






工作中,销量预测我们经常能碰到,如电商平台,会根据之前几个月销量和往年销量,预测未来几个月的销量,及时调整备货,细分到具体每个商品厂家,也会根据过往订单销量,有计划的生成商品,避免滞销或脱销。
本篇文章,会结合案例,由浅入深,逐步探索销量预测方法和模型。
案例一
某智能音箱生产商,上半年销量分别为5100、6030、7500、6800、7100、8200,如果预测未来三个月销量?
分析:考虑到智能音箱没有季节属性,结合每月销量趋势,这里可以利用简单线性回归模型。
这里利用Excel进行分析
方法一:
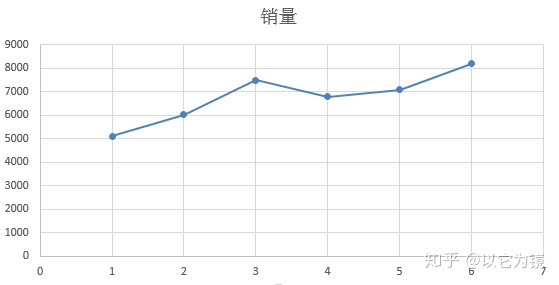
1.绘制1-6月的实际销售数据图
2.增加趋势图和显示方程
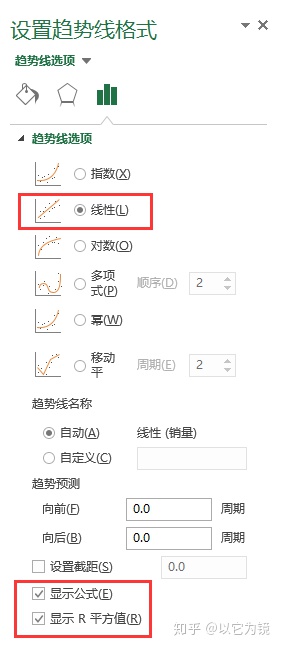
这里选用简单的线性,设置显示公式和R平方值
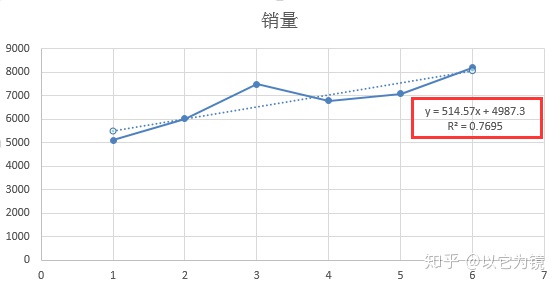
从图中看出,得到了一条逐月上升的虚线图,线性方程为y = 514.57x + 4987.3,
R² = 0.7695,R² 越接近1,表示拟合度越好。
3.把公式带入表格,可以预测未来三个月的销量,如下
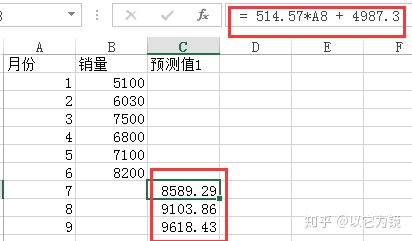
这里还有另外一种简便方法,直接利用FORECAST函数即可
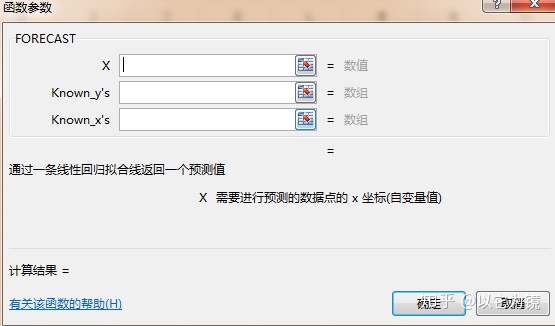
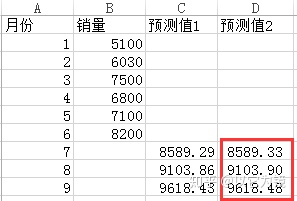
对比两种方式,得出结果大体一致。
方法二:(此方法适用Excel2016版或更高版本)
Excel2016版之后增加预测工作表功能,如果电脑是新版本Excel可以尝试一下。
选中目标区域——数据——预测工作表,按步骤操作后,会生产如下图。
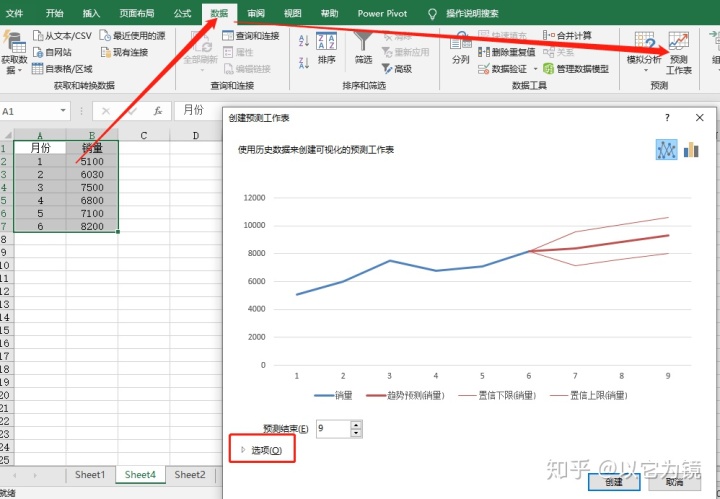
点击左下角选项按钮,可以按照需求进一步调整
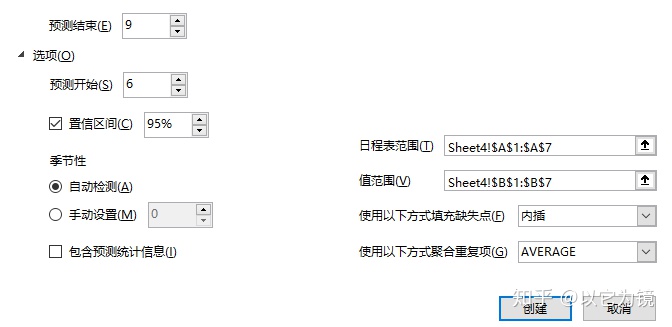
之后点击右下角创建按钮,会单独生成一张工作表
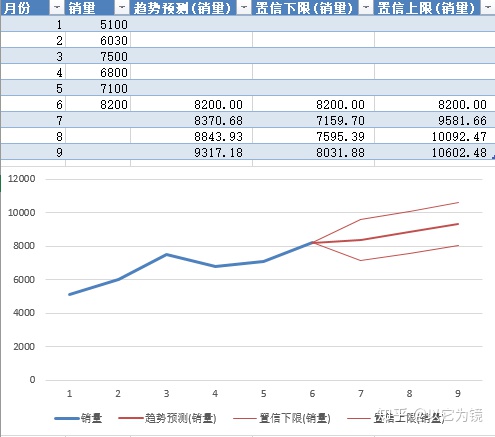
此方法计算预测值的时候,会直接生产置信区间,这里选择常用的95%置信区间,对比方法一生产的预测值,有2%的浮动,但都在置信区间内,可以接受。
上面只是举例粗略估计,实际中要考虑各种内外部因素,如活动促销,季节周期和政策指向等,且预测方法有很多种,如移动平均法、指数平滑法等,要根据实际情况选择最优模型方法。
案例二
某空调品牌,已知近三年每月销量(见下图),预测未来一年销量。

