





图像描述(image caption)
顾名思义,图像描述是指以图像为输出,通过模型和计算来输出对应图像的自然语言描述。如下图所示,输出的自然语言是“A person riding a motorcycle on a dirt road.“ 。这一领域是结合了人工智能两大方向:计算机视觉和自然语言处理。从2015年的论文:Show and Tell开始,近几年图像描述领域开始快速发展,逐渐加入attention机制、visual sentinel哨兵机制、对CNN的改进、利用强化学习来训练模型以及利用目标检测技术来改进模型,本文将通过对应代表性论文逐一讲解。
Show and Tell: A Neural Image Caption Generator 2015
这篇文章普遍被看作是图像描述进入深度学习时代的经典之作,其实现原来很简单,利用了机器翻译的思想,现将图像提取出抽象的特征,再将特征作为输入来生成自然语言,如下图: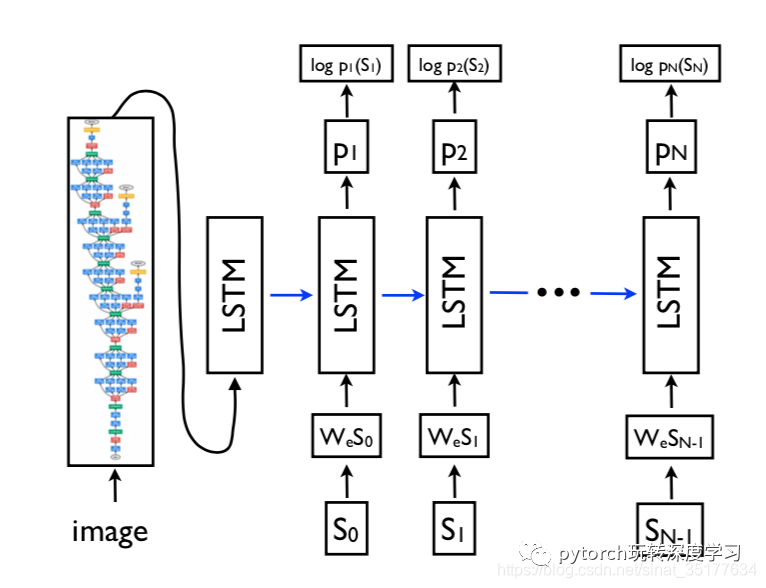
整个模型由两部分组成CNN模型和LSTM模型,第一步,将图像输入到CNN模型中,得到图像的特征,再输入到LSTM模型中,得到相应的描述。可以看到这种方法简单粗暴,算是利用CV和NLP的结合对image caption的一次尝试,其模型的优化目标如下: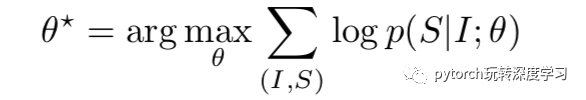
其中I代表图像,S代表对应的描述,θ代表模型的参数。在给定图像和参数时使生成描述S的概率最大,从而得到参数,以此来训练模型。
论文链接:https://arxiv.org/pdf/1411.4555.pdf
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention 2016
Show and Tell仅仅将图像抽象成单一的特征,而没有考虑到图像的空间特性。同时在生物视觉中,我们人眼看到东西更多的针对图像中的某一区域来来理解,基于这一特性,这篇论文提出了attention机制。
具体来说,将图像生成的描述的每一个单词都对应到图像的某一个区域,如图:
在对这一图像的描述中frisbee单词对应图像中高亮的部分,其他的单词同样对应这相应的区域。
