






接上文:
1、先注册百度相关吧 https://login.bce.baidu.com/

进入后,看这服务,老多了。
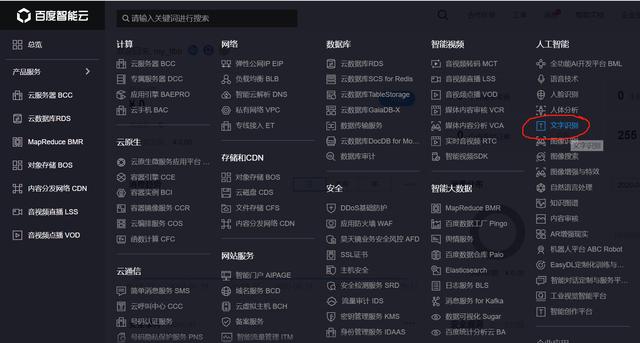
文字识别也提供了不少,免费的就可以了。
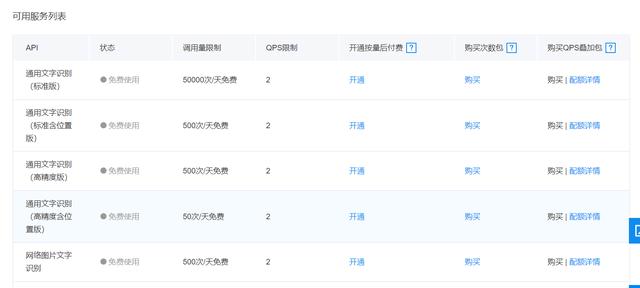
根据提示,选择文字识别,同时创建一个新的应用。在管理应用里 会看见你创建的应用和应用对应的AK和SK
这是百度的示例
# encoding:utf-8import requestsimport base64'''通用文字识别'''request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"# 二进制方式打开图片文件f = open('[本地文件]', 'rb')img = base64.b64encode(f.read())params = {"image":img}access_token = '[调用鉴权接口获取的token]'request_url = request_url + "?access_token=" + access_tokenheaders = {'content-type': 'application/x-www-form-urlencoded'}response = requests.post(request_url, data=params, headers=headers)if response: print (response.json())2、调整软件界面
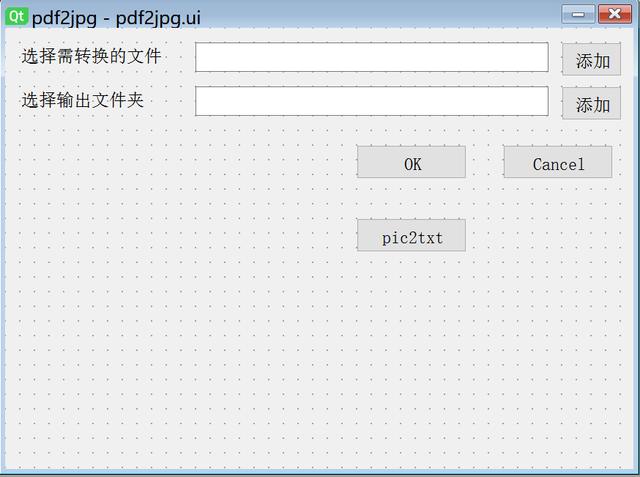
就是要把文本识别出来。但是这种Pdf不是那种。不知最终效果如何,试试再说吧。
3。发现一个问题,对图片进行读取时没按顺序,所在以生成时也应格式化。上一张图。
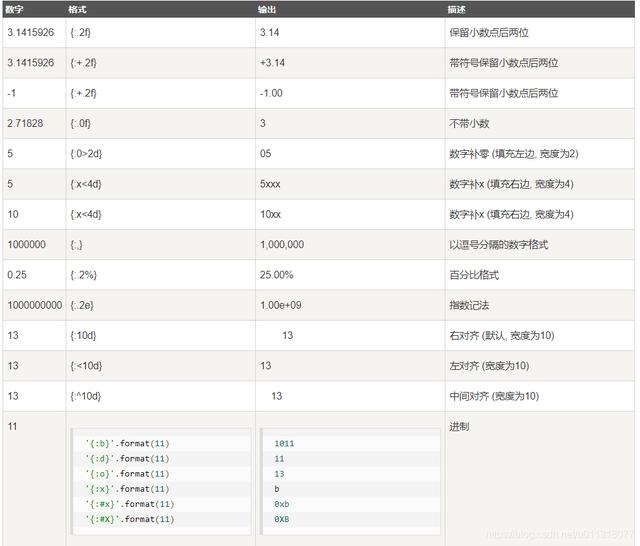
pix.writePNG(folder_path + '/' + 'images_%s.jpg' % pg) # 将图片写入指定的文件夹内pix.writePNG(folder_path + '/' + 'images_%s.jpg' % "{0:03d}".format(pg)) # 将图片写入指定的文件夹内改成三位数字。
这样就成功了。
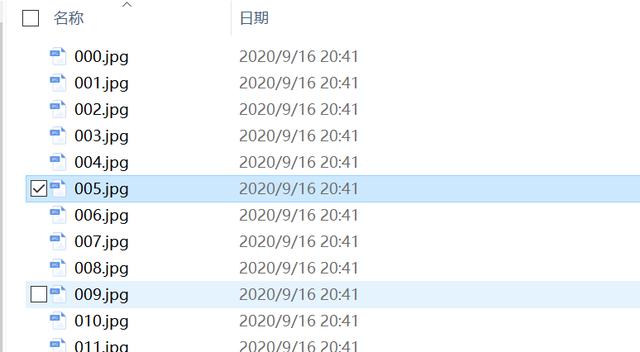
这个样子好用。
好几天了。未完待。。感觉窗口式还不如无窗口式方便。














 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