分析:我们从表中看出,空调销量有明显的季节性,夏季时销量明显高于其他季节。这里利用简单的同比移动平均法做一下预测。这里需要区分注意同比和环比,同比是指历史同期数据进行比较,环比是指相近时期进行比较。
这里以7月份为例,2017年月销6900,2018年月销7200,2019年月销7000,我们以年份远近分配权重,年份近权重大,2017年权重1,2018年权重2,2019年权重3。注:这里权重分配,可以结合具体业务,根据业务特性进行调整。
计算公式:2020年7月销量=(6900*1+7200*2+7000*3)/(1+2+3)=7050
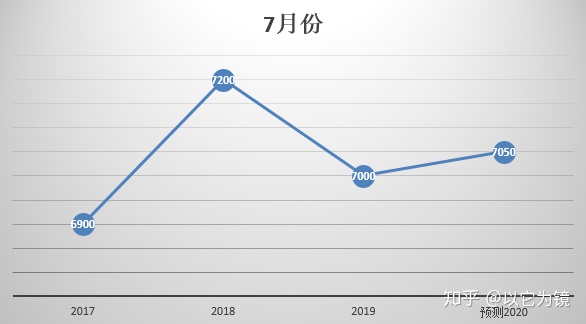
以此类推,利用此公式,可以预测2020年每月销量

此案例只是简单的单个商品预测,但真实的电商平台,销售着数以百万计的商品,要想进一步精确预测整个平台销量,我们需要细化到每个商品的属性特征,加入多种因素来预测,案例三会进一步探究。
案例三
上面两个案例数据都比较简单,不存在其他相关变量,原本想找一个真实丰富的电商平台销售数据集,更加深入了解销量预测,但网上没有找到公开相关的数据集。最后,在kaggle找到了汽车销量预测项目,是基于汽车的有关信息预测汽车销量的数据挖掘竞赛,这里利用Python进行时间序列简要分析。
1.数据准备
数据集地址:
https://www.kaggle.com/c/competitive-data-science-predict-future-sales/overviewwww.kaggle.com数据集说明:
- sales_train.csv---训练集(2013年1月至2015年10月的每日历史数据)
- items.csv---有关项目/产品的补充信息
- item_categories.csv---有关项目类别的补充信息
- shop.csv---有关商店的补充信息
- test.csv---测试集(需要预测这些商店和产品在2015年11月的销售额)
字段说明:
- ID---代表测试集中的(商店,商品)元组的ID
- shop_id---商店的唯一标识符
- item_id---产品的唯一标识符
- item_category_id---项目类别的唯一标识符
- item_cnt_day---销售的产品数量
- item_price---商品的当前价格
- date ---格式为dd / mm / yyyy的日期
- date_block_num---连续的月份号,为方便起见,2013年1月为0,2013年2月为1,...,2015年10月为33
- item_name---项目名称
- shop_name---商店名称
