





Google在Protocol buffers的官网首页开宗明义,指出Protocol buffers有语言无关、平台无关、可扩展的特性;重要的是在进行序列化时,相比其他结构化数据格式(Json、XML),它:更小,更快、更简单。
先看看定义Protocol buffers的proto文件长什么样子
syntax = "proto2";option java_package = "protobuf";option java_outer_classname = "Test";message Test1 {optional int32 a = 1;optional string b = 2;}平台&语言无关:是指支持多语言,包括java、python、go、C++等,由其中一种语言序列化后的数据流可以被其他语言反序列化。比如java序列化的数据,可以用C++反序列化。

假定我们将a=150; b="testing159”
更小:
-rw-r--r-- 1 root root 26 Oct 19 16:03 test_json-rw-r--r-- 1 root root 15 Oct 19 16:03 test_proto先看看proto和json分别序列化以后的文件大小,仅仅2个字段的业务定义就有11个字节的差异,如果字段稍多一些,结果更是可想而知了。
Q:为什么差距这么大?先来看看test_proto的文件内容
hexdump -C test_proto08 96 01 12 0a 74 65 73 74 69 6e 67 31 35 39A:Protobuf用Varint来表达int32
08的二进制表示为0000 1000,按照Varint编码约定,去掉最高有效位0,剩下000 1000。
然后最后的三位,000 ( ->0 ) 表示对应的type, 然后右移3位( ->1),也就是a在proto的字段顺序。
96 01 = 1001 0110 0000 0001 → 000 0001 ++ 001 0110 (drop the msb and reverse the groups of 7 bits) → 10010110 (反转,最低有效位靠前) → 128 + 16 + 4 + 2 = 150总结:实际项目中,int32类型的往往不会太大,越小的数字,占用的字节数越少。
更快:
用protobuf和json格式,分别进行100000次序列化和反序列化的耗时。
ser proto -> 79 ms.
ser json -> 672 ms.
deser proto -> 53 ms.
deser json -> 195 ms.
可以看出,无论序列化和反序列化,protobuf 的性能都N倍于json。
为什么?从上述例子的文件内容可以看出:
08 96 01 12 0a 74 65 73 74 69 6e 67 31 35 3912(0001 0010)按照Varint约定得出字段顺序是2,type也是2,表示长度限定;
接下来0a 表示该字段的长度是10,需要往后的10个字节都属于该字段。
对便于理解,附上type定义表
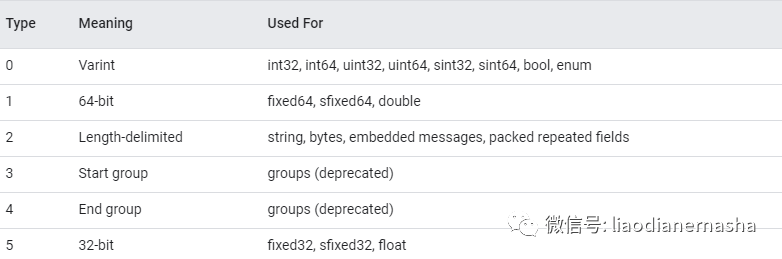
Q:为什么这种TLV(TAG-LENGTH-VALUE)格式的反序列化速度比Json要快很多呢?
A :这是因为主流的Json序列化框架,都是需要成对的读取双引号(“),读了第一个”后,并不知道下一个“在哪?需要不断的next,直到出现”。而protobuf就不必这么麻烦了。
像Gson是这么做的:
private String nextQuotedValue(char quote) throws IOException { // Like nextNonWhitespace, this uses locals 'p' and 'l' to save inner-loop field access. char[] buffer = this.buffer; StringBuilder builder = new StringBuilder(); while (true) { int p = pos; int l = limit; /* the index of the first character not yet appended to the builder. */ int start = p; while (p < l) { int c = buffer[p++]; if (c == quote) { pos = p; builder.append(buffer, start, p - start - 1); return builder.toString(); } else if (c == '\\') { pos = p; builder.append(buffer, start, p - start - 1); builder.append(readEscapeCharacter()); p = pos; l = limit; start = p; } else if (c == '\n') { lineNumber++; lineStart = p; } } builder.append(buffer, start, p - start); pos = p; if (!fillBuffer(1)) { throw syntaxError("Unterminated string"); } } }
更简单:
Protobuf提供了跨平台的编译工具,开发者只需要编写proto文件,编译工具会根据命令生成所需的定义文件,如.java、.py等等,文件里就包含了各自的序列化方法。
总结:
如果你的系统在性能、大小、跨语言方面有新的要求,那么可以试试这种很“古老”的protobuf,会带给你很多惊喜。















 2176
2176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









