






如果能完全理解计算机系统以及它对应用程序的影响,那么恭喜你,你走上了一条为数不多的大牛道路。本文继前两篇之后继续深入学习计算机系统中程序的机器级表示;如果对之前的文章感兴趣可以点击阅读:
《CSAPP-1:计算机系统漫游》
《CSAPP-2-信息的表示和处理》
首先,大家都知道的一点,计算机执行的是机器代码,我们平时写的代码,由编译器基于编码规范、目标机器指令集和操作系统惯例经过一系列阶段生成机器代码。 GCC 这个C语言的编译器以汇编代码的形式产生输出,汇编是机器代码的文本表示,给出程序中的每一条指令。然后GCC调用汇编器和链接器,根据汇编代码生成可执行的机器代码。
平时我们都是用高级语言编程,C语言,Java更是如此,因为这样高效,并且比熟悉汇编语言的人写出来的代码可能还要好。那么我们为什么要学习底层的机器代码呢,原因不多说了,知其然,当然还要知其所以然!今天就一起来学习高级语言程序代码、汇编代码、机器代码之间的关系,让你理解程序的整个运行过程和看懂汇编代码;
涉及概念
- IA32,x86-64的32位前身;
- x86-64 是现代电脑中最常见的处理器的机器语言,Intel 处理器系列俗称 x86;
- 32位的机器只能使用大概4G(2^32字节)的随机访问存储器,当前的64位机器能够使用多大256TB(2^48字节)的内存空间(x86-64中,高16位必须是0);
程序编码
这里主要是要C程序演示,使用gcc调用预处理器扩展源代码,插入所有 #include 命令指定的文件,并扩展所有用 #define 生命指定的宏。其次,编译器生成源文件的汇编代码,接下来汇编器会将汇编代码转化成二进制目标代码文件。目标代码是机器代码的一种,包含所有指令的二进制表示,但还没有填入全局值的地址。最后链接器将目标代码文件与实现库函数(例如 printf ) 的代码合并,并产生最终的可执行代码代码文件。
机器级代码
机器级编程,设计两种重要的抽象:
- 指令集体系结构(ISA),来定义机器级程序的格式和行为,定义了处理器的状态、指令格式,以及每条指令对状态的影响。
- 程序使用的内存地址是虚拟地址,提供的内存模型看上去是一个非常大的字节数组,存储器系统的实际实现是将多个硬件存储器和操作系统软件组合起来;
x86-64的机器代码和原始的C代码差别非常大,隐藏了一些处理器的状态:
- 程序计数器(x86-64中用 %rip 表示),给出将要执行下一条指令的内存中地址。
- 整数寄存器文件,可以储存地址(对应C语言的指针)或整数数据。
- 条件码寄存器,保存着最近执行的算术或逻辑指令的状态信息,可以实现if和while语句。
- 一组向量寄存器,可以存放一个或多个整数或浮点数值。
这里就给出一个重要的概念:
程序内存包含:程序的可执行机器代码,操作系统需要的一些信息,用来管理过程调用和返回的运行时栈,以及用户分配的内存块(比如 malloc库函数分配的)。
代码示例
这里大家主要看下C程序代码是如何转换为机器执行的目标代码的:
long mult2(long,long);
void multstore(long x, long y, long *dest) {
long t = mult2(x, y );
*dest = t;
}在命令行使用 -S 选项,就能看到C语言编译器产生的汇编代码(这里只运行编译器产生汇编代码,通常情况下会继续调用汇编器产生目标代码文件):
gcc -Og -S mstore.c
汇编代码文件包含各种声明,这里取出其中对应的机器指令(增加相关注释):
// void mulstore(long x, long y, long *dest)
// x in %rdi, y in % rsi, dest in %rdx
multstore:
pushq %rbx save %rbx
movq %rdx, %rbx Copy dest to %rbx
call mult2 Call mult2(x,y)
movq %rax, (%rbx) Store result at *dest
popq %rbx Restore %rbx
ret return 上面代码中每一行都对应一条机器指令,比如pushq 指令表示应该将寄存器 %rbx 的内容压入程序栈中。
如果使用:gcc -Og -c mstore.c GCC会编译并汇编该代码,产生目标代码文件mstore.o ,它是二进制格式的,所以无法直接查看。
如果要查看机器代码文件的内容,我们可有使用反汇编器(disassembler):
[root@localhost ~]# objdump -d mstore.o
0000000000000000 <multstore>:
0: 53 push %rbx
1: 48 89 d3 mov %rdx,%rbx
4: e8 00 00 00 00 callq 9 <multstore+0x9>
9: 48 89 03 mov %rax,(%rbx)
c: 5b pop %rbx
d: c3 retq 左边可以看到14个十六进制字节值分成了若干组,每组1~5个字节。每组都是一条指令,左边是等价的汇编语言。
上面我们只是演示了如何生成目标代码文件,可是它依旧不是实际可被机器执行的,需要在运行链接器,而目标代码文件中必须含有一个main 函数,如下 文件 main.c:
#include <stdio.h>
int main() {
long d;
multstore(2, 3, &d);
printf("2 * 3 --> %dn", d);
return 0;
}
long mult2(long a, long b) {
long s = a * b;
return s;
}然后使用如下方法生成可执行文件 prog:
gcc -Og -o prog main.c mstore.c文件变成了8655个字节,因为它不仅包含了两个过程的代码,还包含了用来启动和终止程序的代码,以及用来和操作系统交互的代码,我们也反汇编 prog文件:
[root@localhost ~]# objdump -d prog
0000000000400560 <multstore>:
400560: 53 push %rbx
400561: 48 89 d3 mov %rdx,%rbx
400564: e8 ef ff ff ff callq 400558 <mult2>
400569: 48 89 03 mov %rax,(%rbx)
40056c: 5b pop %rbx
40056d: c3 retq
40056e: 66 90 xchg %ax,%ax上面只抽取出这一段(建议大家都实际操作下,大概能看明白整个链接器都干了什么,最后的可执行代码是什么样子的),这段代码与 mstore.c 反汇编产生的代码几乎一模一样,其中主要的区别是左边列出的地址不同--链接器将这段代码的地址移到了一段不同的地址范围中。第二个不同是链接器填上了 callq 指令调用函数 mult2 需要使用的地址。
访问信息
一个x86-64 的中央处理单元(CPU)包含一组16个存储64位值的 通用目的寄存器。它们的名字都以%r开头:

操作数指示符
上面的大多数指令都有一个或多个操作数,指示出执行一个操作中要使用的源数据值,以及放置结果的目的位置。x86-64 中, 源数据值可以是常数或是寄存器或内存种中读取。结果可以存放在寄存器或内存中。
如上所述,各种不同的操作数可被分为三类:
- 立即数,用来表示常数值,书写方式为