- item_category_name---项目类别名称
2.数据处理
导入包
#导入基础包
载入数据
items = pd.read_csv('C:/Users/Administrator/Downloads/data/items.csv')
shops = pd.read_csv('C:/Users/Administrator/Downloads/data/shops.csv')
cats = pd.read_csv('C:/Users/Administrator/Downloads/data/item_categories.csv')
sales= pd.read_csv('C:/Users/Administrator/Downloads/data/sales_train.csv')
# 设置ID为索引
test = pd.read_csv('C:/Users/Administrator/Downloads/data/test.csv').set_index('ID')训练集融合
train = sales.join(items, on='item_id', rsuffix='_').join(shops, on='shop_id', rsuffix='_').join(cats,
on='item_category_id', rsuffix='_').drop(['item_id_', 'shop_id_', 'item_category_id_'], axis=1)查看基本信息
train.info()预览数据
train.head()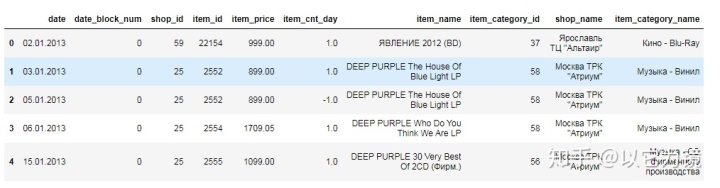
修改字段属性
预览看出原数据集date字段格式为02.01.2013,即为日/月/年,且date字段属性为object,我们这里修改为时间序列
#通过匿名函数把date修改为时间序列
train.date=train.date.apply(lambda x:datetime.datetime.strptime(x, '%d.%m.%Y'))
#再次检查
print(train.info())
train.head()
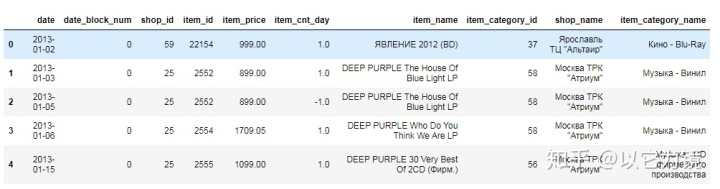
查看异常值
这里利用图形查看异常值分布
plt.figure(figsize=(10,4))
plt.xlim(-100, 3000)
sns.boxplot(x=train.item_cnt_day)
plt.figure(figsize=(10,4))
plt.xlim(train.item_price.min(), train.item_price.max()*1.1)
