






随着遥感成像技术的发展,高分遥感影像空间分辨率逐年提高,已经成为获取地物信息的主要数据来源之一。高分影像分类作为遥感影像处理的重要任务之一,在地理国情普查与监测、数字城市建设、城市规划等领域具有广阔的应用前景。高分影像具有纹理信息丰富、形状特征明显、光谱混叠现象普遍存在的特点,单纯利用光谱特征的分类方法难以满足分类要求,多特征综合提取利用并结合高性能分类器的分类方法已经成为目前高分影像分类的主流趋势。但由于影像特征维数过高,容易造成冗余现象,加大了分类难度。
为解决特征冗余问题,文献[2]提出采用傅里叶谱分解算法提取纹理特征,并将光谱特征与纹理特征的分类规则相结合,来提高影像分类精度。文献[3]提出一种综合不同层次特征的MRF观测场模型,并针对高分影像的特点提出一种描述地物目标结构特性的特征,用于对MRF分类结果中易混淆类别进行序贯分类。文献[4]提出基于直方图的APs(HAPs),用于支持向量机的遥感图像分类,提出的HAP提供了关于标准AP场景空间信息的更完整和详细的表征,能够有效地表示纹理信息,HAP利用高维特征向量作为输入给具有HI内核的SVM分类器,可以有效避免直方图特征的休斯现象。文献[5]提出一种新的Fisher鉴别字典对学习(FDDPL)模型进行图像分类,将合成字典、编码系数和分析字典的判别嵌入到提出的字典对学习中,通过分析编码系数,不同分析词典之间的相关性及综合词典表示法,获得了较好的分类结果。文献[6]在核函数集成SVM分类框架下,提出一种多尺度光谱—空间—语义特征融合的高分影像分类方法,以有效解决特征冗余及同谱异物问题,提高地物提取精度。文献[7]提出基于多尺度多特征融合的高分影像分类方法,利用各地物特征的显著性差异实现多尺度下多特征的加权融合,得出了较好的分类效果,但各最优尺度下特征间相关性较高,冗余现象明显。
本文在上述研究的基础上,提出一种基于mRMR选择与IFCM(improved fuzzy c-means)聚类的影像分类算法。首先采用对象置信度指标(OC)进行影像分割,然后利用mRMR算法对分割影像进行特征选择,以减少特征冗余,最后使用IFCM算法进行特征距离计算,实现影像分类。
1 影像分割
为改善影像分割过程中的过分割及欠分割问题,本文采用文献[8]的分割方法,通过构建一个新的对象置信度(OC)索引度量任意区域与地理对象之间匹配程度的面向对象多尺度分割算法。该算法主要包括两个步骤:首先,通过对影像进行过分割构建初始种子区域集合及确定尺度参数集合; 随后,通过跟踪OC的尺度间变化来引导多尺度区域合并过程,使区域合并结果逐渐逼近实际的地理对象。
2 mRMR特征选择
为解决文献[7]利用不同特征之间的邻接关系,只考虑各特征之间相关性,造成特征冗余度大、计算复杂度高的问题,本文在此引入mRMR特征选择算法。
mRMR算法利用互信息衡量不同特征的相关性和冗余度,并根据信息差和信息熵这两个代价函数来寻找特征子集,使得选出的特征与目标类别之间具有最大相关性,且互相之间具有最小冗余度,可以很好地实现特征选择[9]。mRMR的最大相关和最小冗余分别定义如下
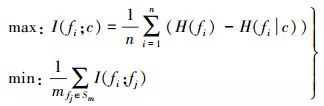 (1)
(1)
式中,Sm为已选的特征集合;m为特征个数;c为目标类别;H(fi|c)为特征fi在目标类别下的信息熵;H(fi)为特征fi的信息熵;I(fi; fj)为特征fi与fj之间的互信息。
因此,假定已确定特征集Sm,下一步从{S-Sm}中选择第m+1个特征。公式如下
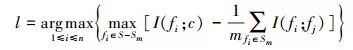 (2)
(2)
假设训练数据集为D,全部特征集为S,则mRMR算法的执行过程为:
(1) 进行初始化操作,S= {f1, f2, …, fn}, Sm=Ø。
(2) 对于任意两个输入S的特征fi和fj,计算I(fi; fj)和I(fi; c)。
(3) 根据式(2)选出特征fl,则Sm=Sm∪{fl}, S=S/fl;然后,回到步骤(2)继续执行,直至选出最优特征子集。
其中,像斑多特征提取见表 1。
表 1 像斑多特征提取
| 光谱特征 | 纹理特征 | 形状特征 |
| 均值、标准差、波段比、亮度、NDVI等 | 标准差、平均值、差异度、对比度、信息熵、同质性等 | 形状指数(OCI)、面积、长宽比、长度、宽度等 |
