






前面一片文章,我们已经说了Redis的主从集群及其哨兵模式。本文将继续介绍Redis的分布式集群。
”
在高并发场景下,单个Redis实例往往不能满足业务需求。单个Redis数据量过大会导致RDB文件过大,RDB文件过大会导致主从全量同步时间过长,同时重启恢复也会消耗过长的时间。同时Redis是单线程的,单个核心处理海量的内存数据,会导致CPU压力很大。
Codis
Codis是一个国产的Redis集群中间件,负责转发代理客户端请求。
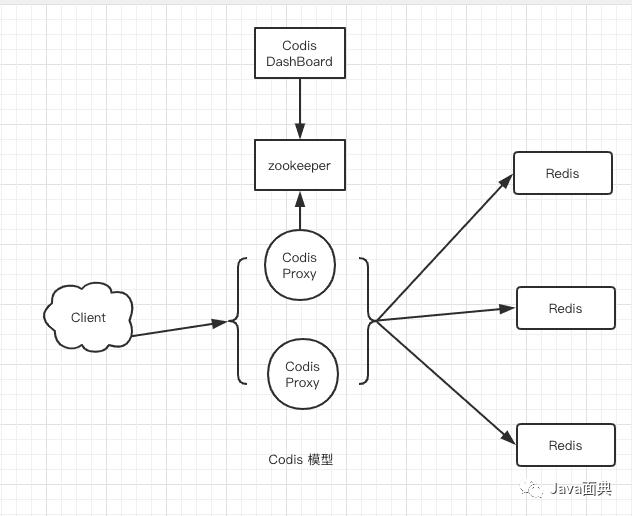
Codis 模型
Codis模型.png
Codis原理
Codis中key的分配规则如下:
- 默认将内部划分成1024个槽位(solt);
- 将key进行crc32计算,获取hash值;
- hash值整数部分对1024取模得到余数,得到的余数就是对应的槽位;
- 每个槽位对应不同的Redis实例,通过槽位索引,操作对应的Redis实例。
Codis通过zookeeper存储槽位关系,通过Dashboard管理槽位,当槽位关系发生变化Codis Proxy通过监听zookeeper获取到槽位变化,并同步槽位关系。
Codis扩容
当Redis实例需要增加的时候,Codis通过slotscan扫描出所有待迁移的key,然后遍历迁移key到新的Redis实例中。
当key处于迁移状态时,Codis会先将key迁移到新的Redis实例中,再将操作指令转发到新的Reids实例中。
Codis缺点
- 不支持事务,因为所有的key分布在不同实例中,所以不支持事务。
- 部分命令不支持,如rename等命令无法支持。因为rename参数是两个key,如果两个key在不同实例中,无法正确rename。
- value大小受限,为了支持扩容,单个key对应的value不宜过大,如果过大,会导致迁移卡顿。
- 增加网络开销,因为Codis增加了一个Proxy作为转发层,网络上相较于单个Reids开销更大。
- 运维更加麻烦,因为Codis需要zookeeper实现,需要增加zookeeper的运维代价。
Redis Cluster
Redis Cluster 将所有数据划分为16384个槽位,每个节点负责管理一部分槽位,当Redis客户端连接集群的时候,也会得到一份集群的槽位配置信息。同时,Redis Cluster每个节点都会将集群中的配置信息持久化到配置文件中。
槽位操作
定位
- 将所有数据划分为16384个槽位;
- Redis Cluster 默认对key使用crc16算法进行hash;
- hash值对16384进行取模操作,得到具体槽位信息;
Redis Cluster允许用户将key挂在指定槽位上。
跳转
当Redis Cluster集群中,某个节点收到客户端的错误key值操作指令后,当节点发现key在当前节点不存在时,节点会向客户端发送一个跳转执行,告诉客户端跳转到正确的节点去操作数据。
迁移
Redis支持手动以槽位为单位进行槽位迁移。整个迁移流程如下:
- 迁移工具redis-trib在源节点(migrating)和目标节点(importing)设置槽位中间状态;
- 遍历获取源节点槽位的所有key;
- 在源节点通过dump指令获取key的序列化内容,发送到目标节点;
- 目标节点反序列化key内容,返回OK到源节点;
- 删除迁移完成的key。
从源节点收到迁移指令开始,到源节点删除key为止,整个迁移流程中,源节点的主线程处于阻塞状态。
当槽位在迁移中时,此时客户端访问key流程如下:
- 此时客户端缓存的key信息还在源节点中,所以此时客户端会去访问源节点;
- 当目标key数据还在源节点中,正常处理key;
- 当目标key不在源节点中:
3.1. 源节点返回给客户端 -ASK targetNodeAddr;
3.2. 客户端发送ASKING指令到目标节点;
3.3 在目标节点执行原有指令。
为什么发送ASKING指令?在迁移没完成前,该槽位不归新节点管,如果直接发送操作指令,节点会返回给客户端 -MOVED重定向指令,让客户端去访问源目标节点,形成重定向循环。ASKING指令会强制让目标节点处理迁移未完成的槽位key。
容错
- 主从节点: 允许为每个主节点设置若干个从节点,当主节点发生故障的时候,集群会自动将从节点提升为主节点;
- cluster-require-full-coverage:允许集群中部分节点发生故障的时候,其他节点还可以继续提供对外服务;
- cluster-node-timeout:可以用配置当某个节点持续timeout失联时,才认定该节点出现故障,需要进行主从切换。如果无该配置,因网络抖动,会导致频繁的主从切换;
- PFail:当一个节点发现某个节点失联了,该节点会将这条信息向整个集群广播,失联节点此时可认为是PFail(可能是失联);
- Fail:当失联节点被集群大多数节点认为是PFail的时候,就可以标记该节点为失联(Fail),然后广播该节点已经失联下线,同时对该节点进行主从切换。
Redis系列推荐
Redis04——五分钟明白Redis的哨兵模式
Redis03——Redis是如何删除你的数据的
Redis02——Redis内存数据如何保存到磁盘
Redis01——Redis究竟支持哪些数据结构















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