模型如下: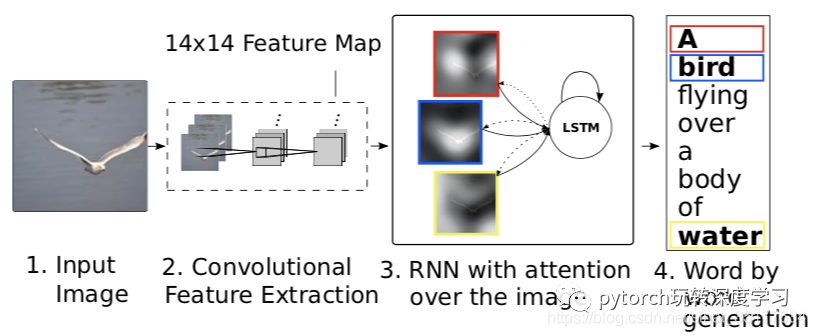
本文提到了两种attention机制:soft-attention和hard-attention,这里以soft-attention为例,相对更好理解。
先对图像使用CNN来提取特征,这里要利用相对较浅层的特征,因为要对应更多的区域,不能向Show and Tell中使用深层的更加抽象的特征。在生成每一个单词时,先使用深度网络来计算各个区域对应的权重,再将权重乘上对应区域的特征,将结果输入到LSTM来得到这一时刻的单词,知道生成整个句子。
由于各个区域的权重而不相同,因此叫做soft-attention,而hard-attention是将每个单词对应到固定尺寸的区域,如图:
这种attention机制更加符合生物视觉的机制,因此得到的效果也比show and tell更好,但缺点是每个单词都强制对应一个区域,比如a,本来没有在图像上具体的意义但依然对应区域,这也是下一篇论文要解决的问题。
论文链接:https://arxiv.org/pdf/1502.03044.pdf
Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning 2017
上文提到原始的attention机制强制将每一个单词对应到图像的某一区域,甚至那个单词没有对应图像的意义。本文提出了Sentinel哨兵机制,在生成每个单词时先计算这个单词是属于visual word还是context word的概率,即和图像的关联性有多大,再根据权重来计算总体的特征,具体将稍后讲解,如图: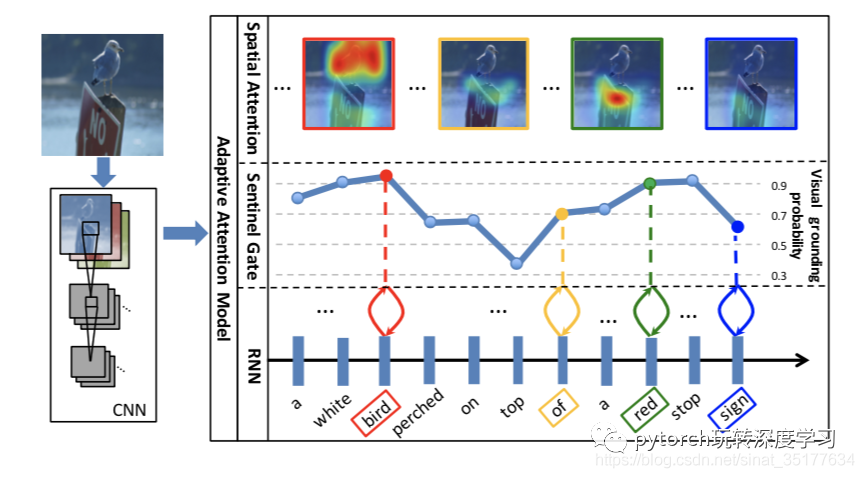
可以看到在生成A white bird perched on top of a red stop sign这一描述时,bird和red等单词对应作为visual word的概率较高,而a of等单词作为visual word的概率较低,比较符合直观上的意义。具体模型如下: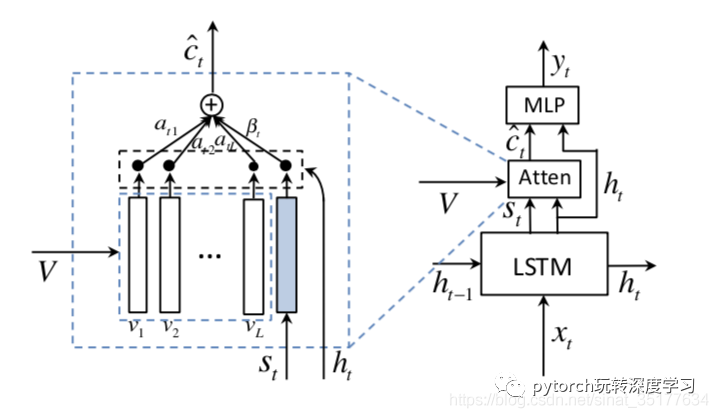
其中V代表图像的特征,S代表哨兵,用来计算单词属于visual word的概率,比较有意思的是在计算概率s时,可以将S抽象成一个区域,和图像中真正的L个区域一块计算: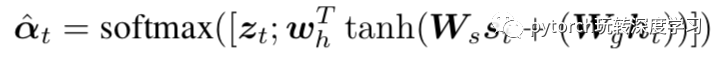
