









回归分析是对客观事物数量依存关系的分析,是统计中的一个常用的方法,被广泛应用于自然现象和社会经济现象中变量之间的数量关系研究。本章将介绍线性回归的原理、估计方法以及R语言的实现。
 5.1 问题的提出
5.1 问题的提出
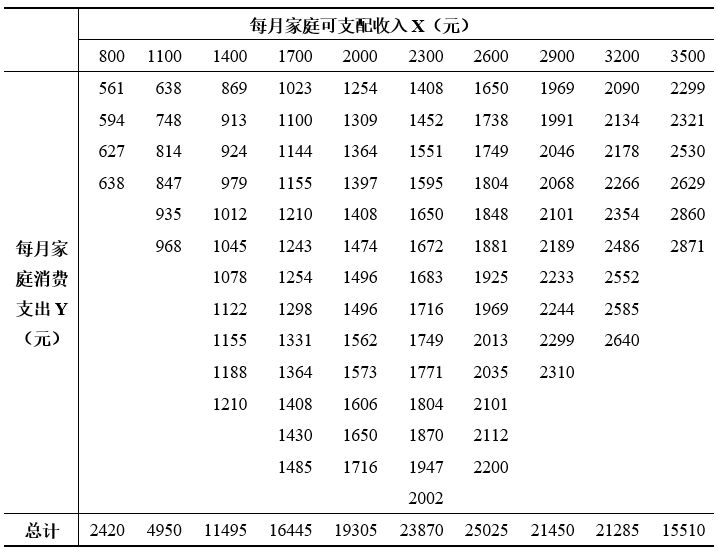
例5.1 为了研究某社区家庭月消费支出与家庭月可支配收入之间的关系,随机抽取并调查了12户家庭的相关数据,见表5-1。通过调查所得的样本数据能否发现家庭消费支出与家庭可支配收入之间的数量关系,以及如果知道了家庭的月可支配收入,能否预测家庭的月消费支出水平呢?
表5-1 每月家庭消费支出与每月家庭可支配收入

注:数据来自李子奈、潘文卿《计量经济学》(第三版)
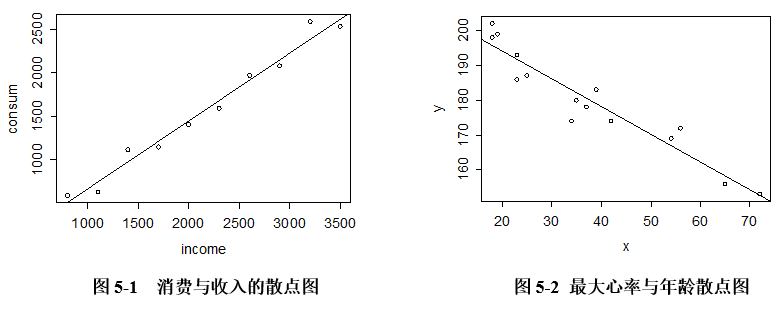
我们首先对数据进行探索性分析,发现消费与收入具有很强的正相关关系,pearson相关系数为0.988。通过图5-1的散点图可以看出,两者有着明显的线性关系,但是还无法确定收入具体是如何影响消费支出的呢?
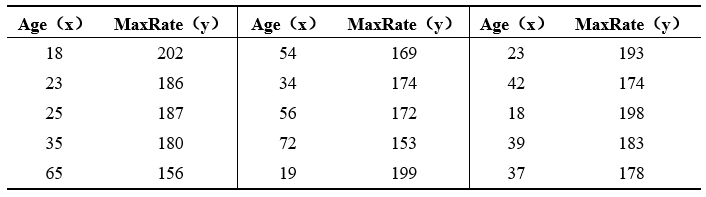
例5.2 医学上认为一个人的最大心率和年龄是有很大关系的,一般有这样的经验公式MaxRate = 220 - Age来决定的。现在收集了15个来自不同年龄层的人接受了最大心率测试的数据,如表5-2所示。
表5-2 最大心率与年龄的调查数据
通过探索性分析,我们发现最大心率与年龄具有很强的负相关关系,pearson相关系数为-0.953。通过图5-2的散点图可以看出,两者有着明显的线性的关系,但同样也无法确定年龄具体是如何影响最大心率的呢?
要解决以上问题,就需要用到回归分析。
一元线性回归是回归分析模型中最简单的一种形式,也是学习回归分析的基础,只有掌握好一元线性回归,才能更好地理解多元线性回归和非线性回归等。
5.2.1一元线性回归概述例5.3 在一个假想的由100户家庭组成的社区中,我们想要研究该社区每月家庭消费支出与每月家庭可支配收入的关系(参见表5-3),例如随着家庭月收入的增加,其平均月消费支出是如何变化的?