sns.boxplot(x=train.item_price)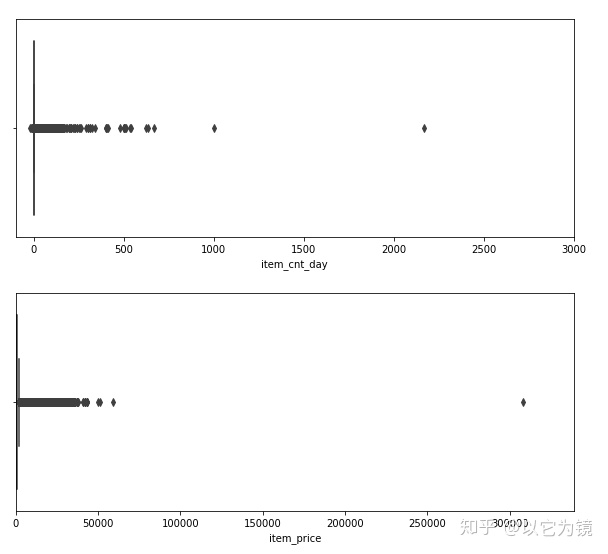
删除异常值,这里通过截取方法
train = train[train.item_cnt_day<1000]
train = train[train.item_price<100000]查看缺失值
train.isnull().sum() 
通过查询,显示无缺失值。
注:上面数据处理方法,可以参考我的上篇文章《数据分析之Python干货笔记》,里面会有Python进行数据分析的基础讲解。
3.数据分析
ts时间序列
#以月度汇总所需指标
#代码解释:按date_block_num日期块(月)、shop_id和item_id聚合,选择列date,item_price和item_cnt(sales),提供一个字典,说明在哪一列上执行什么聚合,日期列包括min和max,项目的平均价格,销售总额。
monthly_sales=sales.groupby(["date_block_num","shop_id","item_id"])[
"date","item_price","item_cnt_day"].agg({"date":["min",'max'],"item_price":"mean","item_cnt_day":"sum"})
#查看前20行
monthly_sales.head(20)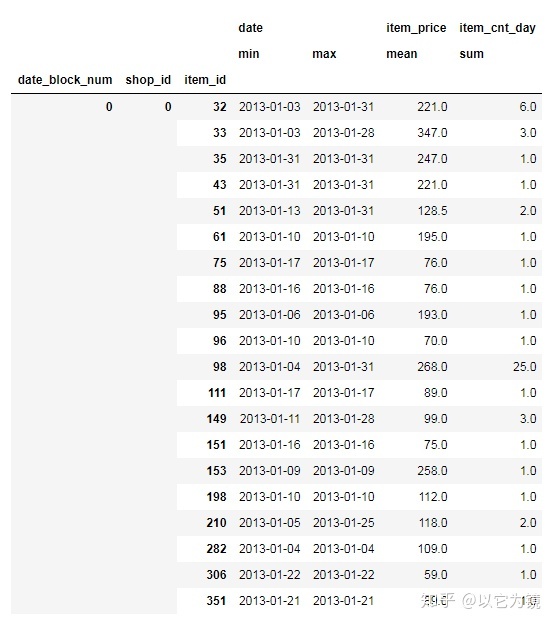
此部分TS分析,主要参考kaggle上大神的分析,这里跟着大神分享的经验过一下。
这个目标要求我们预测下个月的销售情况,每件商品随时间的销售本身就是一个时间序列。在深入研究所有序列之前,首先让我们了解如何预测单个序列,这里选择预测所有商品下月总销售额。
1.计算每月的总销售并绘制数据
ts=sales.groupby(["date_block_num"])["item_cnt_day"].sum()
ts.astype('float')
plt.figure(figsize=(16,8))
plt.title('Total Sales of the company')
plt.xlabel('Time')
plt.ylabel('Sales')
plt.plot(ts);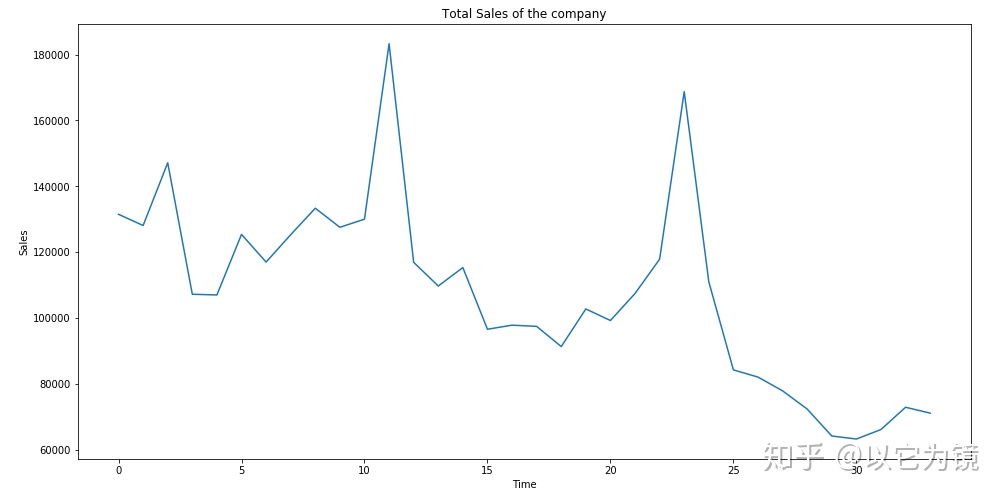
plt.figure(figsize=(16,6))
plt.plot(ts.rolling(window=12,center=False).mean(),label='Rolling Mean');
