





前言
看了那么多K折的介绍,没发现讲得很明白的。。。
- 当数据量少时我们面对的问题
问题一:我们都知道数据集需要且分为训练集、验证集、和测试集,还知道一般都是按6:2:2的比例来切分,但是当数据集比较小时,就算不要测试集,再留出一部分作为验证集也很奢侈,最后很可能因为训练集不够导致欠拟合。
问题二:数据可能分布不均匀,特别是在数据量较少时,那切分训练集和验证集的时候,就很有可能导致训练集里全是A,而验证集里全是B,当然只是极端情况,这会导致模型得不到充分训练,影响模型的泛化性能。
- K折很好的解决了上面两个问题
一、充分利用现有数据来调参甄选模型
二、利用平均的思想,减弱数据分布不均带来的影响
- K折实现步骤
步骤一:将训练集且分为K等份,每次取不同的1份作为验证集,余下的K-1份作为训练集
步骤二:选定一组超参数(对应于一个模型),以第 i 份为验证集、其余为训练集训练若干个epoch,将训练结果保留,记为 第 i 份对应的结果,最后一共有K份结果,然后对K份结果求均值,作为当前超参数对应的结果(注意观察每次训练时是否有过拟合)
步骤三:调整超参数,重复步骤二
步骤四:比对各组超参数的对应结果,选出当前最优的一组超参数
步骤五:通过步骤四选出的超参数新建模型在整个训练集上进行训练,因为在步骤二上模型没有过拟合,那现在训练数据量变大了就更不会出现过拟合了
小结:
- 个人感觉数据集很少的时候可能有用,但是数据集基本够的时候就没必要了,毕竟重复计算太多了
- K值网传数据集小就设为10,否则设为5
实践
本次又犯了和TF2.0猫狗识别同样的错误,拿到数据后第一步都是进行数据清理!!!
代码结构设计:
- 数据加载类
- 数据预处理类
- 自定义模型类
- K折类
1、定义模型类
# !usr/bin/python
2、K折数据切分
def 3、K折训练
def 4、绘制K折训练结果
def 5、调参
# 步骤一:获取数据集
- k = 5
num_epochs = 500
batch_size = 32
lr = 5
weight_decay = 0.0
final train loss [0.1208] valid loss [0.1599]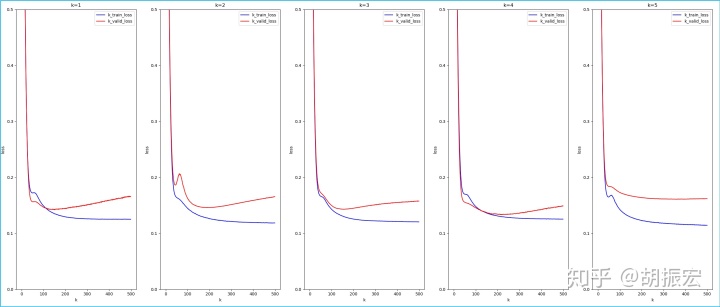
大概150个epoch后过拟合
- k = 3
num_epochs = 500
batch_size = 32
lr = 5
weight_decay = 0.0
final train loss [0.1191] valid loss [0.1659]
同样差不多150个epoch后过拟合
- k = 5
num_epochs = 150
batch_size = 32
lr = 5
weight_decay = 0.01
final train loss [0.1336] valid loss [0.1478]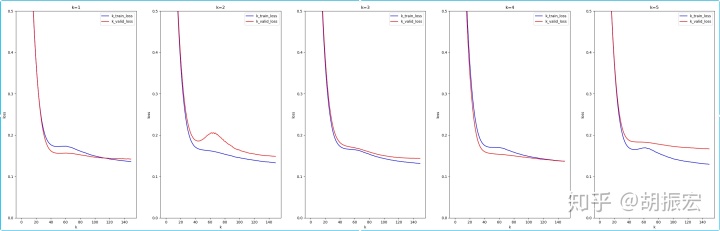
6、全部训练数据重新训练一遍
epoch 142, cost time 0.0216, train loss 0.1263
epoch 143, cost time 0.0224, train loss 0.1269
epoch 144, cost time 0.0210, train loss 0.1264
epoch 145, cost time 0.0212, train loss 0.1266
epoch 146, cost time 0.0213, train loss 0.1262
epoch 147, cost time 0.0250, train loss 0.1265
epoch 148, cost time 0.0248, train loss 0.1261
epoch 149, cost time 0.0237, train loss 0.1263
epoch 150, cost time 0.0239, train loss 0.1260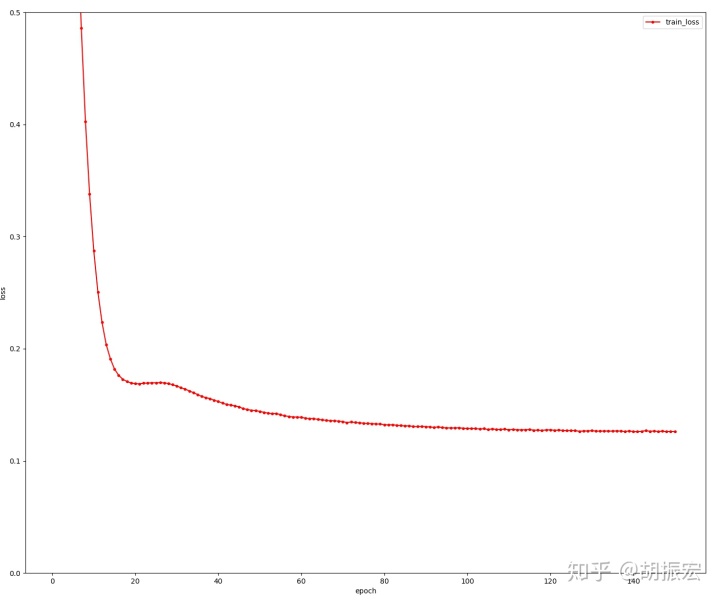
7、预测
有坑,明天填
总结
对这个案例算法调参上收获了一些体会,但是体会更大的是发现写出逻辑清晰、结构优美的代码,感觉都想去找本Python的设计模式看看了















 2753
2753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