这样计算出概率向量,向量的最后一个元素是属于context word的概率,再计算加权后的图像特征: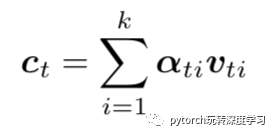
最后加上哨兵计算的概率: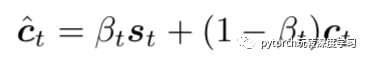
这样就得到了最终的特征,用这个特征作为输入,输入到LSTM模型来生成这一时刻的单词,直到生成完整的句子。
上述三篇论文个人理解是图像描述个一个阶段:attention机制,并且考虑使用图像attention的概率,但这些模型都是对LSTM模型的改进,没有对CNN模型加以处理,下一篇文章将从CNN着手来解决image captiong的问题。
论文链接:https://arxiv.org/pdf/1612.01887.pdf
SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning 2017
上述的文章都是在生成描述阶段对模型进行改进,而这篇文章从CNN入手,分析CNN的特性,包括其空间性、多通道和多层级。除了使用之前提到的对feature map的spatial attention外,本文还加入了对通道(channel)的attention:
如图,在将要预测cake这个单词时,先对模型做channel-wise attention,对conv5_3层可视化了attention度最高的三个通道,在conv5_4层也可视化了attention度最高的三个通道。最后将CNN的处理后的特征输入到LSTM模型,预测出单词cake。我们知道CNN中每个channel提取的特征不同,每个channel有着特定的意义,因此这种channel-wise attention可以看作是对图像的语义选择。
文章对CNN的改进一共包括两部分,对每层进行spatial attention和channel-wise attention,具体的流程图如下: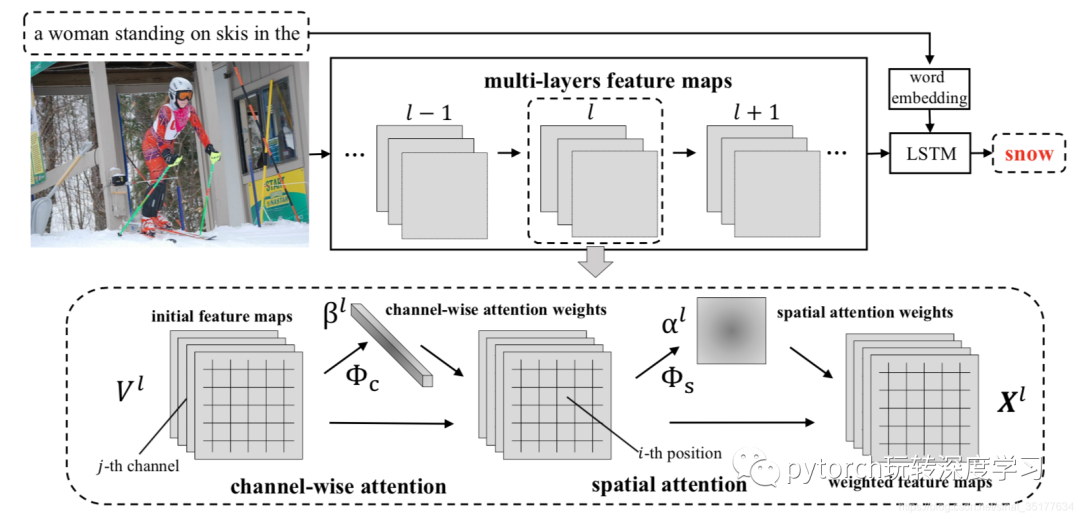
