度量标准,因为它模拟了推荐产品的行为:如果一个电影网站只会显示我的前10条推荐,那么他们的算法将会有效地将我喜欢的电影放入前10条推荐中。
在计算Recall回之前,我们要决定哪些interactions应该算作“like”。在本例中,我选择使用所有评分至少为4.0的评分作为“likes”,而忽略其他评分。
# Create sets of train/test interactions that are only ratings >= 4.0sparse_train_ratings_4plus = sparse_train_ratings.multiply(sparse_train_ratings >= 4.0)sparse_test_ratings_4plus = sparse_test_ratings.multiply(sparse_test_ratings >= 4.0)# This method consumes item ranks for each user and prints out recall@10 train/test metricsdef check_results(ranks): train_recall_at_10 = tensorrec.eval.recall_at_k( test_interactions=sparse_train_ratings_4plus, predicted_ranks=ranks, k=10 ).mean() test_recall_at_10 = tensorrec.eval.recall_at_k( test_interactions=sparse_test_ratings_4plus, predicted_ranks=ranks, k=10 ).mean() print("Recall at 10: Train: {:.4f} Test: {:.4f}".format(train_recall_at_10, test_recall_at_10))# Check the results of the MF CF modelprint("Matrix factorization collaborative filter:")predicted_ranks = cf_model.predict_rank(user_features=user_indicator_features, item_features=item_indicator_features)check_results(predicted_ranks)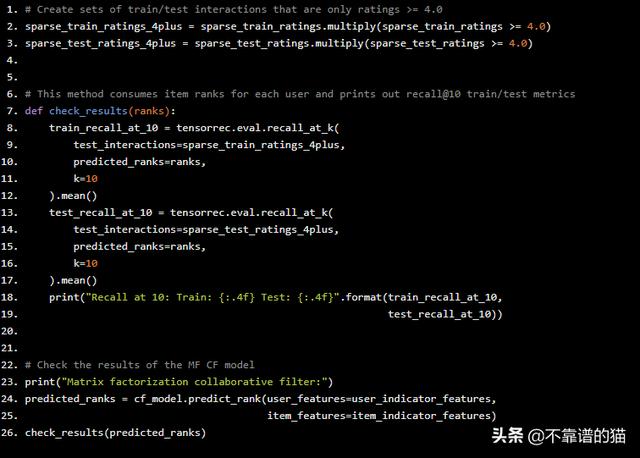
我们来看看结果:

…不是很好。这些结果告诉我们,在测试集电影中,只有0.1%的机会让喜欢的电影进入前10名。这个推荐系统无效,我们想要寻找改进的方法它。
损失图(Loss Graphs)
我们可以配置TensorRec系统的一种方法是更改损失图。损失图接受预测和interactions,并计算系统在学习时将尝试减少的惩罚(损失)。
默认情况下,TensorRec使用RMSE(均方根误差)作为损失图。这意味着TensorRec正试图准确估计interactions的值:如果我评价电影4.5,TensorRec正试图产生恰好4.5的预测得分。
这是很直观的,但它不符合许多产品中的推荐系统的工作方式:电影网站不需要准确地预测我的评级,它只需要能够将我喜欢的电影排在我不喜欢的电影之前。因此,许多系统通过“学习排名”来运作。“我们可以使用一种叫做WMRB的损失图,让我们的TensorRec系统以这种方式工作。
WMRB代表“weighted margin-rank batch”,它的工作原理是随机抽取用户未进行交互(interacted )的项目,并将其预测结果与用户喜欢的项目进行比较。随着时间的推移,这将把用户喜欢的项目推到排名的首位。
我们可以告诉TensorRec在构建模型时指定WMRB,在拟合模型时指定样本批大小。在这种情况下,我们只想在正评级(≥4.0)上训练模型,以便WMRB将这些评级推到顶部。
