







聚类分析基本概念
聚类分析定义
聚类分析是一种数据分析技术,对大量未知标注的数据集,通过将具有相似数据特性的数据对象分组到一起,使得类别内的数据相似度较大而类别间的数据相似度较小,以便对这些数据对象进行更好的理解和分析。总的来说,聚类分析就是将数据划分成有意义或有用的组(簇)。
注:聚类分析是无监督学习。
聚类类型
- 划分聚类(Partitional Clustering)
- 层次聚类(Hierarchical Clustering)
- 互斥聚类(exclusive clustering)
- 非互斥(重叠)聚类(non-exclusive)
- 模糊聚类(fuzzy clustering)
- 完全聚类(complete clustering)
- 部分聚类(partial clustering)
划分聚类(Partitional Clustering)
划分聚类简单地将数据对象集划分成不重叠的子集,使得每个数据对象恰在一个子集。
![![][pt_01]](https://img-blog.csdnimg.cn/768e7a108d9c48ddad53ee57e9baf2ad.png)
层次聚类(Hierarchical Clustering)
层次聚类是嵌套簇的集族,组织成一棵树。
![![][pt_02]](https://img-blog.csdnimg.cn/5569b4466e3f4dbd9530672d28cbfc24.png)
互斥的、重叠的、模糊的
- 互斥的(Exclusive)
- 每个对象都指派到单个簇
- 重叠的(overlapping)或非互斥的(non-exclusive)
- 聚类用来反映一个对象。同时属于多个组(类)这一事实
- 例如:在大学里,一个人可能既是学生,又是雇员
- 模糊聚类(Fuzzy clustering )
- 每个对象以一个0(绝对不属于)和1(绝对属于)之间的隶属权值属于每个簇。换言之,簇被视为模糊集
- 部分的(Partial)
- 部分聚类中数据集某些对象可能不属于明确定义的组。如:一些对象可能是离群点、噪声
- 完全的(complete)
- 完全聚类将每个对象指派到一个簇
簇类型
- 明显分离的
- 基于原型的
- 基于图的
- 基于密度的
- 概念簇
明显分离的(Well-Separated)
每个点到同簇中任一点的距离比到不同簇中所有点的距离更近。
![![][pt_03]](https://img-blog.csdnimg.cn/62a34db7e0e243d7b97ced0b2926cc2e.png)
基于原型的
-
每个对象到定义该簇的原型的距离比到其他簇的原型的距离更近。对于具有连续属性的数据,簇的原型通常是质心,即簇中所有点的平均值。当质心没有意义时,原型通常是中心点,即簇中最有代表性的点。
-
基于中心的( Center-Based)的簇:每个点到其簇中心的距离比到任何其他簇中心的距离更近。
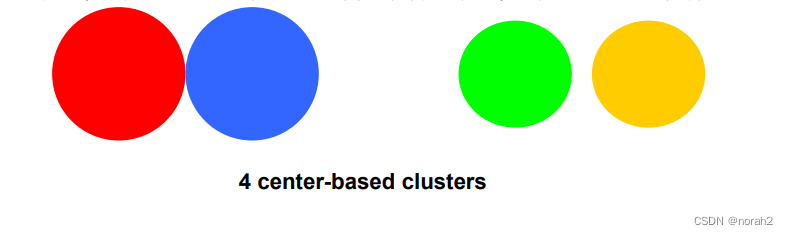
基于图的
- 如果数据用图表示,其中节点是对象,而边代表对象之间的联系。
- 簇可以定义为连通分支(connected component):互相连通但不与组外对象连通的对象组。
- 基于近邻的( Contiguity-Based):其中两个对象是相连的,仅当它们的距离在指定的范围内。这意味着,每个对象到该簇某个对象的距离比到不同簇中任意点的距离更近。
![![][pt_05]](https://img-blog.csdnimg.cn/7f4465d22022422db3789b917cf64161.png)
基于密度的(Density-Based)
簇是对象的稠密区域,被低密度的区域环绕。
![![][pt_06]](https://img-blog.csdnimg.cn/0c76541372d945fbb61a057c5225c98e.png)
概念簇(Conceptual Clusters)
可以把簇定义为有某种共同性质的对象的集合。例如:基于中心的聚类。还有一些簇的共同性质需要更复杂的算法才能识别出来。
![![][pt_07]](https://img-blog.csdnimg.cn/cb8efd5728a64b3d9bbddf1237c9ca1b.png)
K-Means聚类
K-Means算法,被成为k-平均或k-均值,是一种广泛使用的聚类算法,或者成为其他聚类算法的基础。
K-means算法步骤
假定输入样本为 S = x 1 , x 2 , … , x m S=x_1, x_2, \dots, x_m S=x1,x2,…,xm, 则算法步骤为:
- 选择初始的k个类别中心 μ 1 , μ 2 , … , μ k \mu_1, \mu_2, \dots, \mu_k μ1,μ2,…,μk
- 对于每个样本 x i x_i xi, 将其标记为距离类别中心最近的类别,即 l a b e l i = arg min 1 ≤ j ≤ k ∥ x i − μ j ∥ label_i=\argmin_{1\leq{j}\leq{k}}\|x_i-\mu_{j}\| labeli=argmin1≤j≤k∥xi−μj∥
- 将每个类别中心更新为隶属该类别的所有样本的均值: μ j = 1 ∥ c j ∥ ∑ i ∈ c j x j \mu_j=\frac{1}{\|c_j\|}\sum_{i\in{c}_j}{x_j} μj=∥cj∥1∑i∈cjxj
- 重复最后两步,直到类别中心的变化小于某阈值。
- 中止条件:迭代次数/簇中心变化率/最小平方误差MSE(Minimum Squared Error)
K-Means过程:
![![][pt_08]](https://img-blog.csdnimg.cn/02c6fba9298f4946adbce1a2e3e8778e.png)
K-means的公式化解释:
- 记K个簇中心为 μ 1 , μ 2 , … , μ k \mu_1, \mu_2, \dots, \mu_k μ1,μ2,…,μk, 每个簇的样本数目为 N 1 , N 2 , … , N k N_1, N_2, \dots, N_k N1,N2,…,Nk
- 使用平方误差作为目标函数: J ( μ 1 , μ 2 , … , μ k ) = 1 2 ∑ j = 1 K ∑ i = 1 N j ( x i − μ j ) 2 J(\mu_1, \mu_2, \dots, \mu_k)=\frac{1}{2}\sum_{j=1}^{K}\sum_{i=1}^{N_j}(x_i-\mu_j)^2 J(μ1,μ2,…,μk)=21∑j=1K∑i=1Nj(xi−μj)2
- 该函数为关于 μ 1 , μ 2 , … , μ k \mu_1, \mu_2, \dots, \mu_k
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2885
2885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









