







BERT for Joint Intent Classification and Slot Filling
全文链接
https://arxiv.org/abs/1902.10909arxiv.org代码
https://github.com/sliderSun/pynlp/tree/master/nlu/BERT-for-Sequence-Labeling-and-Text-Classificationgithub.com本文提出两个创新点:
1)针对NLU泛化能力差的问题,探索了BERT预训练模型;
2)本文将联合了意图识别和基于bert槽填充模型
模型:
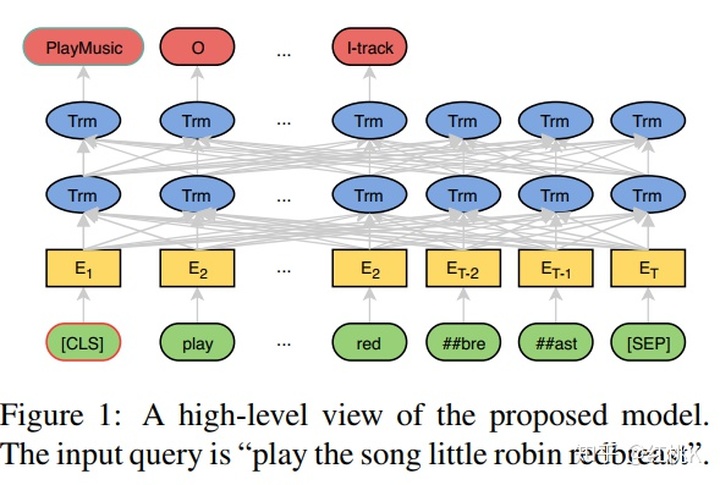
本文主要使用bert的架构,在bert中,[cls]训练后代表着整句话的语义信息。因此使用其作为意图识别的分类输入。使用softmax分类器进行分类:
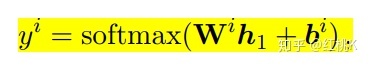
槽位填充除了直接用输出结果进行序列标注,另外还接了一层 CRF改善实验结果。BERT中的输入是使用 WordPiece处理之后的词语,一个词可能会被拆成多个sub-token,比如 “redbreast”被拆成“##red”, “##bre”, “##ast”三部分,而此模型使用的是这些sub-token 中的第一个token作为输入。槽位标记也是使用softmax函数对每一个输出进行分类:
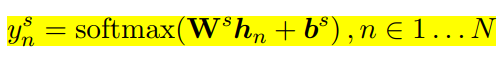
在两者联合训练时,使用cross-entropy作为分类的损失函数:
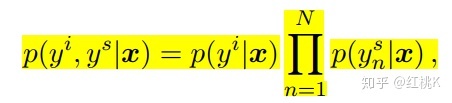
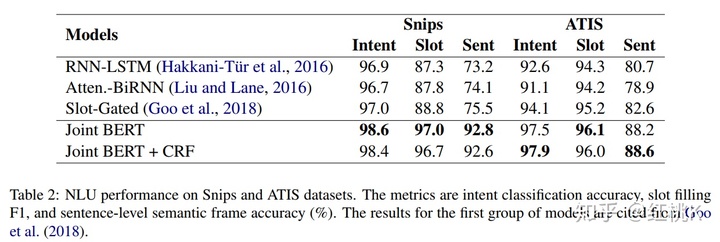
实验结果















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