plt.plot(ts.rolling(window=12,center=False).std(),label='Rolling sd');
plt.legend();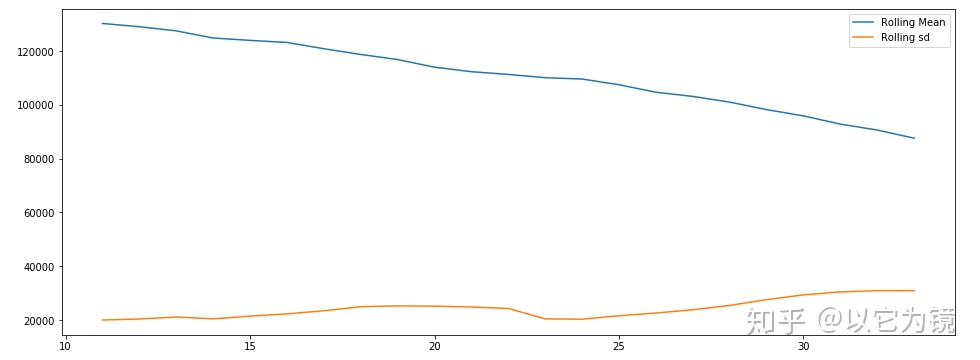
快速预览:销售量有一个明显的季节性,且通过mean看出销售量整体呈下降趋势。
2.下面深入分解:长期趋势Trend、季节性seasonal和随机残差residual
import statsmodels.api as sm
#statsmodels支持两类分解模型,加法模型和乘法模型,model的参数设置为"additive"(加法模型)和"multiplicative"(乘法模型)
res = sm.tsa.seasonal_decompose(ts.values,freq=12,model="multiplicative") #这里选用multiplicative,additive省略,正常分析需要两者对比
plt.figure(figsize=(16,12))
fig = res.plot()
fig.show()
3.平稳性测试
平稳性是指级数的时不变性,时间序列中的两点之间的联系仅仅取决于它们之间的距离,而不是方向(向前/向后)。当一个时间序列是平稳的,它可以更容易建模。统计建模方法假设或要求时间序列是平稳的。
有多种测试可以用来检查平稳性
- ADF( Augmented Dicky Fuller Test)
- KPSS
- PP (Phillips-Perron test)
我们这里选用最常用的ADF
# 稳定性测试
def test_stationarity(timeseries):
#执行Dickey-Fuller测试:
print('Results of Dickey-Fuller Test:')
dftest = adfuller(timeseries, autolag='AIC')
dfoutput = pd.Series(dftest[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
for key,value in dftest[4].items():
dfoutput['Critical Value (%s)'%key] = value
print (dfoutput)
test_stationarity(ts)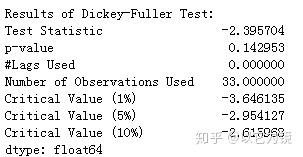
# 消除趋势
# 差分是一种变换时间序列数据集的方法,它可以用于消除序列对时间性的依赖性,即所谓的时间性依赖。
from pandas import Series as Series