3 IFCM影像分类过程3.1 显著特征差异性融合的FCM分类算法
文献[7]利用各地物显著特征的不同,实现显著特征差异性融合的图像分类。具体步骤如下:
(1) 将矢量化的特征进行人工鱼群算法运算,寻找显著性特征,即为聚类中心,S ={s1, s2, …, sn}。
(2) 计算各特征矢量到聚类中心S ={s1, s2, …, sn}的距离D={d1, d2, …,dn}, 并求取距离的倒数,归一化表示为各矢量特征对应的权重εi,达到特征差异性融合的目的。
(3) 对特征加权融合所生成的向量空间进行模糊c均值聚类(FCM)。
3.2 文献[7]中FCM聚类策略
(1) 参数初始化。设定聚类数目c, 算法终止循环阈值δ, 最大迭代次数n及初始聚类中心V = {v1, v2, …, vn}和模糊隶属度矩阵U。
(2) 输入待训练特征向量X = {x1, x2, …, xn},及模糊c均值聚类算法目标函数
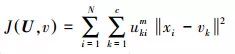 (3)
(3)
(3) 使用当前系数迭代更新隶属度,获得新的隶属度再迭代更新各系数。在约束条件下,目标函数可转化为
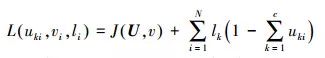 (4)
(4)
(4) 使用目标函数进行迭代,直到满足终止循环的阈值或达到最大迭代次数,则停止聚类并输出最终分类结果。
3.3 IFCM聚类算法
由于上述分类算法只考虑特征间的相关性,易导致算法对噪声敏感,稳定性差。本文在原始算法目标函数计算的基础上,考虑封装在本地窗口中局部信息的同时引入空间吸引力模型,抑制噪声的同时使算法更具稳健性,提出如下目标函数计算方法
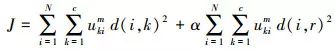 (5)
(5)
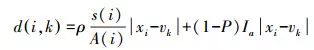 (6)
(6)
式(6)代表特征xi与聚类中心的距离测度。s(i)表示xi所处区域内部标准差,A(i)表示xi所在区域的面积,二者会随聚类中心和隶属度的更新进行相应的更新。s(i)越大,A(i)越小,其内部同质度大、合并其他对象的可能性就越低;Ia表示xi与聚类中心vk的相关性,Ia越大,对象点和聚类中心之间相关性越低,则聚类合并的可能性就越小。Ρ代表对象内部同质度所占权重,可通过权重值来调整对象内部同质度和对象间相关性的比重。
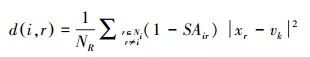 (7)
(7)
式(7)代表xi邻域向量到聚类中心的距离。在此,本文引入像素空间吸引力模型,吸引力模型能有效表征像素之间的空间相关性。两个像素之间的空间吸引力SAir(k)可以被描述为SAir(k)= 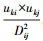 ,表示xi和它的邻域xj分别对第k个簇的吸引力与它们的模糊隶属度uki和ukj成正比,并与两个像素空间距离的平方成反比。NR表示邻域像素的基数,为了自适应计算邻域像素的隶属度,引入参数α,
,表示xi和它的邻域xj分别对第k个簇的吸引力与它们的模糊隶属度uki和ukj成正比,并与两个像素空间距离的平方成反比。NR表示邻域像素的基数,为了自适应计算邻域像素的隶属度,引入参数α,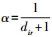 ,dir表示xi与xj的空间距离。由此,再进行目标函数在约束条件下的计算,求取分类结果。本文具体算法如下:
,dir表示xi与xj的空间距离。由此,再进行目标函数在约束条件下的计算,求取分类结果。本文具体算法如下:
输入:待分类影像数据Y,训练数据占比ε,对象置信度指标OC,尺度参数ML,已选特征集Sm,聚类数目c,算法终止循环的阈值δ,最大迭代次数n。
输出:聚类划分Yi,i=1, 2, …,k。
步骤1 采用对象置信度OC指引的图像分割方法分割图像。
步骤2 假设训练数据集为D,全部特征集为S,利用mRMR算法选出最优特征子集,避免特征冗余。
步骤3 人工鱼群算法寻找显著性特征S = {s1, s2, …,sn},求取距离D = {d1, d2, …,dn}的倒数归一化为权重εi, 实现特征的差异性融合。
