





以下内容主要参考: 《An introduction to statistical learning-with applications in R》James et al. 《统计学习导论——基于R语言的应用》王星 等译 |
【逻辑斯谛回归(logistic regression)】
逻辑斯谛回归对响应变量Y属于哪一类的概率建模,而不是直接对响应变量Y建模。逻辑斯谛函数(logistic function):
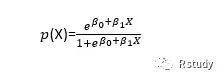
对任意X,p(X)的输出结果都在0-1之间。
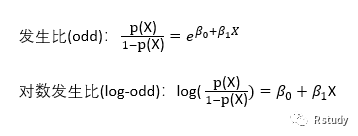
在一个线型模型中,B1表示X值每增加一个单位时Y的变化量。而在逻辑斯谛回归中,X每增加一个单位,对数发生比的变化为B1。
其中系数B0和B1是未知的。必须通过有效的训练数据来估计这些参数。一般使用极大似然方法估计逻辑斯谛回归模型的系数。
1.data
ISLR包中的smarket数据。该数据集里包括了2001年年初至2005年年末1250天里S&P500股票指数的投资回报率。数据中记录了过去5个交易日中的每个交易日的投资回报率,从Lag1到Lag5,同时也记录了volume(前一日的股票成交量,单位为十亿),today(当日的投资回报率)以及direction(走向,up或者down)。
> library(ISLR)> names(Smarket)[1] "Year" "Lag1" "Lag2" "Lag3" "Lag4" "Lag5" "Volume" "Today" "Direction"2. 数据的描述性统计分析
维度:1250*9
summary给出描述性统计分析,最大最小值,分位数等信息。
> dim(Smarket)[1] 1250 9> summary(Smarket) Year Lag1 Lag2 Lag3 Lag4 Min. :2001 Min. :-4.922000 Min. :-4.922000 Min. :-4.922000 Min. :-4.922000 1st Qu.:2002 1st Qu.:-0.639500 1st Qu.:-0.639500 1st Qu.:-0.640000 1st Qu.:-0.640000 Median :2003 Median : 0.039000 Median : 0.039000 Median : 0.038500 Median : 0.038500 Mean :2003 Mean : 0.003834 Mean : 0.003919 Mean : 0.001716 Mean : 0.001636 3rd Qu.:2004 3rd Qu.: 0.596750 3rd Qu.: 0.596750 3rd Qu.: 0.596750 3rd Qu.: 0.596750 Max. :2005 Max. : 5.733000 Max. : 5.733000 Max. : 5.733000 Max. : 5.733000 Lag5 Volume Today Direction Min. :-4.92200 Min. :0.3561 Min. :-4.922000 Down:602 1st Qu.:-0.64000 1st Qu.:1.2574 1st Qu.:-0.639500 Up :648 Median : 0.03850 Median :1.4229 Median : 0.038500 Mean : 0.00561 Mean :1.4783 Mean : 0.003138 3rd Qu.: 0.59700 3rd Qu.:1.6417 3rd Qu.: 0.596750 Max. : 5.73300 Max. :3.1525 Max. : 5.7330003. 变量之间的相关性分析
cor()函数
direction是定性的,所以要去掉这一列再计算相关性
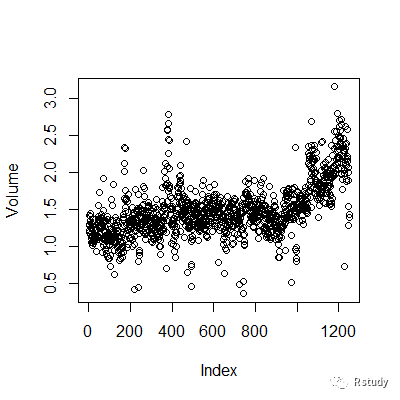
> pairs(Smarket)> # cor(Smarket)#direction是定性的,所以出错> cor(Smarket[,-9])#当前回报率与之前回报率相关性几乎为0 Year Lag1 Lag2 Lag3 Lag4 Lag5 Volume TodayYear 1.00000000 0.029699649 0.030596422 0.033194581 0.035688718 0.029787995 0.53900647 0.030095229Lag1 0.02969965 1.000000000 -0.026294328 -0.010803402 -0.002985911 -0.005674606 0.04090991 -0.026155045Lag2 0.03059642 -0.026294328 1.000000000 -0.025896670 -0.010853533 -0.003557949 -0.04338321 -0.010250033Lag3 0.03319458 -0.010803402 -0.025896670 1.000000000 -0.024051036 -0.018808338 -0.04182369 -0.002447647Lag4 0.03568872 -0.002985911 -0.010853533 -0.024051036 1.000000000 -0.027083641 -0.04841425 -0.006899527Lag5 0.02978799 -0.005674606 -0.003557949 -0.018808338 -0.027083641 1.000000000 -0.02200231 -0.034860083Volume 0.53900647 0.040909908 -0.043383215 -0.041823686 -0.048414246 -0.022002315 1.00000000 0.014591823Today 0.03009523 -0.026155045 -0.010250033 -0.002447647 -0.006899527 -0.034860083 0.01459182 1.000000000根据上面的结果可知,前几日的投资回报率与当日的投资回报率相关系数接于0。