$后面跟一个标准C表示的整数,如:$-577; - 寄存器类型,它表示某个寄存器的内容,下图中我们用 $ra$ 来表示任意寄存寄存器, 用引用 R[ $ra$ ] 来表示它的值,这是将寄存器集合看成是一个数组R;
- 内存引用,根据地址访问某个内存位置,用 $ M_b[Addr] $ 表示对存储在内存中从地址Addr开始的b个字节值的引用。
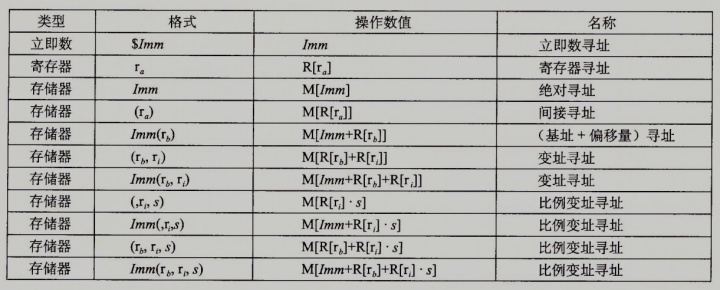
如上图所示,有多种不同的寻址模式,允许不同形式的内存引用。$ Imm(rb, ri, s)$ 表示的是最常用的形式; 这样的引用有四个组成部分: 一个立即数偏移 $Imm$ , 一个基址寄存器 $rb$ , 一个变址寄存器 $ri$ 和一个比例因子 $s$,这里需要注意 s 必须是1、2、4、8。 基址和变址寄存器都必须是64位寄存器。 有效地址被计算为: $ Imm + R[r_b] + R[r_i] * s$ 。
数据传送指令
在机器中最常用的一个指令是将数据从一个位置复制到另一个位置。
下面列出最简单形式的数据传送指令--MOV类:
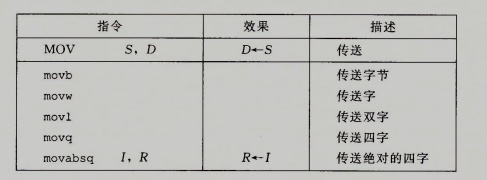
x86-64中加了一条限制,即传送指令的两个操作数不能都指向内存位置,也就是将一个值从一个内存位置复制到另一个内存位置需要两条指令:
- 将源值加载到寄存器中;
- 将寄存器值写入目的的位置;
数据传送示例
下面写了一个数据交换函数,即有C代码,也有GCC 产生的汇编代码,可以查看使用数据传送指令。
C代码:
long exchange(long *xp, long y)
{
long x = *xp;
*xp = y;
return x;
}汇编代码,已经加了注释:
// long exchange(long *xp, long y)
// xp in %rdi, y in %rsi
exchange:
.cfi_startproc
movq (%rdi), %rax get x at xp. Set as return value
movq %rsi, (%rdi) Store y at xp
ret Return
关于上面的汇编代码,需要注意两点:
- 我们看到的C语言所谓的“指针”其实就是地址。间接引用指针就是将指针放在一个寄存器中,然后在内存引用中使用这个寄存器。
- 像x这样的局部变量通常是保存在寄存器中,而不是内存。访问寄存器比访问内存要快得多。
压入和弹出栈数据
栈相信大家都不陌生,它的特性是:后进先出,弹出的值永远是最近被压入而且仍然在栈中的值。在x86-64 中,程序栈存放在内存中某个区域,栈向下增长,栈顶元素的地址就是所有栈中元素地址中最低的。栈指针%rsp保存着栈顶元素的地址。

- pushq 指令的功能是把数据压入到栈上
- popq 指令是弹出数据
将一个四字值压入栈中,需要执行两步操作,首先栈指针减8,然后将值写到新的栈顶地址,例如:
指令 pushq %rbp 等价于:
subq $8,%rsp // Decrement stack pointer
movq %rbp,(%rsp) // Store %rbp on stack下面的图更能说明执行压栈和弹出时,是如何执行指令的:

算术和逻辑操作
x86-64定义了一些整数和逻辑操作,大多数操作都分成了指令类,如下图所示:
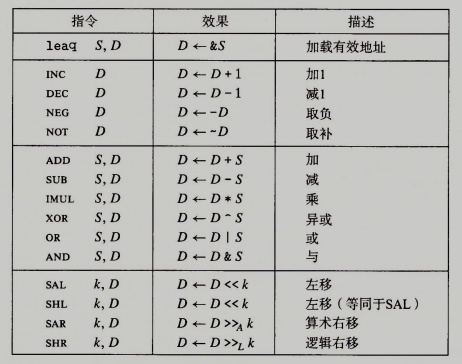
这些操作被分为四组: 加载有效地址、一元操作、二元操作和移位。二元操作有两个操作数,而一元操作有一个操作数。
加载有效地址
加载有效地址指令 leaq 实际上是movq 指令的变形。它的指令形式是从内存读取数据到寄存器,但它实际上根本没有引用内存,它不是从指定的位置读入数据,而是将有效地址写入到目的操作数。这条指令可以为后面的内存引用产生指针。而且可以简洁的描述普通的算术操作。例如,如果寄存器%rdx 的值为x,那么指令 leaq7(%rdx,%rdx,4),%rdx将设置寄存器%rdx的值为5x+7。