步骤4 输入待训练特征向量X ={x1, x2, …, xn},改进模糊c均值聚类算法在约束条件下目标函数J的转化公式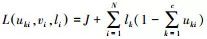 ,进行IFCM聚类。
,进行IFCM聚类。
步骤5 判断是否满足终止循环阈值或达到最大迭代次数,不满足则转步骤4,满足则输出最终分类结果。
4 试验结果与分析
试验选取重庆市某地区WorldView-2影像为研究对象,影像大小为687×452像素,拍摄时间为2016年8月,主要含有R、G、B、NIR 4个波段和4个附加波段,空间分辨率为0.5 m。人工选取分割影像中的30%为训练样本,其余70%为测试样本。
在特征提取与选择过程中,提取影像光谱特征(各波段光谱均值(8维)、波段比(8维)、标准差(8维)、亮度),纹理特征(标准差(8维)、平均值(8维)、差异度(8维)、对比度(8维)、信息熵(8维)、同质性(8维)),形状特征(面积、长度、宽度、矩形度、长宽比、形状指数、紧致度)等共计80维特征,经mRMR算法选择出具有最大相关最小冗余的16维特征构成特征向量并进行归一化处理。其中,参数c=4, m=2, ε=1×10-5, NR=8。
为验证所提方法的有效性,本文设计了不同的方法进行对比,包括:文献[2]分类方法、文献[3]分类方法、文献[4]分类方法、文献[5]分类方法、文献[6]分类方法、本文方法。各方法分类结果如图 1、表 2所示。
 |
| 图 1 不同方法试验结果(一) |
表 2 本文方法分类地物统计表(混淆矩阵)
| 本文方法 | 人工解译 | |||||||
| 植被 | 阴影 | 水体 | 裸地 | 道路 | 建筑物 | 行总和 | 生产者精度/(%) | |
| 植被 | 304 | 5 | 2 | 4 | 0 | 3 | 318 | 94.41 |
| 阴影 | 8 | 61 | 7 | 0 | 3 | 0 | 79 | 85.92 |
| 水体 | 5 | 3 | 46 | 0 | 0 | 0 | 54 | 85.19 |
| 裸地 | 6 | 2 | 0 | 229 | 4 | 0 | 242 | 94.24 |
| 道路 | 0 | 0 | 0 | 6 | 111 | 3 | 120 | 90.98 |
| 建筑物 | 0 | 0 | 0 | 4 | 4 | 182 | 190 | 96.81 |
| 列总和 | 323 | 71 | 55 | 243 | 122 | 188 | — | — |
| 用户精度/(%) | 95.59 | 77.22 | 85.20 | 94.63 | 92.50 | 95.79 | — | — |
本文从主观评价和客观评价两方面对各种分类算法影像分类效果进行了比较和分析。
(1) 主观评价(图 1中均已用方框标出):从目视效果上看,依照前4个文献的分类方法均出现道路与裸地混淆现象。另外,图 1(b)中,大量植被和建筑物错分,少量阴影被错分为植被,少量水体被错分为阴影,少量植被被错分为道路;图 1(c)中的分类方法,水体被错分为阴影,阴影与植被等少量混淆,少量植被被错分为道路;图 1(d)中的分类方法,少量道路及阴影被错分为植被,少量建筑物被错分为道路;图 1(e)中,大量道路被错分为裸地与植被,少量阴影被错分为水体;图 1(f)分类结果中,少量建筑物及阴影被错分为植被。而本文方法大部分地物实现了准确划分,避免了地物混淆现象,总体分类精度较高。
(2) 客观评价:本文采用基于像素的评价方法进行定量分析。
在原始影像中随机选取1000个样本点,将样本点映射到分类结果中,通过人工解译构造混淆矩阵,依据混淆矩阵计算生产者精度(PA)、用户精度(UA)、Kappa系数等来比较分析。样本分布如图 2所示。分别对上文所述分类方法中,地物分类的正确样本数和错误样本数进行统计,取10次统计的平均数作为最终数据,统计结果见表 3。
 |
| 图 2 样本分布 |
表 3 测试样本点数目统计
| 地物类型 | 样本数量/个 |
| 植被 | 322 |
| 阴影 | 71 |
| 水体 | 54 |
| 裸地 | 243 |
| 道路 | 122 |
| 建筑物 | 188 |
| 总计 | 1000 |