# Let's try a new loss function: WMRBprint("Training collaborative filter with WMRB loss")ranking_cf_model = tensorrec.TensorRec(n_components=5, loss_graph=tensorrec.loss_graphs.WMRBLossGraph())ranking_cf_model.fit(interactions=sparse_train_ratings_4plus, user_features=user_indicator_features, item_features=item_indicator_features, n_sampled_items=int(n_items * .01))# Check the results of the WMRB MF CF modelprint("WMRB matrix factorization collaborative filter:")predicted_ranks = ranking_cf_model.predict_rank(user_features=user_indicator_features, item_features=item_indicator_features)check_results(predicted_ranks)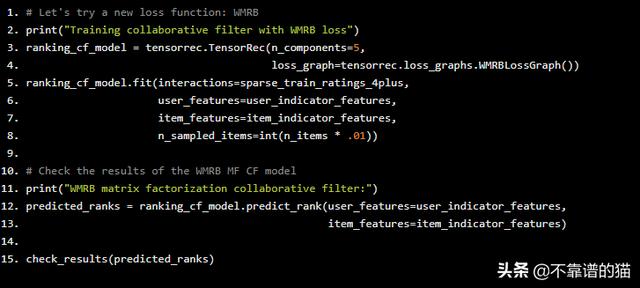
我们来看看结果:

好多了!我们从0.1%的喜欢率上升到7.76%。这是一个例子,说明了正确的损失函数是多么有效。TensorRec允许您指定和定制自己的损失图。
添加元数据特征
要继续尝试,我们应该尝试使用我们可用的其他数据。在MovieLens示例中,我们可以使用电影元数据(例如电影的类型)来丰富推荐。
在原始格式中,电影元数据文件如下所示:
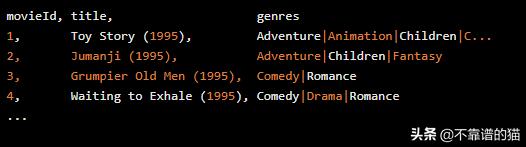
首先,我们想要阅读这些数据,将电影映射到我们的内部ID,并跟踪每部电影的类型。然后我们将使用Scikit的MultiLabelBinarizer对类型标签进行二值化。二值化输出将是我们新推荐系统的特征。
# To improve the recommendations, lets read in the movie genresprint('Loading movie metadata')with open('movies.csv', 'r') as movies_file: movies_file_reader = csv.reader(movies_file) raw_movie_metadata = list(movies_file_reader) raw_movie_metadata_header = raw_movie_metadata.pop(0)# Map the MovieLens IDs to our internal IDs and keep track of the genres and titlesmovie_genres_by_internal_id = {}movie_titles_by_internal_id = {}for row in raw_movie_metadata: row[0] = movielens_to_internal_item_ids[int(row[0])] # Map to IDs row[2] = row[2].split('|') # Split up the genres movie_genres_by_internal_id[row[0]] = row[2] movie_titles_by_internal_id[row[0]] = row[1]# Look at an example movie metadata rowprint("Raw metadata example:{}{}".format(raw_movie_metadata_header, raw_movie_metadata[0]))# Build a list of genres where the index is the internal movie ID and# the value is a list of [Genre, Genre, ...]movie_genres = [movie_genres_by_internal_id[internal_id] for internal_id in range(n_items)]# Transform the genres into binarized labels using scikit's