






大量数据中具有"相似"特征的数据点或样本划分为一个类别。聚类分析提供了样本集在非监督模式下的类别划分。聚类的基本思想是"物以类聚、人以群分",将大量数据集中相似的数据样本区分出来,并发现不同类的特征。
聚类模型可以建立在无类标记的数据上,是一种非监督的学习算法。尽管全球每日新增数据量以PB或EB级别增长,但是大部分数据属于无标注甚至非结构化。所以相对于监督学习,不需要标注的无监督学习蕴含了巨大的潜力与价值。聚类根据数据自身的距离或相似度将他们划分为若干组,划分原则是组内样本最小化而组间距离最大化。
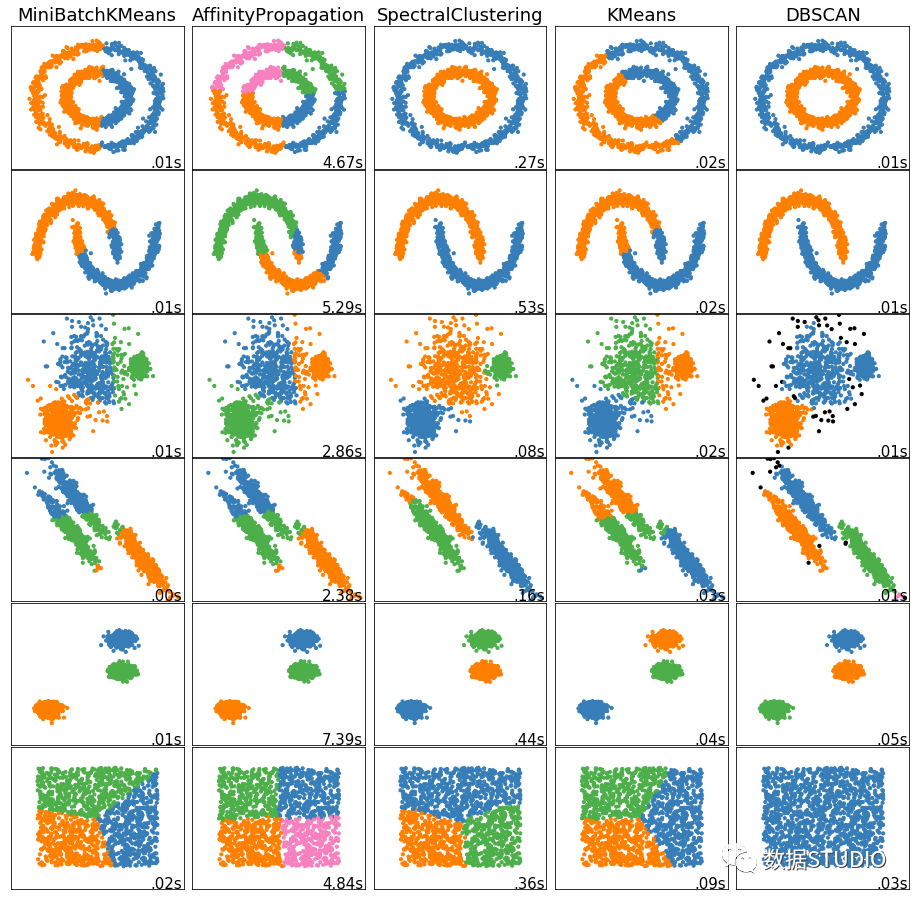
聚类分析常用于数据探索或挖掘前期
- 没有先验经验做探索性分析
- 样本量较大时做预处理
常用于解决
- 数据集可以分几类;每个类别有多少样本量
- 不同类别中各个变量的强弱关系如何
- 不同类型的典型特征是什么
一般应用场景
- 群类别间的差异性特征分析
- 群类别内的关键特征提取
- 图像压缩、分割、图像理解
- 异常检测
- 数据离散化
当然聚类分析也有其缺点
- 无法提供明确的行动指向
- 数据异常对结果有影响
本文将从算法原理、优化目标、sklearn聚类算法、算法优缺点、算法优化、算法重要参数、衡量指标以及案例等方面详细介绍KMeans算法。
KMeans
K均值(KMeans)是聚类中最常用的方法之一,基于点与点之间的距离的相似度来计算最佳类别归属。
KMeans算法通过试着将样本分离到 个方差相等的组中来对数据进行聚类,从而最小化目标函数 (见下文)。该算法要求指定集群的数量。它可以很好地扩展到大量的样本,并且已经在许多不同领域的广泛应用领域中使用。
被分在同一个簇中的数据是有相似性的,而不同簇中的数据是不同的,当聚类完毕之后,我们就要分别去研究每个簇中的样本都有什么样的性质,从而根据业务需求制定不同的商业或者科技策略。常用于客户分群、用户画像、精确营销、基于聚类的推荐系统。
算法原理
从 个样本数据中随机选取 个质心作为初始的聚类中心。质心记为
定义优化目标
开始循环,计算每个样本点到那个质心到距离,样本离哪个近就将该样本分配到哪个质心,得到K个簇
对于每个簇,计算所有被分到该簇的样本点的平均距离作为新的质心
直到 收敛,即所有簇不再发生变化。
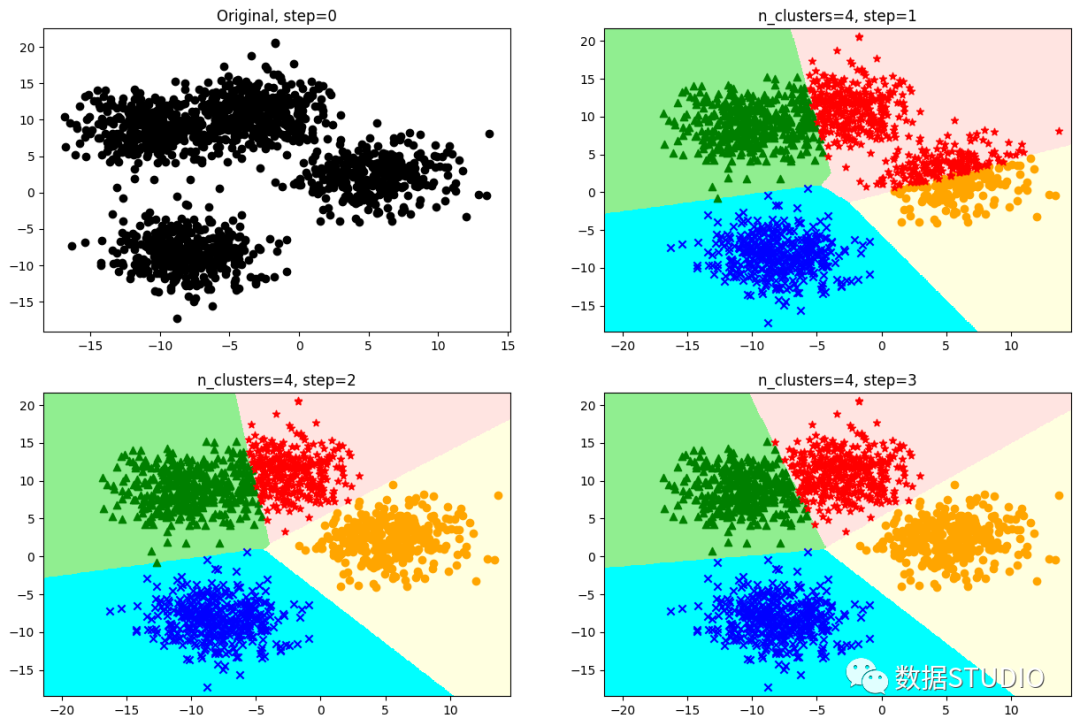
优化目标
KMeans 在进行类别划分过程及最终结果,始终追求"簇内差异小,簇间差异大",其中差异由样本点到其所在簇的质心的距离衡量。在KNN算法学习中,我们学习到多种常见的距离 ---- 欧几里得距离、曼哈顿距离、余弦距离。
在sklearn中的KMeans使用欧几里得距离:
(cluster Sum of Square) , 又叫做
Inertia 。
而将一个数据集中的所有簇的簇内平方和相加,就得到了整体平方和(Total Cluster Sum of Square),又叫做Total Inertia。Total Inertia越小,代表着每个簇内样本越相似,聚类的效果就越好。因此 KMeans 追求的是,求解能够让Inertia最小化的质心。
KMeans有损失函数吗?损失函数本质是用来衡量模型的拟合效果的,只有有着求解参数需求的算法,才会有损失函数。