如对第l层进行这两种attention,先得到对每个channel的权重,对所有的feature map进行加权,得到新的feature maps,再计算得到spatial attention和上述几篇文章的attention机制类似,在对新的feature maps加权,得到最终的结果X。将X作为下一层的输入。当然可以对CNN中所有的层都进行这样两种attention的操作,但作者的实验表明,过多的层将会导致过拟合,对两层进行操作效果较好,同时由于这两种attention计算权重可以的相互独立的,因此两者的顺序可以颠倒,作者实验表明,C-S这种顺序在大部分情况下是最好的结果。
论文链接:https://arxiv.org/pdf/1611.05594.pdf
Self-critical Sequence Training for Image Captioning 2017
这篇文章更多的是介绍了一种新的训练模型的方法,在传统的image caption训练方法中主要存在两个问题:(1)exposure bias:在测试时,生成的单词要依赖于之前生成的单词,这样会导致误差的累积。(2)模型在训练时使用的是交叉熵损失,但在评估时使用的是各种既定的metrics,这导致了训练和评估结果的不匹配。针对这两个问题作者提出了一种新的训练模型方法,直接使用metrics作为损失来训练模型,但是metrics每个准确的参考,即无法使用监督学习的返乡传播算法来训练,因此作者使用了强化学习的方法来训练模型。流程图如下: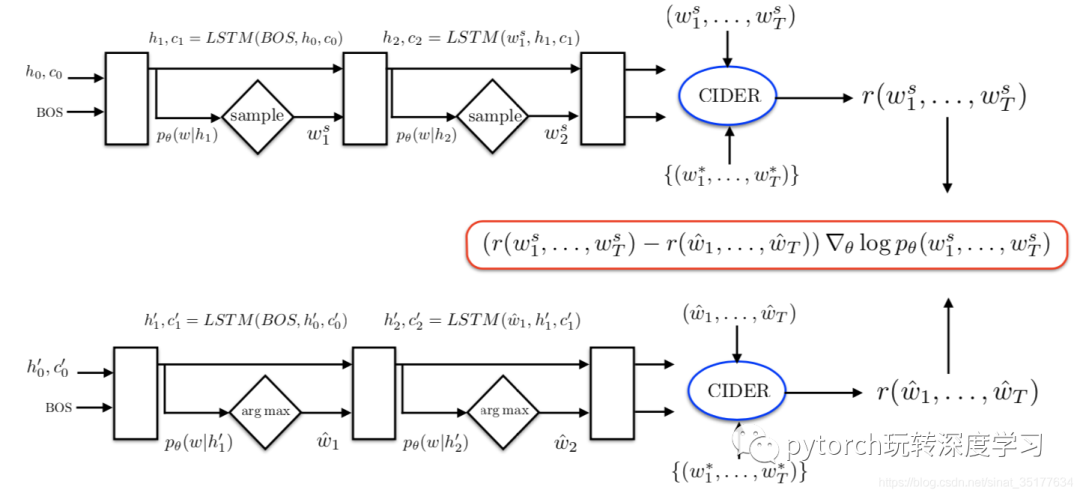
在整个强化学习的训练过程中各个主体包括:
agent:LSTM
environment: words and image features
policy: 模型中的参数
action: prediction of the next word
state:cells and hidden states, attention weight
reward: CIDEr (在生成整个句子后才有反馈)
先看流程的下半部分:LSTM通过greedy decoding来生成一个baseline句子,即在生成单词时选择概率最大的,同时用到Beam search,即选取前N个概率最大的句子作为baseline。