MultiLabelBinarizermovie_genre_features = MultiLabelBinarizer().fit_transform(movie_genres)n_genres = movie_genre_features.shape[1]print("Binarized genres example for movie {}:{}".format(movie_titles_by_internal_id[0], movie_genre_features[0]))# Coerce the movie genre features to a sparse matrix, which TensorRec expectsmovie_genre_features = sparse.coo_matrix(movie_genre_features)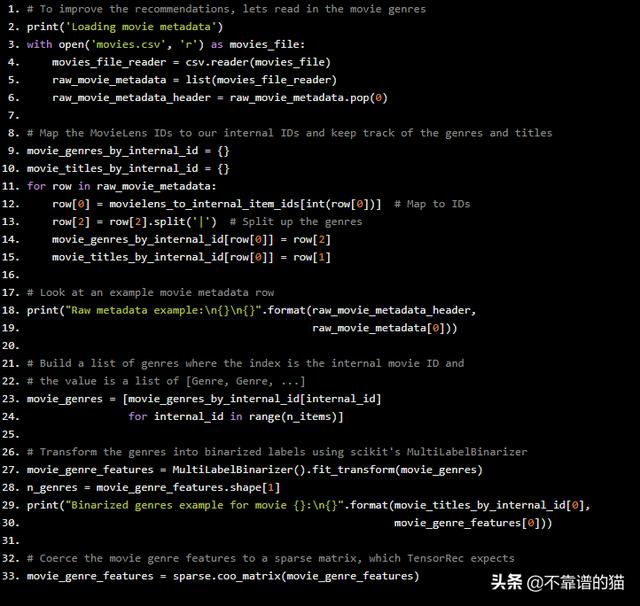
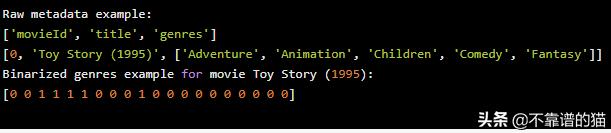
运行此命令将打印出原始元数据和二值化类型的示例:
基于内容的推荐
现在我们有关于我们项目的元数据,我们可以尝试的一件事是仅基于项目元数据进行推荐。
为此,我们将配置TensorRec模型,以使用项目特性的pass-through representation图。对我们而言,这意味着项目表示将与传入的项目特征(仅仅是电影类型)相同,并且用户表示将反映用户喜欢该特定类型的程度。
# Fit a content-based model using the genres as item featuresprint("Training content-based recommender")content_model = tensorrec.TensorRec( n_components=n_genres, item_repr_graph=tensorrec.representation_graphs.FeaturePassThroughRepresentationGraph(), loss_graph=tensorrec.loss_graphs.WMRBLossGraph())content_model.fit(interactions=sparse_train_ratings_4plus, user_features=user_indicator_features, item_features=movie_genre_features, n_sampled_items=int(n_items * .01))# Check the results of the content-based modelprint("Content-based recommender:")predicted_ranks = content_model.predict_rank(user_features=user_indicator_features, item_features=movie_genre_features)check_results(predicted_ranks)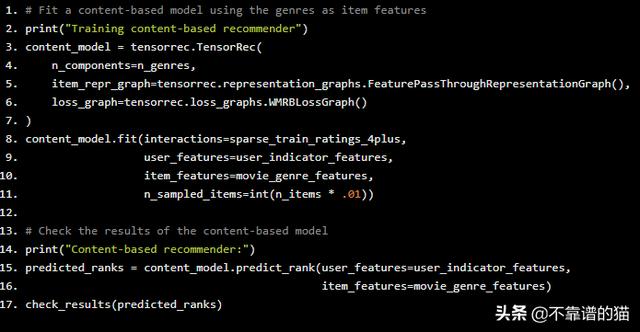
我们来看看结果:

它不像排名的协同过滤那么好,但是,当recall@10的值为1.3%时,它比我们的第一个协同过滤要有效得多。
这个系统存在一个主要的缺点:单独的类型不是非常具有描述性,也不足以提供明智的推荐信息。如果我们有更多的描述性元数据(更多的标签、角色、子类型等),我们可能会在这个基于内容的推荐系统中取得更大的成功。
另一方面,该系统有一个主要优势:仅依靠元数据特征,而不使用指示器特征,我们可以推荐在训练模型时不存在的电影。同样,如果我们拥有有价值的用户元数据,我们可以避免使用用户指标特征,并为之前从未与电影互动的用户进行预测。这被称为“cold-start”推荐。
混合模型
让我们结合这两个:我们将使用指标特征来获得协同过滤的优势,我们还将使用内容特征来利用元数据。这种将协同过滤和基于内容的推荐相结合的系统称为“混合”模型。
我们通过将两组特征堆叠在一起来实现此目的:
# Try concatenating the genres on to the indicator features for a hybrid recommender systemfull_item_features = sparse.hstack([item_indicator_features, movie_genre_features])print("Training hybrid recommender")hybrid_model = tensorrec.TensorRec( n_components=5, loss_graph=tensorrec.loss_graphs.WMRBLossGraph())hybrid_model.fit(interactions=sparse_train_ratings_4plus, user_features=user_indicator_features, item_features=full_item_features, n_sampled_items=int(n_items * .01))print("Hybrid recommender:")predicted_ranks = hybrid_model.predict_rank(user_features=user_indicator_features, item_features=full_item_features)check_results(predicted_ranks)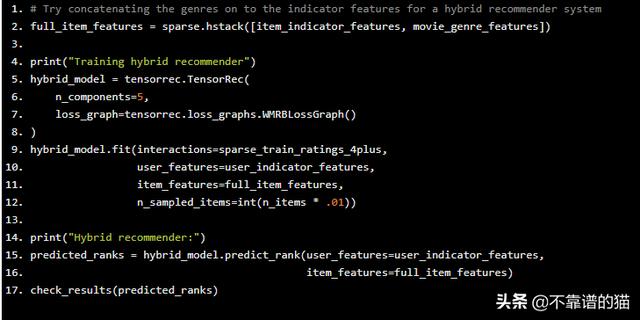
我们来看看结果:

recall@10为7.94%,这是我们最强大的推荐系统。与纯协同过滤器的7.76%的结果相比,差异并不显着,但仍然是一种改进。如果我们使用更多元数据而不仅仅是类型,我们可能会看到更好的结果。
提出推荐
我们有一个训练过的模型,现在我们可以使用这个模型为我们的用户提出建议。我们通过将用户的特征向量和所有项目特征传递给predict_rank()并检查结果排名来实现此目的,Python实现如下:
# Pull user 432's features out of the user features matrix and predict movie ranks for just that useru432_features = sparse.csr_matrix(user_indicator_features)[432]u432_rankings = hybrid_model.predict_rank(user_features=u432_features, item_features=full_item_features)[0]# Get internal IDs of User 432's top 10 recommendations# These are sorted by item ID, not by rank# This may contain items with which User 432 has already interactedu432_top_ten_recs = numpy.where(u432_rankings <= 10)[0]print("User 432 recommendations:")for m in u432_top_ten_recs: print(movie_titles_by_internal_id[m])
此Python代码段将打印出user 432的前10个推荐。我选择了user 432,因为我熟悉他们评价过的电影,所以我觉得我可以自己动手并判断他们的建议。我们应该注意到电影user 432已经评级仍将被包括 - 如果我们想要过滤那些,我们将需要通过后处理步骤来做到这一点。
让我们看看user 432的训练数据,看看他们喜欢什么类型的电影:
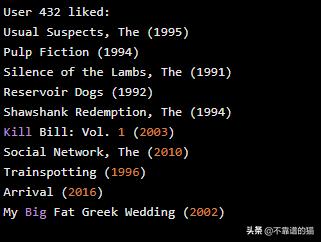
让我们看看user 432的混合模型建议:

这看起来相当不错,让我们检查一下user 432的测试电影:
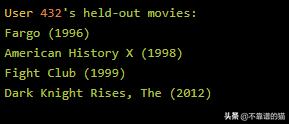
Fargo和Fight Club都在用户432的推荐中——这是一个伟大的结果!对于这个特定的用户,我们实现了50%的recall@10。
最后
为了继续优化我们的推荐系统,我们应该尝试更多的表示,预测和损失图,为系统提供更多元数据,以不同方式设计这些元数据特征,以不同方式管理交互/反馈数据,及优化系统的各种超参数。















 123
123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









