







**
昨夜西风凋敝树,独上高楼,望尽天涯路
衣带渐宽终不悔,为伊消得人憔悴。
**
基于urllib库的爬虫实战:
https://github.com/OTZHANG/SpiderBaseByPython/tree/master/venv/Include
基础用法一:get
直接使用get方法发起get请求,返回一个response对象。此处没有设置headers,User-Agent默认使用的是‘python-requests‘,版本为当前requests库的版本,具体可看源码。
url = 'http://www.baidu.com'
resp = requests.get(url)
#def get(url, params=None, **kwargs)
- params可以用来传递url参数,比如:
url = 'http://www.baidu.com'
resp1 = requests.get(url)
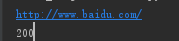
print(resp1.url)
print(resp1.status_code)
param = {'key01':'03'}
url = 'http://www.baidu.com'
resp2 = requests.get(url,params=param)
print(resp2.url)
print(resp2.status_code)
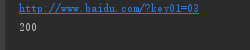
设置了params参数后,会在url后面拼接key和value,典型的get请求方式。
- 给请求设置headers
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24’}
resp1 = requests.get(url, headers=headers)
- 给请求设置cookie
cookies = dict(cookies_are=‘working’)
r = requests.get(url, cookies=cookies)
requests库常用请求发起方法:
requests.get() #常用
requests.post() #常用
requests.put()
requests.delete()
requests.head()
requests.options()
请求的响应内容response:
resp.content # 按照相应原始报文进行显示,不进行编码解析
resp.text #按照指定编码对原始报文进行解析显示,如果未手动指定编码,requests会从响应报文体中获取编码格式进行显示。
resp.json() #requests 内置的json解析器,解析json数据
#获取服务器原始套接字响应
resp.raw
resp.raw.read()
该场景下需要发起请求时指定stream=True
r = requests.get(‘http://www.baidu.com’, stream=True)
#获取响应状态
resp1.status_code
同时request中还有一个内置的状态查询对象
requests.codes.ok

#抛出响应异常
resp.raise_for_status()
重定向
#查询所有一次请求的请求历史和重定向(requests中除了head请求类型外,其他请求都默认开启了重定向)
Response.history()
#是一个 Response 对象的列表,从最老到最近的请求进行排序。
#禁用重定向
allow_redirects=False
r = requests.get(‘http://github.com’, allow_redirects=False)
#head()类型,开启重定向:
r = requests.head(‘http://github.com’, allow_redirects=True)
代理
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)
#最重要的还是使用,学多少用多少,用到了,遇到不会的再回过头来学。















 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









