





调用信息
Lua在调用每个函数时,都会生成一个CallInfo,并将它们链接成一个双向链表。通过这个链表,我们就可以知道整个调用链的情况。
CallInfo最主要的作用是记录一个函数调用涉及到的栈引用,先看一下该结构的声明:
typedef struct CallInfo {
// 该栈位置保存调用关联的函数
StkId func; /* function index in the stack */
// 该函数的栈顶引用,[func, top]就是这个函数栈范围
StkId top; /* top for this function */
// 调用链表
struct CallInfo *previous, *next; /* dynamic call link */
union {
struct { /* only for Lua functions */
// 栈基址,base往下这部分为函数的可变参数,base往上为函数的固定参数,和本地变量
StkId base; /* base for this function */
const Instruction *savedpc; // 正在执行指令
} l;
struct { /* only for C functions */
// 延续函数
lua_KFunction k; /* continuation in case of yields */
ptrdiff_t old_errfunc;
// 延续函数环境
lua_KContext ctx; /* context info. in case of yields */
} c;
} u;
ptrdiff_t extra;
short nresults; /* expected number of results from this function */
// 调用状态
unsigned short callstatus;
} CallInfo;previous和next会使CallInfo形成一个双向链表,lua_State->ci则记录着当前的调用,这个链表可以用下图表示:
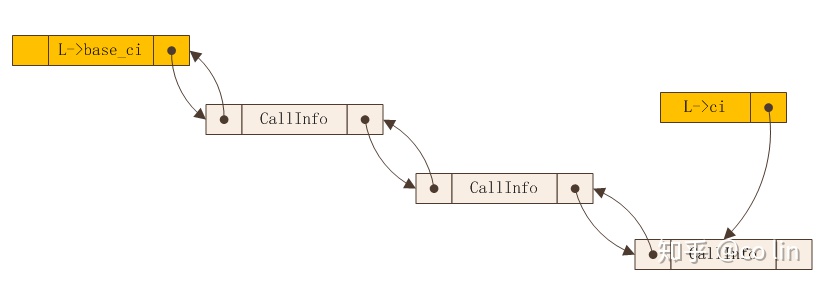
lua_State的base_ci为第一层调用,ci则记录着当前的调用。
CallInfo中的func是与调用关联的函数对象,这个对象在线程的栈中,而top则是调用的栈顶,[func, top]就是这个调用使用的栈范围。
u是一个联合,其中有Lua函数的结构,和C函数的结构,C函数主要是保存延续函数的信息(这个我们先略过),Lua函数则有一个栈基址base,和一个当前正在执行的指令savedpc。
CallInfo中几个字段对栈的引用可用下图表示:
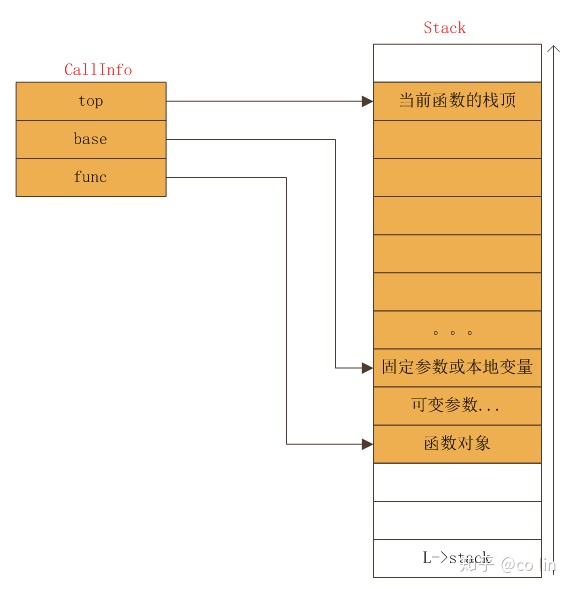
从上图可看出CallInfo会占用栈的一部分,用来保存函数参数,本地变量,和运算过程的临时变量。而这部分栈一定是以关联的函数对象开始的。
生成调用信息
我们看一下生成一个调用信息的过程是怎么样的,首先从luaD_call这个函数开始,这个函数调用一个C或Lua函数:
// 调用一个函数(C或Lua),函数在func这个栈地址上,再往上就是参数
// 当函数调用完,func和参数都会出栈,返回参数都压在栈上
void luaD_call (lua_State *L, StkId func, int nResults) {
// 从C层调用一个函数的嵌套限制,LUAI_MAXCCALLS=200
if (++L->nCcalls >= LUAI_MAXCCALLS)
stackerror(L);
// 准备调用,返回0表示Lua函数,则要用下面的luaV_execute执行字节码。
// 否则是C函数,已经直接被调用
if (!luaD_precall(L, func, nResults)) /* is a Lua function? */
luaV_execute(L); /* call it */
L->nCcalls--;
}Lua的函数调用都遵循一个规则,就是首先函数入栈,然后参数入栈,在调用完之后函数和参数都出栈,在函数中临时压栈的值也会出栈,最后把函数的返回结果入栈,返回给外层函数。也就是说,函数返回之后的栈应该等于进入之前的栈,加上返回结果。
luaD_precall准备一个函数调用,具体的实现等谈到函数对象时再看,这里只说一下它的大概处理,分成几种情况:
- 如果函数是C闭包或C轻量函数,则确保留给该函数的栈空间有
