







 本文介绍了如何使用Python爬虫获取B站排行榜的视频标题、综合得分、播放量、评论数、UP主名字等信息。通过requests库获取网页内容,结合BeautifulSoup解析HTML,提取所需数据,并进行整合与保存。
本文介绍了如何使用Python爬虫获取B站排行榜的视频标题、综合得分、播放量、评论数、UP主名字等信息。通过requests库获取网页内容,结合BeautifulSoup解析HTML,提取所需数据,并进行整合与保存。
目录
- 写在前文
- 获取网页数据
- 提取数据
- 整合并保存数据
- 运行结果
点击此处,获取海量Python学习资料!
写在前文
在这篇博客中,我们将会从头开始实现完整的python简单爬虫项目。爬虫是一门高深的学问,这里说的简单爬虫是指获取的数据为静态网页数据,选择B站也是因为作者本身也是老二刺猿了,同时B站没有严格的反爬虫措施,适合新手的爬虫练手。由于本人第一次写博客,在编写的过程中难免会出现错误,如有发现错误或者不合理之处,欢迎到评论区留言指正~
获取网页数据
我们要爬取的内容是B站上的热门视频排行榜(全站版)
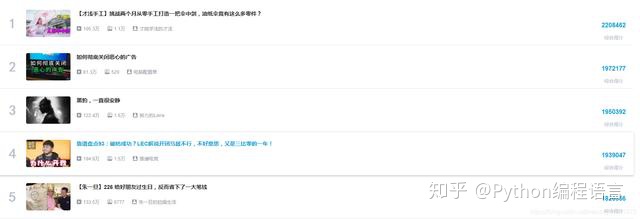
首先我们获取网页内容,为此需要构造网页网址url和请求头heqders。由于我使用的是谷歌浏览器,不同浏览器之间的使用方法可能会有些不同,这里以谷歌浏览器为例。
首先按F12打开控制台,然后依次点击Network、Doc,之后刷新页面,就会出现如下面图展示的内容:
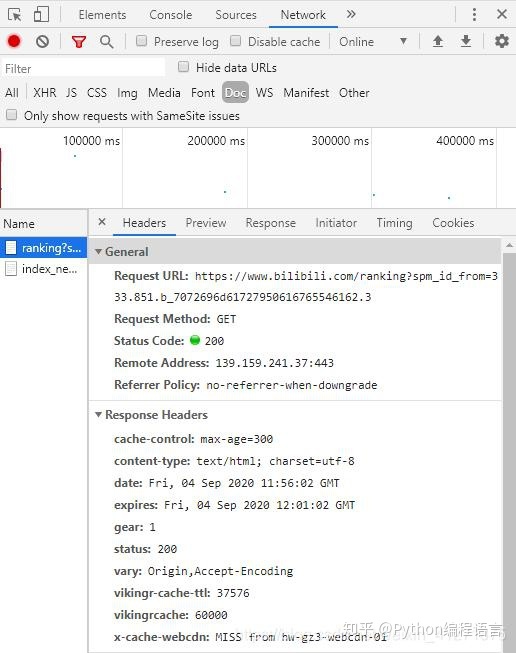
从内容中可以看到,网页的url为:
‘https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3’
接着下拉进度条,最后有一个user-agent,这便是headers需要的参数了。
user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36
在得到了url和headers后,便可以获取网页内容了,本文使用python的requests模块进行爬虫。代码如下:
import requests
url = r'https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'}
data = []
response = requests.get(url,headers=headers)
if response.status_code == 200:
data = response.content.decode('utf-8')
else:
print('网页解析失败')
提取数据
在前面的步骤中,我们利用requests库的get函数成功获取网页数据&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