这也就是说当前的投资回报率与先前的投资回报率之间的相关性很小。唯一一对强相关的关系是year和volume。我们通过绘制volume的散点图发现volume呈现出增长趋势,也就是说2001-2005年平均每日股票成交量在增长。
|
4. logistic regression
4.1. 系数估计
通过LAG1到LAG5和volume拟合logistic regression model来预测direction。
glm()函数用于拟合广义线性模型(GLM),其中包含了logistic regression model.
glm函数的用法与lm函数类似,不同之处在于必须输入参数family=binomial,该命令的功能是请求R软件执行logistic回归,不使用其他类型的广义线性模型。
结果中最小的p值是Lag1的系数,预测变量负的系数表明如果市场昨天的投资回报率是正的,那么今日的市场可能不会上涨。然而,p值为0.145仍然是比较大的,远远大于0.05,所以没有充分的证据表明Lag1和direction之间有确切的关联性。
> glm.fits=glm(Direction~Lag1+Lag2+Lag3+Lag4+Lag5+Volume,data=Smarket,family=binomial)> #glm函数用于拟合广义线性模型,family=binomial> summary(glm.fits)Call:glm(formula = Direction ~ Lag1 + Lag2 + Lag3 + Lag4 + Lag5 + Volume, family = binomial, data = Smarket)Deviance Residuals: Min 1Q Median 3Q Max -1.446 -1.203 1.065 1.145 1.326Coefficients: Estimate Std. Error z value Pr(>|z|)(Intercept) -0.126000 0.240736 -0.523 0.601Lag1 -0.073074 0.050167 -1.457 0.145Lag2 -0.042301 0.050086 -0.845 0.398Lag3 0.011085 0.049939 0.222 0.824Lag4 0.009359 0.049974 0.187 0.851Lag5 0.010313 0.049511 0.208 0.835Volume 0.135441 0.158360 0.855 0.392(Dispersion parameter for binomial family taken to be 1) Null deviance: 1731.2 on 1249 degrees of freedomResidual deviance: 1727.6 on 1243 degrees of freedomAIC: 1741.6Number of Fisher Scoring iterations: 3调用coef函数获得拟合模型的系数,同时也可用summary来获取拟合模型的其他方面的信息,比如系数的p值等。
> coef(glm.fits)#用于输出拟合模型系数 (Intercept) Lag1 Lag2 Lag3 Lag4 Lag5 Volume -0.126000257 -0.073073746 -0.042301344 0.011085108 0.009358938 0.010313068 0.135440659 > summary(glm.fits)$coef Estimate Std. Error z value Pr(>|z|)(Intercept) -0.126000257 0.24073574 -0.5233966 0.6006983Lag1 -0.073073746 0.05016739 -1.4565986 0.1452272Lag2 -0.042301344 0.05008605 -0.8445733 0.3983491Lag3 0.011085108 0.04993854 0.2219750 0.8243333Lag4 0.009358938 0.04997413 0.1872757 0.8514445Lag5 0.010313068 0.04951146 0.2082966 0.8349974Volume 0.135440659 0.15835970 0.8552723 0.3924004> summary(glm.fits)$coef[,4](Intercept) Lag1 Lag2 Lag3 Lag4 Lag5 Volume 0.6006983 0.1452272 0.3983491 0.8243333 0.8514445 0.8349974 0.39240044.2. 结果预测