再看流程图的上半部分,在每个单词生成时采用sample采样的方法来生成句子,再和baseline比较,再使用策略梯度来更新模型,即抑制分数在baseline下的句子生成,激励生成分数在baseline上的句子,但是实验发现使用greedy decoding生成的句子分数已经很好了,很少有使用sample生成的句子能超过baseline。实验也表明用这种强化学习训练模型的方法比使用传统训练方法的效果更好。
论文链接:https://arxiv.org/pdf/1612.00563.pdf
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering 2018
接下来这两篇文章都使用的object detection技术,基于的生物视觉理论是人类在观察一幅图像时并不是逐个区域来观察的,而是针对图像中的物体和它们之间的关联来描述句子。因此,这篇文章基于这个理论先对图像进行目标检测来将图像划分出k个目标区域(Bottom-Up),再对k个区域来进行attention机制(Top-Down),最后生成描述。这篇文章还有关于VQA的研究,但不是本文重点,我们主要讨论image caption的内容,如图:
上图左边是传统的方法,对图像进行均匀划分区域,右边是使用object detection后选取的区域。
这篇文章使用的object detection方法是faster R-CNN,同时他还顺便得到了对每个区域简单的描述,包括attribute class和object class,虽然在之后的image caption中没有用到,如图:
在image caption阶段,仅仅使用了k个区域的提取的特征,同时在描述生成阶段作者提出了新的LSTM结构,使用了两层的LSTM,将生成attention权重和生成单词的LSTM分开,同时它们之间的输入还有关联: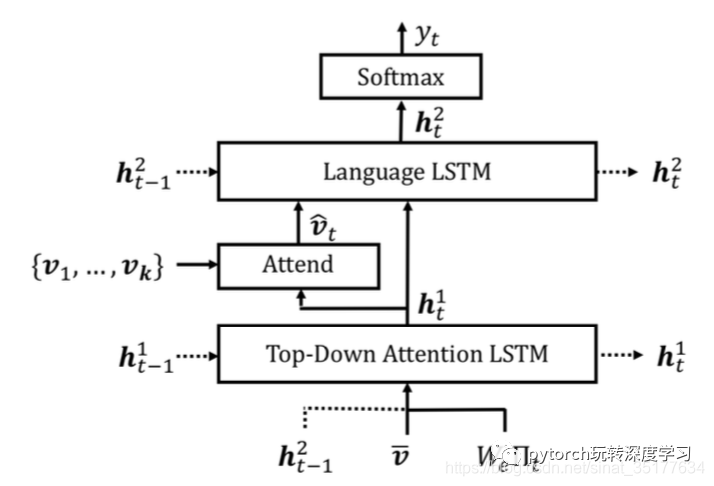
如图,在Attention LSTM中输入了language LSTM上一时刻的隐含变量得到k个区域的权重,再对k个区域加权得到的特征和这一时刻Attention LSTM的隐含变量作为language LSTM的输入得到最终的预测单词。同时,作者在进行训练时用到了上一篇文章的SCST方法。这种两层的LSTM结构同样适用于传统的CNN均匀划分区域的方法,同时实验表明单独使用这种结构同样对image caption的效果有提升,当然即使用object detection(bottom-up)和top-down的方法效果最好。
