





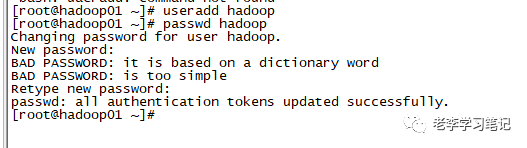
接昨天的文章,我们今天继续完成完全分布式集群的搭建,在开始搭建之前我们需要新建一个普通用户,因为安装包一般都放在普通用户的家目录下,不会放到root用户的家目录下。
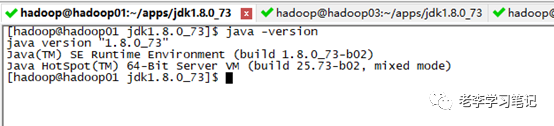
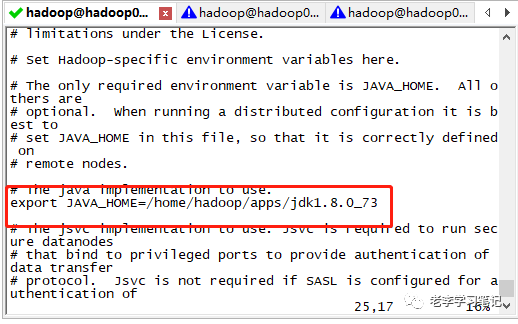
接下来开始安装JDK
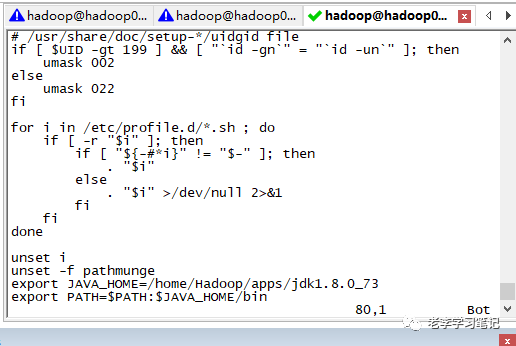
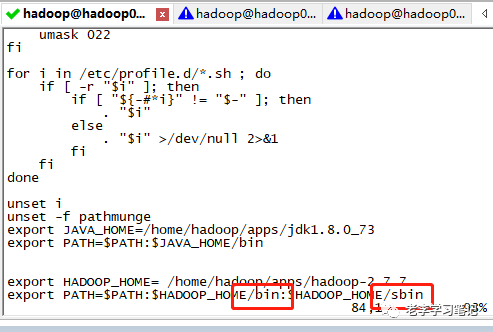
配置环境变量

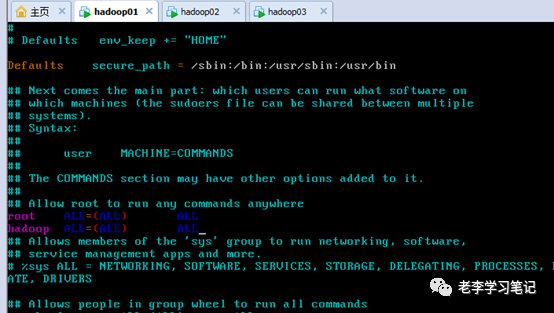
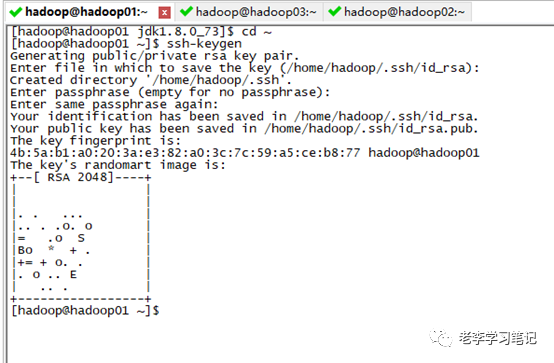
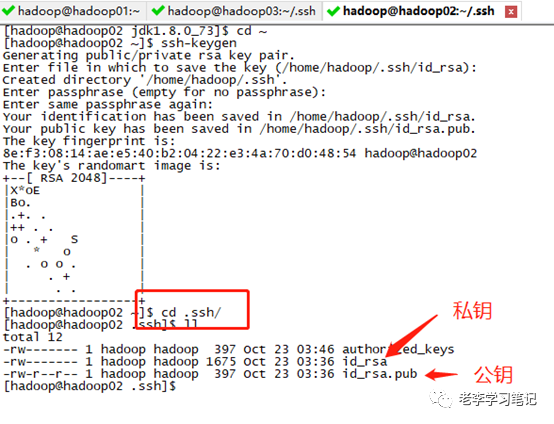
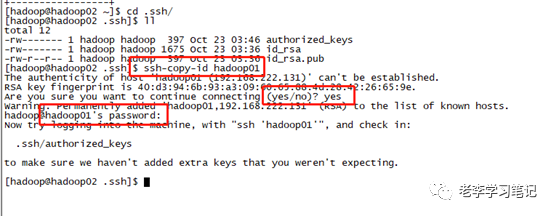
配置免密登陆

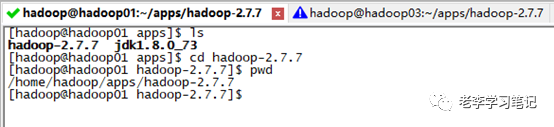
安装hadoop
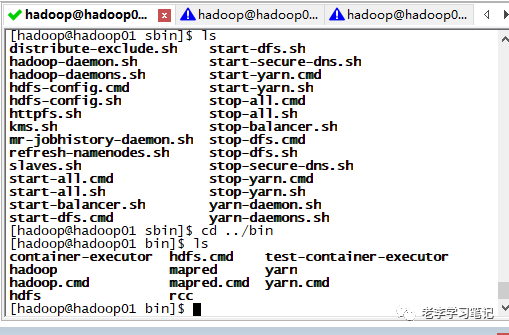