# 创建一个不同的系列
def difference(dataset, interval=1):
diff = list()
for i in range(interval, len(dataset)):
value = dataset[i] - dataset[i - interval]
diff.append(value)
return Series(diff)
# invert differenced forecast
def inverse_difference(last_ob, value):
return value + last_ob
#绘图
ts=sales.groupby(["date_block_num"])["item_cnt_day"].sum()
ts.astype('float')
plt.figure(figsize=(16,16))
plt.subplot(311)
plt.title('Original')
plt.xlabel('Time')
plt.ylabel('Sales')
plt.plot(ts)
plt.subplot(312)
plt.title('After De-trend')
plt.xlabel('Time')
plt.ylabel('Sales')
new_ts=difference(ts)
plt.plot(new_ts)
plt.plot()
plt.subplot(313)
plt.title('After De-seasonalization')
plt.xlabel('Time')
plt.ylabel('Sales')
new_ts=difference(ts,12) # 假设季节性是12个月
plt.plot(new_ts)
plt.plot()
plt.savefig() 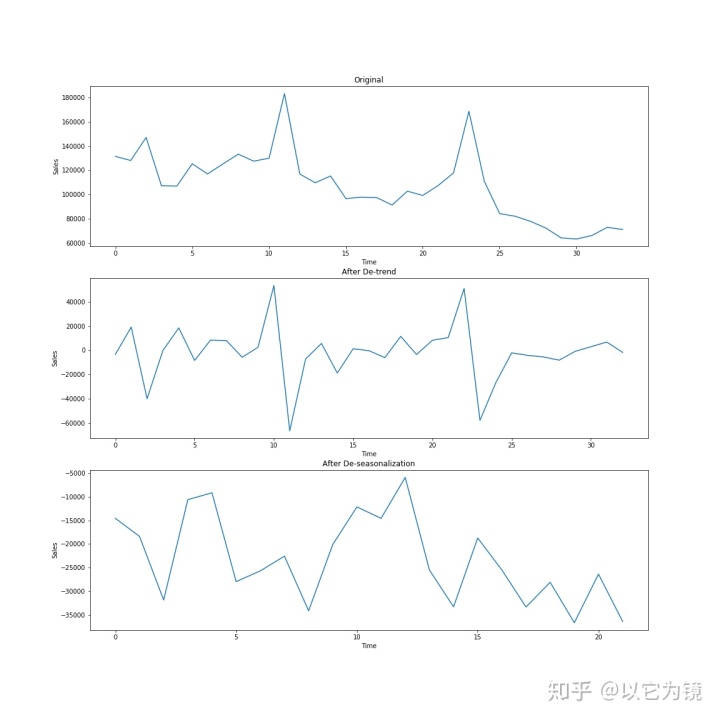
# 现在再检验一下反季节性之后的平稳性
test_stationarity(new_ts)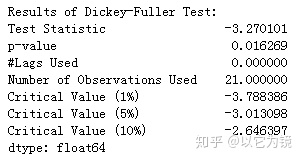
现在经过转换,DF测试的p值在5%之内,因此我们可以假设序列的平稳性。
利用上面定义的逆变换函数,我们可以很容易地得到原来的序列。
4.选择最优模型
常用的时间序列模型有AR、MA和ARMA
现只选择其中AR模型看一下效果
def tsplot(y, lags=None, figsize=(10, 8), style='bmh',title=''):
if not isinstance(y, pd.Series):
y = pd.Series(y)