LUA_MINSTACK(20)个,然后调用next_ci生成一个新的CallInfo并设置相关信息,接着直接调用C函数,函数回来之后L->ci返回上一层CallInfo。最后调整栈上的返回值。最后返回1 - 如果函数是Lua闭包,则从Proto对象得到参数,返回结果,以及需要的“寄存器”大小等信息,以此调整栈。然后调用
next_ci生成一个新的CallInfo并设置相关信息,最后返回0。 - 如果func不是一个函数对象,则尝试它的__call元方法,最终递归调用luaD_precall。
这一套是函数调用的核心点,等后面谈函数对象再说。现在只关注CallInfo相关的代码:
// C函数
ci = next_ci(L); /* now 'enter' new function */
// 这是期望的结果数
ci->nresults = nresults;
// 保存函数的栈地址
ci->func = func;
// 函数的可用栈顶
ci->top = L->top + LUA_MINSTACK;
// 无状态位
ci->callstatus = 0;
// Lua函数
ci = next_ci(L); /* now 'enter' new function */
// 这是期望的结果数
ci->nresults = nresults;
// 保存函数的栈地址
ci->func = func;
// 函数的栈基址,看上图
ci->u.l.base = base;
// 函数的可用栈顶
L->top = ci->top = base + fsize;
// 函数的起始指令
ci->u.l.savedpc = p->code; /* starting point */
// 标记为Lua函数
ci->callstatus = CIST_LUA;next_ci是这样的:
// 下一个callinfo,如果有返回,如果没有创建一个新的
#define next_ci(L) (L->ci = (L->ci->next ? L->ci->next : luaE_extendCI(L)))
// 创建新的callinfo
CallInfo *luaE_extendCI (lua_State *L) {
CallInfo *ci = luaM_new(L, CallInfo);
lua_assert(L->ci->next == NULL);
L->ci->next = ci;
ci->previous = L->ci;
ci->next = NULL;
L->nci++;
return ci;
}从中看出next_ci并不一定会创建CallInfo,它是在L->ci->next不存在时才创建的,这说明ci链并不是用完就释放掉的,它仍然会保留在链表上,等着下次重用。到这里我们终止明白为什么ci要用双向链表的原因了。
再看看函数返回时对ci的处理就明白了:
// luaD_poscall
// 返回上一层CallInfo
L->ci = ci->previous; /* back to caller */它只是将L->ci往前移,所以CallInfo链表可以想象成一个无限延伸的链表,L->ci在这个链表上前后移动。这样就能避免每次函数调用都创建和释放的操作。
清除调用链表
当然CallInfo链表会在适当的时候缩减一下,在GC或者保护模式的错误恢复时,会调用luaD_shrinkstack收缩栈,在这里面同时也会调用luaE_shrinkCI缩减调用链表,我们看一下这个函数,学一学它是怎么做的:
/*
释放掉后面一半的调用信息,如A->B->C->D->E,释放后就是A->C->E
*/
void luaE_shrinkCI (lua_State *L) {
CallInfo *ci = L->ci;
CallInfo *next2; /* next's next */
/* while there are two nexts */
while (ci->next != NULL && (next2 = ci->next->next) != NULL) {
luaM_free(L, ci->next); /* free next */
L->nci--;
ci->next = next2; /* remove 'next' from the list */
next2->previous = ci;
ci = next2; /* keep next's next */
}
}它从L->ci往后,跳着删除CallInfo结点,这样就只删除掉一半,还剩一半可以用。每每读到这样的代码,真是拍案称奇,Lua可以说在代码优化和内存紧凑这一块做到极致了。














 2540
2540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