predict函数用来预测在给定预测变量下市场上涨的概率。
选项type="response"是明确告诉R输出概率P(Y=1|X),而不必输出其他信息,比如分对数等信息。
默认输出的是市场上涨的概率,因为contrasts函数表明R创建了一个哑变量,1代表up上涨。
> glm.probs=predict(glm.fits,type="response")#type="response"表示明确输出概率> glm.probs[1:10] 1 2 3 4 5 6 7 8 9 10 0.5070841 0.4814679 0.4811388 0.5152224 0.5107812 0.5069565 0.4926509 0.5092292 0.5176135 0.4888378 > contrasts(Direction)#创建哑变量 UpDown 0Up 1为了预测特定某一天市场上涨还是下跌,必须将预测的概率转换为类别。下面两行命令建立了一个类向量的预测,以预测的市场上涨概率比0.5大还是小为依据。
创建一个1250个down元素组成的向量,将预测市场上涨率超过0.5的元素转变为up。
table()函数可产生混淆矩阵来判断有多少观测被正确或者错误地分类了。
混淆矩阵中对角线元素表示正确预测,非对角线元素代表错误分类预测。
mean()函数可以计算正确预测的比例。
所以结果表明正确预测了市场52.2%的时间的动向变化。
> glm.pred=rep("Down",1250)> glm.pred[glm.probs>.5]="Up"> table(glm.pred,Direction)#混淆矩阵 Directionglm.pred Down Up Down 145 141 Up 457 507> (507+145)/1250[1] 0.5216> mean(glm.pred==Direction)#表示正确预测的比例[1] 0.52164.3. training and test
这个预测值是拟合logistic模型对建模所使用的的数据集的预测值。但是,实践中,我们对拟合模型所用数据上的模型运用效果不感兴趣,而是对未来日子里不确定的动态更感兴趣。
因此,我们用2001-20014年之间的观测做训练集train,余下的2005年数据做测试集test。
!是对布尔向量中所有元素取反。
!=表示不等,所以最后一行命令是计算测试错误率。
| test data上的预测正确率为0.48,错误率为0.52,这个错误率很高!这是因为,一般很少用前几日的投资回报率来预测未来市场的表现。这个例子只是为了演示R中logistic regression的用法。 |
> train=(Year<2005)> Smarket.2005=Smarket[!train,]> train=(Year<2005)> Smarket.2005=Smarket[!train,]> dim(Smarket.2005)[1] 252 9> Direction.2005=Direction[!train]> glm.fits=glm(Direction~Lag1+Lag2+Lag3+Lag4+Lag5+Volume,data=Smarket,family=binomial,subset=train)> glm.probs=predict(glm.fits,Smarket.2005,type="response")> glm.pred=rep("Down",252)> glm.pred[glm.probs>.5]="Up"> table(glm.pred,Direction.2005) Direction.2005glm.pred Down Up Down 77 97 Up 34 44> mean(glm.pred==Direction.2005)[1] 0.4801587> mean(glm.pred!=Direction.2005)[1] 0.5198413因为原始的logistic regression中,lag1和lag2的p值最小,表现出了最佳的预测能力。所以我们使用lag1和lag2来建立logistic regerssion model。
predict()函数预测新的给定预测变量的direction。
> glm.fits=glm(Direction~Lag1+Lag2,data=Smarket,family=binomial,subset=train)> glm.probs=predict(glm.fits,Smarket.2005,type="response")> glm.pred=rep("Down",252)> glm.pred[glm.probs>.5]="Up"> table(glm.pred,Direction.2005) Direction.2005glm.pred Down Up Down 35 35 Up 76 106> mean(glm.pred==Direction.2005)[1] 0.5595238> 106/(106+76)[1] 0.5824176> predict(glm.fits,newdata=data.frame(Lag1=c(1.2,1.5),Lag2=c(1.1,-0.8)),type="response") 1 2 0.4791462 0.4960939扫码关注,交流分享~~~
|
















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