下面我们写一个C程序,来学习leaq在编译出的代码中的使用,看看下面这个C程序:
long scale(long x, long y, long z)
{
long t = x+4*y+12*z;
return t;
}编译时,该函数的算术运算以三条leaq指令实现,就像右边注释说明的那样:
// long scale(long x, long y, long z)
// x in %rdi,y in%rsi, z in %rdx
scale:
leaq (%rdi,%rsi,4), %rcx // x + 4*y
leaq (%rdx,%rdx,2), %rax // z + 2*z = 3*z
salq $2, %rax // 3*z<<2=12*z,左移
addq %rcx, %rax // x+4*y + 12*z
ret
循环
这里在列举一个我们代码开发中常用的循环,其实在汇编器中没有对应指令的存在,GCC汇编器产生的循环代码主要基于两种循环模式。首先看下do-while 循环。
- do-while 循环
一般常见的形式如下:
do
body-statement
while(test-expr);上述这种通用形式会被翻译为如下条件和goto语句:
loop:
body-statement
t = test-expr;
if(t)
goto loop;接下来为大家举个例子,用do-while循环来实现一个数字n的阶乘函数,即 n!。 这个函数只计算 n > 0 时的阶乘值。
long fact_do(long n)
{
long result = 1;
do{
result *= n;
n = n-1;
} while (n > 1);
return result;
}汇编代码:
// n in %rdi
fact_do:
movl $1, %eax // set result = 1
.L2: // loop
imulq %rdi, %rax // computer result *= n
subq $1, %rdi // Decrement n
cmpq $1, %rdi // Compare n:1
jg .L2 // if >, goto loop
rep; ret // return- while循环
while语句的通用形式如下:
while(test-expr)
body-statement翻译到goto代码:
goto test;
loop:
body-statement
test:
t = test-expr;
if(t)
goto loop;同样的,我们来看一个n的阶乘n!,不同于上面的是这个函数可以计算 0!=1。
C代码:
long fact_while(long n)
{
long result = 1;
while(n > 1) {
result *= n;
n = n - 1;
}
return result;
}对应的汇编(带注释):
// n in %rdi
fact_while:
movl $1, %eax // set result = 1
jmp .L2 // Goto test
.L3: //loop
imulq %rdi, %rax // Compute result *= n
subq $1, %rdi //Decrement n
.L2: // test
cmpq $1, %rdi // Compare n:1
jg .L3 // if >, goto loop
rep ret // Return过程
