







本文主要介绍的主要内容如下:
- 概念
- ID3 决策树算法
- C4.5 决策树算法
- CART 决策树算法
1. 概念
1.1 信息熵
信息熵(Entropy),随机变量的不确定性,也称为“系统混乱程度”,它是度量样本集和纯度最常用的一种指标。假定当前样本集和 D 中第 k 类样本所占的比例为 pk(k=1,2,...,|y|) ,则 的信息熵定义
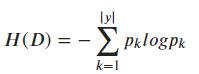
1.2 条件信息熵
条件信息熵(Conditional Entrop),样本和 D 在某个离散特征 F 的可能属性取值 v(v=1,2,...V) 对样本进行划分,其中中 Dv 表示离散特征 F 第 v 个属性上的样本数量,所以条件信息熵为
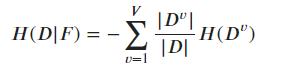
1.3 信息增益
信息增益(Information Gain),一般而言,如果信息增益越大,则意味着使用特征 来进行划分后获得的“纯度提升”越大。所以我们可以依据信息增益来进行决策树的划分特征选择。
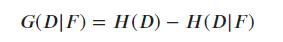
2. ID3 决策树算法
2.1 ID3 决策树算法流程
ID3 决策树算法就是以信息增益为准则来选择划分的特征。下面举例说明 ID3 的计算过程,假设有如下数据集:
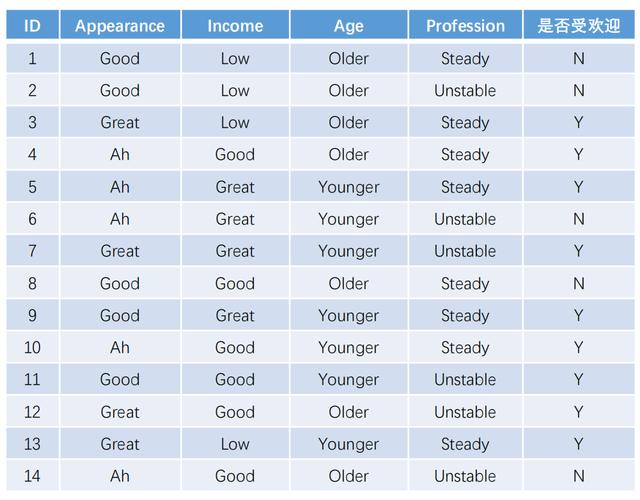
这个数据集的信息熵为:

计算数据集的条件信息熵:
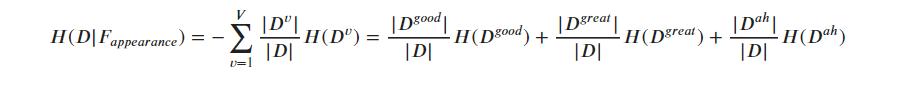
其中

最终得到:
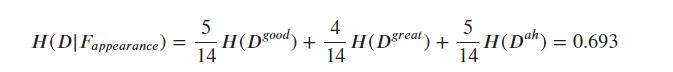
使用同样的流程方法,我们可以求得:
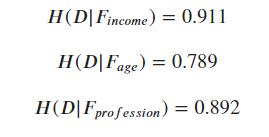
然后计算信息增益,得到:
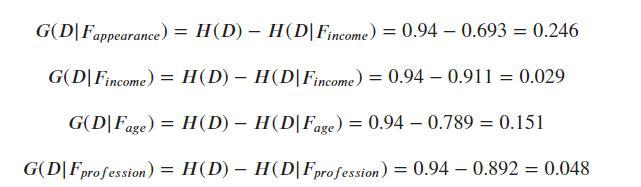
从得到的结果来看,我们应当选择 appearance 特征来进行第一次的划分,此时数据集和 D 被划分成了三个新的数据集和,三个数据集合用同样的方式来进行划分。
2.2 ID3 决策树算法的优缺点
优点:
- 具有较强的解释性
- 可以用作分类和回归
缺点:
- 容易过拟合
- 容易陷入局部最优算法更加
- 容易选择属性多的特征
3. C4.5 决策树算法
我们看到 ID3 算法更加容易选择属性多的特征,如果我们将之前的 ID 也作为一个特征,以这个特征来计算信息增益会达到最大值 0.94 ,那么决策树一开始就会将其划分成14个分支,每个分支仅有一个节点,很显然该决策树没有泛化能力。
所以出现了 C4.5 决策树算法,该算法不使用信息增益而是使用最大的增益率来选择最优划分的特征。
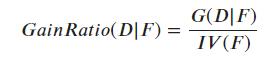
其中
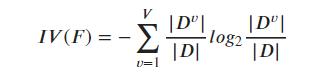
4. CART 决策树算法和使用的是
CART 决策树算法和 C4.5 以及 ID3 决策树算法有所不同,它使用的是“基尼指数”来选择划分的特征。
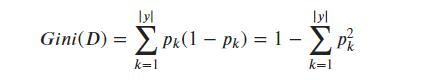
Gini(D) 反映的是从数据集 中随机抽取两个样本,其类别标记不一致的概率,因此 Gini(D)越小,说明数据集 D 的纯度越高。那么特征 的基尼指数定义为:
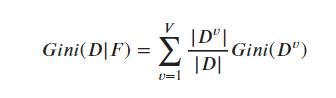
所以我们只要选择划分后基尼指数最小的那个特征作为最优划分特征即可。















 576
576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