with plt.style.context(style):
fig = plt.figure(figsize=figsize)
#mpl.rcParams['font.family'] = 'Ubuntu Mono'
layout = (3, 2)
ts_ax = plt.subplot2grid(layout, (0, 0), colspan=2)
acf_ax = plt.subplot2grid(layout, (1, 0))
pacf_ax = plt.subplot2grid(layout, (1, 1))
qq_ax = plt.subplot2grid(layout, (2, 0))
pp_ax = plt.subplot2grid(layout, (2, 1))
y.plot(ax=ts_ax)
ts_ax.set_title(title)
smt.graphics.plot_acf(y, lags=lags, ax=acf_ax, alpha=0.5)
smt.graphics.plot_pacf(y, lags=lags, ax=pacf_ax, alpha=0.5)
sm.qqplot(y, line='s', ax=qq_ax)
qq_ax.set_title('QQ Plot')
scs.probplot(y, sparams=(y.mean(), y.std()), plot=pp_ax)
plt.tight_layout()
return
#绘图
# 模拟一个AR(1)过程,alpha = 0.6
np.random.seed(1)
n_samples = int(1000)
a = 0.6
x = w = np.random.normal(size=n_samples)
for t in range(n_samples):
x[t] = a*x[t-1] + w[t]
limit=12
_ = tsplot(x, lags=limit,title="AR(1)process")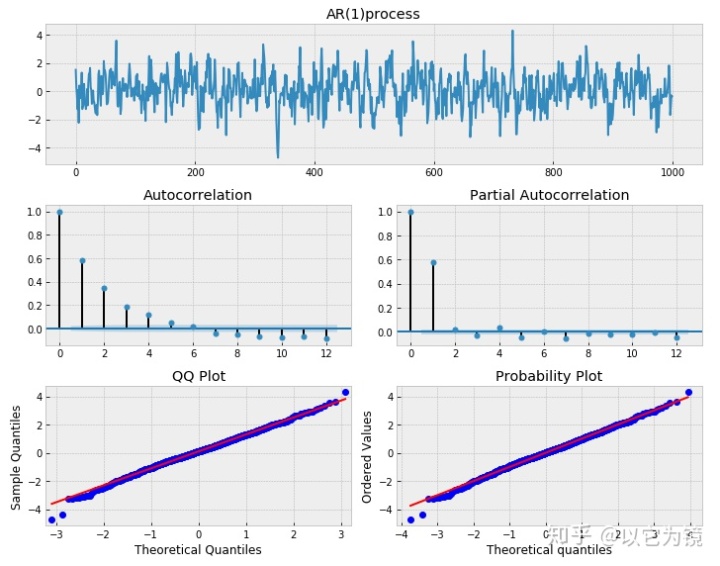
这里涉及模型效果对比,需要逐一对比,过程比较复杂,后面有兴趣的朋友,可以去kaggle上进一步深入研究。
本篇文章销量预测方法,不单单可以预测销量,类似这种时间序列相关的,如每日员工工作量预测、每月员工绩效预测等都可以参考案例一和案例二的方法,举一反三,可以满足大部分日常简单预测;案例三涉及数据挖掘、算法模型等,难度系数较高,有时间可以继续深挖学习。














 413
413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