过程其实是软件中一种很重要的抽象。就像我们在写代码时,一个函数,传进去入参和一个可选的返回值定义了某个功能。不同的语言过程的形式多样,比如函数、方法、子例程、等等。
机器对过程的实现提供了下面几个支持,为了方便大家理解,例如:过程P调用过程Q,Q执行后返回到P,这些动作包含如下一个或多个机制:
- 传递控制。在进入Q时,PC要设置为Q代码的起始地址,然后在返回时,要设置为P调用Q后那条指令的地址;
- 传递数据。P必须向Q提供一个或多个参数,Q必须向P提供一个返回值;
- 分配和释放内存。Q在执行时需要为局部变量分配空间,当返回时,销毁这些空间;
运行时栈
下面这副图,很直观的表示了运行时栈的通用结构。可以看到栈用来传递参数、存储返回信息、保存寄存器以及局部存储等。(Java方法调用即是这个结构)
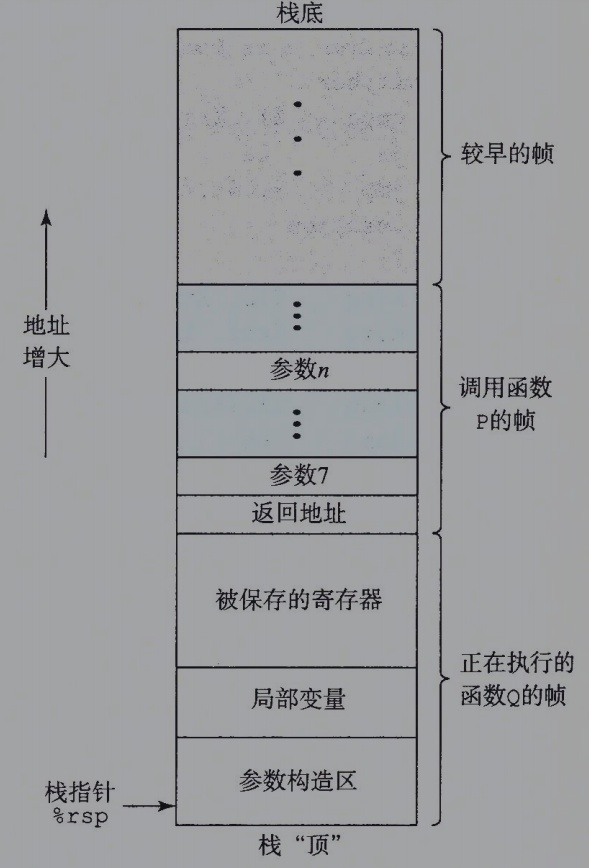
我们可以看到,过程的调用被划分为一个个栈帧,本文前面列出的寄存器部分,可以看到寄存器最多可以保存6个参数,如果P向Q传递的参数超过6个,这个时候就会在栈帧上分配,即将从第7个参数开始P将其保存到自己的栈帧上。
数据传送
下面展示寄存器最多传递6个参数,它们是怎么分配的。其实就是按照参数列表的顺序分配寄存器,如果参数小于64位,则通过访问寄存器适当的部分访问,例如,如果一个参数是32位的,那么可以用%edi来访问它。
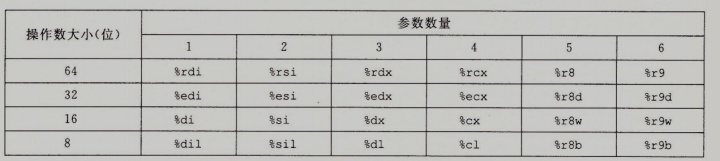
上面你说了那么多的理论,下面我们具体来看一个参数传递的示例,掌握了这个,你就会对平时我们代码中的函数调用在计算机操作系统层面是如何解析执行的。
- C代码
void proc ( long a1, long *a1p,
int a2,int *a2p,
short a3,short *a3p,
char a4, char *a4p)
{
*a1p += a1;
*a2p += a2;
*a3p += a3;
*a4p += a4;
}- 生成的汇编
// a1 in %rdi
// a1p in % rsi
// a2 in %edx
// a2p in %rcx
// a3 in %r8w
// a3p in %r9
// a4 at %rsp+8
// a4p at %rsp+16
proc:
movq 16(%rsp), %rax
addq %rdi, (%rsi)
addl %edx, (%rcx)
addw %r8w, (%r9)
movl 8(%rsp), %edx
addb %dl, (%rax)
ret可以看到,上面有多个 不同类型的参数,参数1~6通过寄存器传递,7~8通过栈传递。
至此,程序的函数调用以及常规运算在计算机系统中是如何被解释执行的,相信你一定有自己的理解了。由于篇幅原因,感兴趣的小伙伴可以在想下 递归又该如何实现呢 ?
回顾
到这里基本上已经学习了日常代码在计算机中是如何被解析运行的,以及常见的代码被翻译成汇编代码后相信大家也能可以看懂的。我觉得汇编代码我们只要能基本上看懂就可以了,毕竟现在也没有人直接写汇编,除非从事底层系统开发者。 大家可以思考下数组在内存是如何表示的,程序 又是如何引用其中的元素呢? 有兴趣的朋友可以关注加我继续交流哈!
建议大家有时间的话一定要将文章的示例动手写一遍,相信一定会对程序时如何在计算机上运行起来的有更深一步的了解。 不付出又怎么会有回报,加油。
欢迎关注我的公众号:罗小黑爱编程。 回复666 领取Java进阶指南
【本文最先发布于此站,转载请注明来源】:
爱上编程coderluo.top如果对文章感兴趣,可以微信关注我,一起交流学习:
















 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









