





在应用聚类算法时,其挑战之一就是很难评估算法效果的好坏,也很难比较不同的算法的结果。下面我们来对已经学过K均值、凝聚聚类、DBSCAN等算法做下评估。
用真实值评估聚类:有一些指标可用于评估聚类算法相对于真实聚类的结果,其中最重要的是调整rand指数(adjusted rand index,API)和归一化互信息(normalized mutual information, NMI),二者都给出了定量的变量,其最佳值为1,0表示不相关的聚类。
下面我们使用API来比较K均值,凝聚聚类和DBSCAN算法,为了对比,我们还添加了讲点随机分配到两个簇中的图像。
from sklearn.cluster import AgglomerativeClustering
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.metrics.cluster import adjusted_rand_score
x, y = make_moons(n_samples=200, noise=0.05, random_state=0)
#将数据缩放成平均值0, 方差1
scaler = StandardScaler()
scaler.fit(x)
x_scaler = scaler.transform(x)
x_scaled = scaler.transform(x)
fig, axes = plt.subplots(1, 4, figsize=(15, 3), subplot_kw={'xticks': (), 'yticks': ()})
#列出要使用的算法
algorithms = [KMeans(n_clusters=2), AgglomerativeClustering(n_clusters=2), DBSCAN()]
#创建一个随机的簇分配,作为参考
random_state = np.random.RandomState(seed=0)
random_clusters = random_state.randint(low=0, high=2, size=len(x))
#绘制随机分配
axes[0].scatter(x_scaled[:, 0], x[:, 1], c=random_clusters, cmap=mglearn.cm2, s=60)
axes[0].set_title("Random assignment - API: {:.2f}".format(adjusted_rand_score(y,
random_clusters)))
for ax, algorithm in zip(axes[1:], algorithms):
#绘制分配和簇中心
clusters = algorithm.fit_predict(x_scaled)
ax.scatter(x_scaled[:, 0], x[:, 1], c=clusters, cmap=mglearn.cm3, s=60)
ax.set_title("{} - API: {:.2f}".format(algorithm._class_._name_,
adjusted_rand_score(y, clusters)))
运行后结果如下:
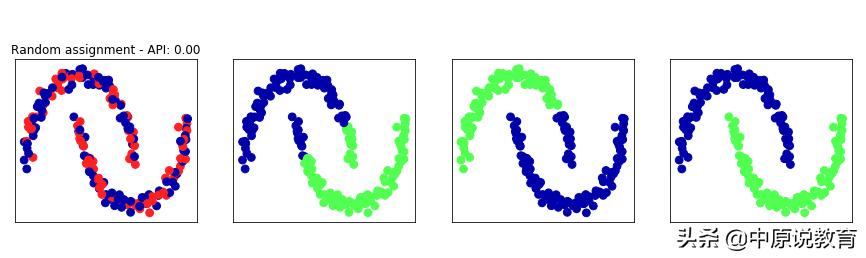
利用监督API分数在two_moons数据集上比较随机分配,K均值、凝聚聚类及DBSCAN
上图中,第二个为KMeans-API:0.50,第三个为AgglomerativeClustering-API:0.61,第四个为DBSCAN-API:1.00。调整rand指数给出了符合直觉的结果,随机粗分配的分数为0,而DBSCAN则达到了1(完美地找到了期望中的聚类)。
用这种方式评估聚类时,一个常见的错误是使用accuracy_score而不是adjusted_rand_score、normalized_mutual_info_score或其他聚类指标。使用精度的问题在于,他要求分配的促标签与真实值完全匹配。但簇标签本身毫无意义——唯一重要的是那些点位于同一个簇中。如下示例:
from sklearn.metrics import accuracy_score
#这两种点标签对应于相同的聚类
cluster1 = [0,0,1,1,0]
cluster2 = [1,1,0,0,1]
#精度为0,因为二者标签完全不相同
print("Accuracy: {:.2f}".format(accuracy_score(cluster1, cluster2)))
#调整rand为1,因为二者聚类完全相同
print("API: {:.2F}".format(adjusted_rand_score(cluster1, cluster2)))
运行结果为:
Accuracy: 0.00
API: 1.00
在没有真实值的情况下评估聚类:上面我们介绍了使用真实值来评估聚类,不过在实践中,使用诸如API之类的指标存在一个问题,在应用聚类算法时,通常没有真实值来比较结果。如果我们知道了数据的正确聚类,那么可以使用这一信息构建一个监督模型(比如分类器)。因此,使用雷士API和NMI的指标通常仅有助于开发算法,但是对评估应有是否成功没有帮助。
有一些聚类的评分指标不需要真实值,比如轮廓系数(silhouette coefficient)。但他们在实践中的效果并不好,轮廓分数计算一个簇的紧致度,其值越大越好,最高分数为1,虽然紧致的簇很好,但是并不允许复杂的形状。下面是利用轮廓分数在two_moons数据集上比较K均值、凝聚聚类和DBSCAN。
from sklearn.metrics.cluster import silhouette_score
x, y = make_moons(n_samples=200, noise=0.05, random_state=0)
#将数据缩放成平均值0, 方差1
scaler = StandardScaler()
scaler.fit(x)
x_scaler = scaler.transform(x)
x_scaled = scaler.transform(x)
fig, axes = plt.subplots(1, 4, figsize=(15, 3), subplot_kw={'xticks': (), 'yticks': ()})
#列出要使用的算法
algorithms = [KMeans(n_clusters=2), AgglomerativeClustering(n_clusters=2), DBSCAN()]
#创建一个随机的簇分配,作为参考
random_state = np.random.RandomState(seed=0)
random_clusters = random_state.randint(low=0, high=2, size=len(x))
#绘制随机分配
axes[0].scatter(x_scaled[:, 0], x[:, 1], c=random_clusters, cmap=mglearn.cm2, s=60)
axes[0].set_title("Random assignment - API: {:.2f}".format(adjusted_rand_score(y,
random_clusters)))
for ax, algorithm in zip(axes[1:], algorithms):
#绘制分配和簇中心
clusters = algorithm.fit_predict(x_scaled)
ax.scatter(x_scaled[:, 0], x[:, 1], c=clusters, cmap=mglearn.cm3, s=60)
ax.set_title("{} - API: {:.2f}".format(algorithm._class_._name_,
silhouette_score(x_scaled, clusters)))
运行结果如下:

上图中随机分配的得分仍然是0, 第二个为KMeans,得分0.49,第三个为AgglomerativeClustering,得分0.46,最后一个为DBSCAN,得分0.38。通过上述比较可见,使用无监督轮廓分数时,KMeans的得分最高,而使用真实值评估时得分最高的则是DBSCAN。
稍好的策略是使用基于鲁棒性的(rubustness-bassed)聚类指标,这种指标先向数据中添加一些噪声,或者使用不同的参数设定,然后运行算法,并对结果进行比较,其思想是,如果许多算法参数和许多数据扰动返回相同的结果,那么他很可能是可信的。
下节我们将继续比较这几种聚类算法在人脸数据集上的效果。















 2691
2691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