修改Hadoop配置文件(重点来了!!敲黑板)
2、然后配置hadoop的核心配置文件core-site.xml,在文档的中新增如下内容:
<property> <name>fs.defaultFSname><value>hdfs://hadoop01:9000value>property> <property> <name>hadoop.tmp.dirname><value>/home/hadoop/data/hadoopdatavalue>property>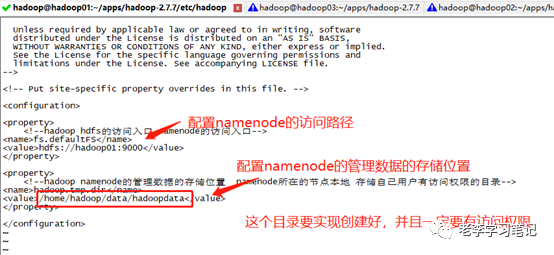
3、接下来配置hdfs-site.xml文件,我们在文件中添加如下内容:
<property><name>dfs.namenode.name.dirname><value>/home/hadoop/data/hadoopdata/namevalue><description>namenode管理数据存储目录description>property> <property><name>dfs.datanode.data.dirname><value>/home/hadoop/data/hadoopdata/datavalue><description>datanode的数据存储目录 真实数据description>property> <property><name>dfs.replicationname><value>2value><description>数据存储副本个数description>property> <property><name>dfs.secondary.http.addressname><value>hadoop03:50090value><description>secondarynamenode运行节点的信息,和 namenode 不同节点description>property>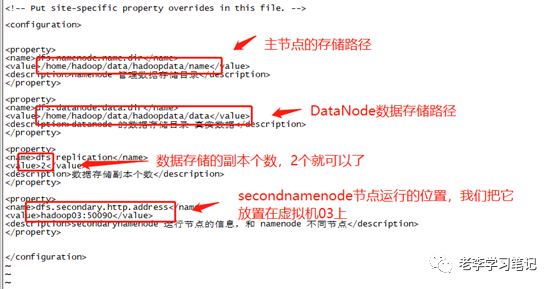
<property><name>mapreduce.framework.namename><value>yarnvalue>property>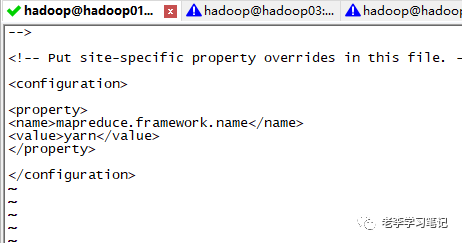
<property><name>yarn.resourcemanager.hostnamename><value>hadoop02value>property><property><name>yarn.nodemanager.aux-servicesname><value>mapreduce_shufflevalue><description>YARN集群为 MapReduce 程序提供的 shuffle 服务description>property>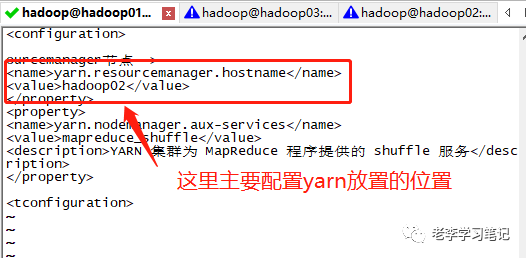
6、最后配置datanode从节点,编辑slaves文件并添加所有的虚拟机,如图:

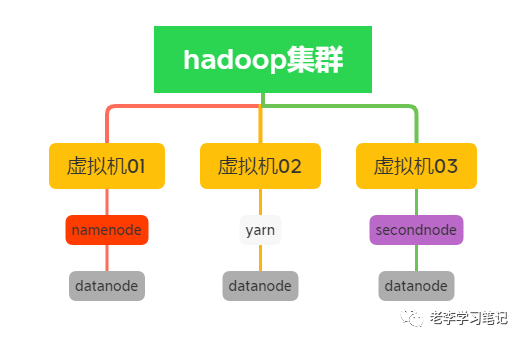
将hadoop的配置完成的安装包远程发送到其他节点
执行如下命令:

格式化 hdfs

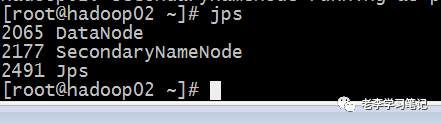
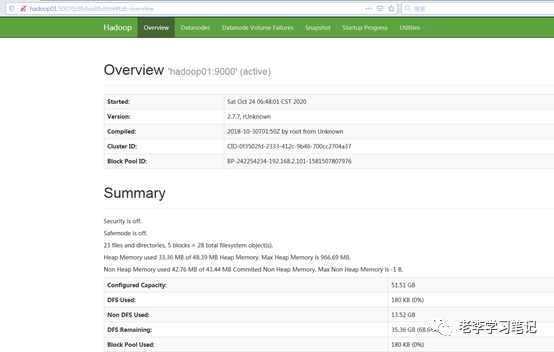
启动hadoop
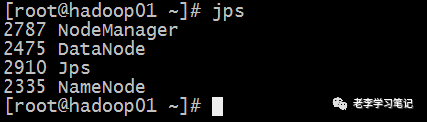















 6488
6488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