利用混淆矩阵(表 2)、OA和Kappa系数客观评估不同方法的优劣,计算结果见表 4。本文算法总体分类精度达到93.29%,Kappa系数为0.914 3。相比文献[5]和文献[6],总体分类精度分别提高3.24%和2.05%,Kappa系数分别提高0.041 7和0.026 4。
表 4 试验一分类方法综合评价结果
| 分类方法 | 评价方法 | |
| 总体分类精度/(%) | Kappa系数 | |
| 文献[2] | 84.00 | 0.797 4 |
| 文献[3] | 86.60 | 0.826 8 |
| 文献[4] | 88.54 | 0.852 6 |
| 文献[5] | 90.05 | 0.872 6 |
| 文献[6] | 91.24 | 0.887 9 |
| 本文方法 | 93.29 | 0.914 3 |
从表 4中数据得出:基于mRMR选择与IFCM聚类算法分类效果要优于其他算法的试验结果,其分类精度高于以往其他算法,分类结果中混淆地物较少,实现了大多数地物的准确划分。基于对象置信度OC指标的分割,改善了传统分割方法中的过分割与欠分割问题;mRMR特征选择算法可以很好地避免特征冗余带来的存储空间大、计算复杂度高的问题;IFCM聚类算法比传统FCM算法稳健性更好,获取的分类结果精度更高。
为了进一步验证本文算法的合理性和正确性,另选用重庆某城乡地物较简单区域的航天遥感影像作分类试验,影像大小为696×760像素。试验结果如图 3所示。
 |
| 图 3 不同方法试验结果(二) |
图选项 |
由图 3目视效果上看,文献[2]分类结果中出现少量植被与道路混淆现象,且有部分阴影被错分为植被;文献[3]分类结果中出现植被与裸地混淆现象,及少量的植被被错分为建筑物,少量建筑物被错分为道路,这是由于道路和建筑物光谱相似所致;文献[4]分类结果中少量植被被错分为裸地,少量建筑物被错分为道路;文献[5]分类中只有少量道路被错分为植被和阴影;文献[6]分类结果中出现少量道路与植被混淆现象,建筑物与道路错分现象;而本文算法大部分地物实现了准确划分,只有少量样本(道路与建筑物)出现了错误划分,对比其他分类算法,在地物提取精度方面有大幅度提高。
本试验定量评价结果见表 5,其总体精度和Kappa系数的计算方法同上。
表 5 试验二分类方法综合评价结果
| 分类方法 | 评价方法 | |
| 总体分类精度/(%) | Kappa系数 | |
| 文献[2] | 85.60 | 0.819 5 |
| 文献[3] | 87.20 | 0.843 6 |
| 文献[4] | 88.72 | 0.857 6 |
| 文献[5] | 90.43 | 0.873 9 |
| 文献[6] | 92.91 | 0.895 6 |
| 本文方法 | 94.33 | 0.922 0 |
从分类效果图和表 5的定量分析可得:本文方法比试验中文献[4]、文献[5]和文献[6]分类方法的精度分别提高了5.16%、4.10%和1.42%,Kappa系数分别提高了0.064 4、0.048 1和0.026 4。
由以上两组不同地区影像分类试验可知,本文算法分类精度最好,能实现大部分地物的准确划分。本文在对象置信度指标(OC)的基础上分割图像并利用mRMR特征选择方法减少冗余,降低计算复杂度;IFCM聚类算法增强了稳健性,且对噪声不敏感,易于在大规模问题中应用。
5 结 语
本文提出了一种基于mRMR选择与IFCM聚类的遥感影像分类算法。首先基于OC指标进行影像分割试验,在分割良好的基础上采用mRMR算法进行特征选择以减少冗余,并利用IFCM算法进行特征聚类以达到地物分类的目的。对比不同试验结果,本文方法分类精度最高,实现了地物的准确划分。
黄磊, 向泽君, 楚恒. 结合mRMR选择和IFCM聚类的遥感影像分类算法[J]. 测绘通报,2019(4):32-37.
DOI: 10.13474/j.cnki.11-2246.2019.0108
作者简介: 黄磊,女,硕士生,研究方向为遥感影像融合与分类。E-mail:1377825510@qq.com
———————& End &————————
微信投稿邮箱:lyg0061@163.com
欢迎加入《测绘通报》作者QQ群: 435838860
进群请备注:姓名+单位
















 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