论文链接:https://arxiv.org/pdf/1707.07998.pdf
Neural Baby Talk 2018
这篇文章虽然也用到了目标检测技术,但和上一篇文章的思想不同,他借鉴了之前baby talk方法的模版思想,分成两个阶段,在第一阶段先生成有空缺的模版句,第二阶段使用图像中的目标(object)来填上空缺,最终得到完整的句子。值得一提的是这篇文章的作者和上述adaptive attention的作者相同,可以看作是使用目标检测对上一篇文章的扩展,思路如下图: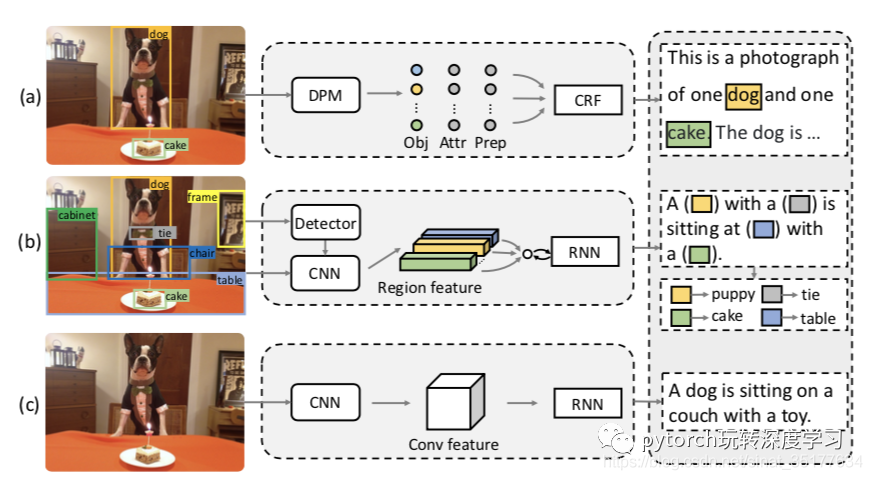
图中a,代表原始方法,b是本文提出的方法,c为传统的image caption方法。
具体流程图如下: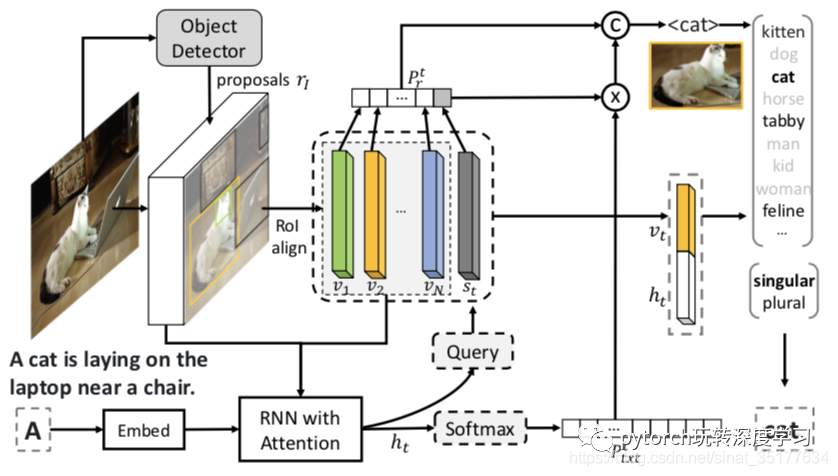
在第一阶段,使用目标检测检测出N个目标区域,在预测单词时,同样分成visual word和context word,context word关联一个虚拟的区域,计算这N+1个区域的概率向量,如果是context word对应的区域概率最大就是和目标无关的单词,直接预测,若是和目标相关的单词则留出空缺。在第二阶段要对目标词进行精细化处理才能填入句子,单复数和更精细的种类,直接使用MLP就可以得到,最终得到句子。
本文没有使用强化学习的训练方法,目标函数如下: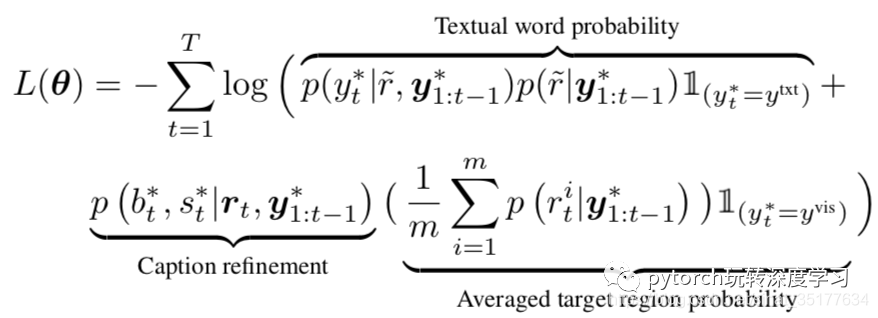
分为context word的损失和visual word的损失。
本文使用的目标检测方法是faster-RCNN,但使用不同的方法得到的句子也不相同。在实验阶段,除了标准的image caption评估,作者还提出了两个更加复杂的评估,一种是在测试集中加入原本存在于训练集的物体,但组合方式不同。第二种是测试集中直接包含训练集中不存在的物体来生成描述,实验表明在这三种情况下,本文的方法均比较好。















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