KMeans不求解什么参数,它的模型本质也没有在拟合数据,而是在对数据进行一 种探索。另外,在决策树中有衡量分类效果的指标准确度
accuracy,准确度所对应的损失叫做泛化误差,但不能通过最小化泛化误差来求解某个模型中需要的信息,我们只是希望模型的效果上表现出来的泛化误差很小。因此决策树,KNN等算法,是绝对没有损失函数的。
虽然在sklearn中只能被动选用欧式距离,但其他距离度量方式同样可以用来衡量簇内外差异。不同距离所对应的质心选择方法和Inertia如下表所示, 在KMeans中,只要使用了正确的质心和距离组合,无论使用什么样的距离,都可以达到不错的聚类效果。
| 距离度量 | 质心 | Inertia |
|---|---|---|
| 欧几里得距离 | 均值 | 最小化每个样本点到质心的欧式距离之和 |
| 曼哈顿距离 | 中位数 | 最小化每个样本点到质心的曼哈顿距离之和 |
| 余弦距离 | 均值 | 最小化每个样本点到质心的余弦距离之和 |
sklearn.cluster.KMeans
语法:
sklearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=None, algorithm='auto')
参数与接口详解见文末附录
例:
>>> from sklearn.cluster import KMeans
>>> import numpy as np
>>> X = np.array([[1, 2], [1, 4], [1, 0],
... [10, 2], [10, 4], [10, 0]])
>>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
>>> kmeans.labels_
array([1, 1, 1, 0, 0, 0], dtype=int32)
>>> kmeans.predict([[0, 0], [12, 3]])
array([1, 0], dtype=int32)
>>> kmeans.cluster_centers_
array([[10., 2.],
[ 1., 2.]])
KMeans算法优缺点
优点
- KMeans算法是解决聚类问题的一种经典算法, 算法简单、快速 。
- 算法尝试找出使平方误差函数值最小的 个划分。当簇是密集的、球状或团状的,且簇与簇之间区别明显时,聚类效果较好 。
缺点
- KMeans方法只有在簇的平均值被定义的情况下才能使用,且对有些分类属性的数据不适合。
- 要求用户必须事先给出要生成的簇的数目 。
- 对初值敏感,对于不同的初始值,可能会导致不同的聚类结果。
- 不适合于发现非凸面形状的簇,或者大小差别很大的簇。
- KMeans本质上是一种基于欧式距离度量的数据划分方法,均值和方差大的维度将对数据的聚类结果产生决定性影响。所以在聚类前对数据(具体的说是每一个维度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1700
1700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