表5-3 某社区家庭月可支配收入和消费支出
注:数据来自李子奈、潘文卿《计量经济学》(第三版)
从表5-3可以看出:
(1)可支配收入相同的家庭,其消费支出不一定相同,即收入和消费支出的关系不是完全确定的;
(2)由于是假想的总体,给定收入水平 X的消费支出Y的分布是确定的,即在X给定下Y的条件分布(Conditional distribution)是已知的,如
X的消费支出Y的分布是确定的,即在X给定下Y的条件分布(Conditional distribution)是已知的,如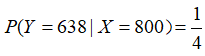 。
。
表5-3里的数据对应的散点图见图5-3。从图5-3可以发现家庭消费支出的平均值随着收入的增加而增加,且Y的条件均值和收入X近似落在一条直线上。我们称这条直线为总体回归线,相应的函数为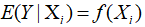 ,称为总体回归函数(population regression function, PRF),刻画了因变量Y的平均值随自变量X变化的规律。其中
,称为总体回归函数(population regression function, PRF),刻画了因变量Y的平均值随自变量X变化的规律。其中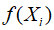 可以是线性的也可以是非线性的。例5.3中,将居民消费支出看成是其可支配收入的线性函数时,总体回归函数为
可以是线性的也可以是非线性的。例5.3中,将居民消费支出看成是其可支配收入的线性函数时,总体回归函数为
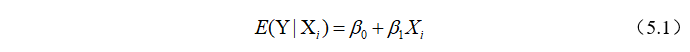
其中, 是未知参数,也称为回归系数(regression coefficients)。
是未知参数,也称为回归系数(regression coefficients)。
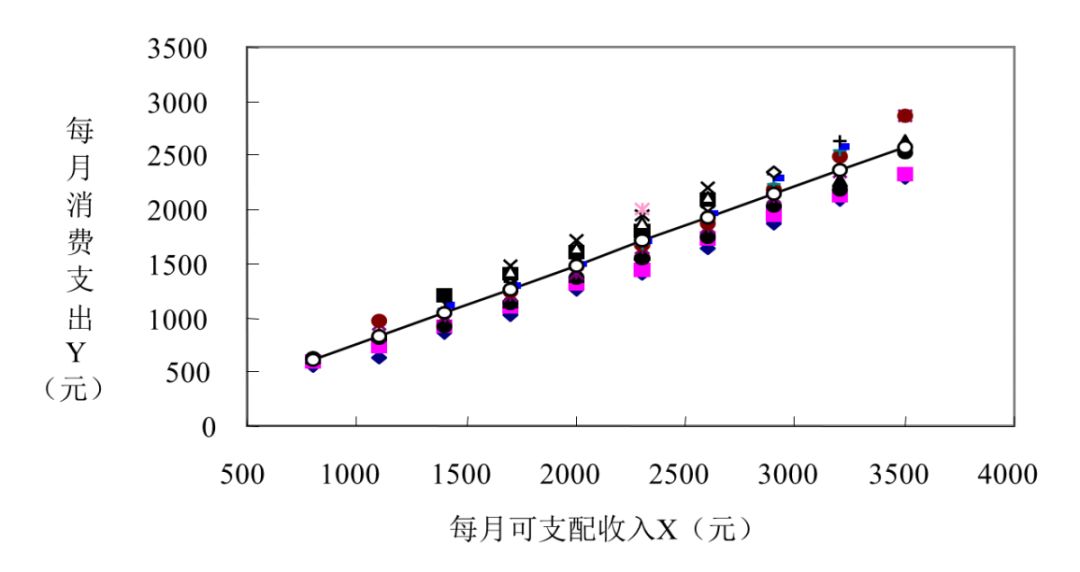
图5-3 某社区消费支出散点图
总体回归函数描述了在给定的收入水平X下,家庭的平均消费支出水平。但对某一个别的家庭,其消费支出可能与该平均水平有偏差。记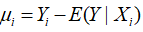 ,这是一个不可观测的随机变量,称为随机误差项(error term)或随机干扰项(disturbance)。
,这是一个不可观测的随机变量,称为随机误差项(error term)或随机干扰项(disturbance)。
例5.3中,个别家庭的消费支出为:
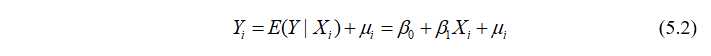
即给定收入水平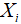 ,个别家庭的消费支出可表示为两部分之和:(1)该收入水平下所有家庭的平均消费支出
,个别家庭的消费支出可表示为两部分之和:(1)该收入水平下所有家庭的平均消费支出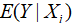 ,称为系统性(systematic)或确定性(deterministic)部分;(2)其他随机或非确定性(nonsystematic)部分
,称为系统性(systematic)或确定性(deterministic)部分;(2)其他随机或非确定性(nonsystematic)部分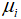 。
。
例5.1的数据实际上是从例5.3的总体中抽取出来的样本数据,样本的散点图见图5-1。从图5-1的样本散点图可以看出这些散点近似于一条直线,自然的想法是能否画一条直线尽可能好地拟合这些散点,这条直线称为样本回归线(sample regression lines)。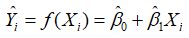 ,称为样本回归函数(sample regression function, SRF)。样本回归函数也有如下的随机形式:
,称为样本回归函数(sample regression function, SRF)。样本回归函数也有如下的随机形式: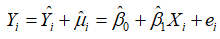 。其中,
。其中,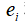 称为残差(residual),代表了其他影响的随机因素的集合,可以看成是的估计量
称为残差(residual),代表了其他影响的随机因素的集合,可以看成是的估计量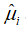 。
。
回归分析的主要目的是要通过样本回归函数(模型)SRF尽可能准确地估计总体回归函数(模型)PRF,即根据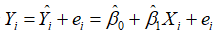 去估计
去估计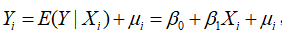 ,或者说利用
,或者说利用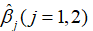 去估计
去估计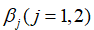 。参数估计方法有多种,其中使用最广泛的是普通最小二乘估计法(ordinary least squares, OLS)和极大似然估计法(Maximum Likelihood Estimation, MLE)。
。参数估计方法有多种,其中使用最广泛的是普通最小二乘估计法(ordinary least squares, OLS)和极大似然估计法(Maximum Likelihood Estimation, MLE)。
为保证参数估计量具有良好的性质,通常要求模型满足若干基本假设:
假设1 自变量X是确定的,不是随机变量;
假设2 随机误差项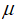 具有零均值、同方差和无序列相关性,即:
具有零均值、同方差和无序列相关性,即:
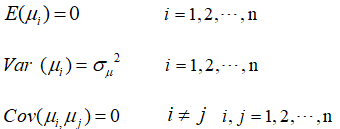
假设3 随机误差项与自变量X之间不相关,即:
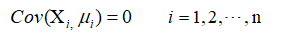
假设4 服从正态分布,即
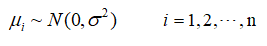
以上假设也称为线性回归模型的经典假设或高斯(Gauss)假设,满足该假设的线性回归模型,也称为经典线性回归模型(Classical Linear Regression Model, CLRM)。
(一)普通最小二乘估计(OLS)
普通最小二乘法(Ordinary least squares, OLS)是求解参数,使得样本观测值和拟合值之差的平方和最小,即:
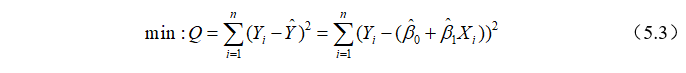
式(5.3)对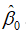 和
和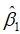 分别求一阶导后可得正规方程组(normal equations):
分别求一阶导后可得正规方程组(normal equations):
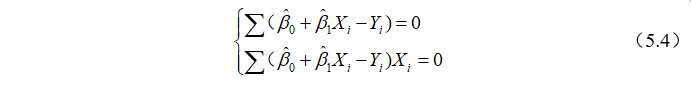
解正规方程组(5.4)可得:
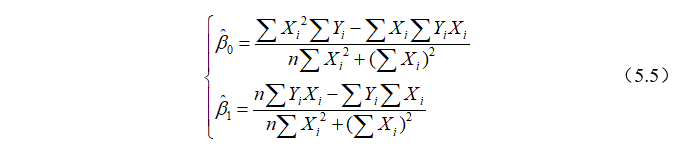
为了方便,常常记
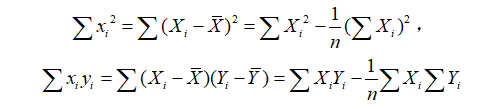
因此,上述参数估计量也可以写成
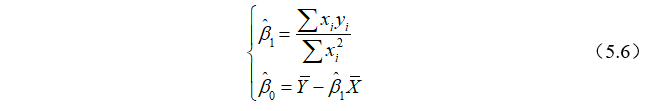
当模型参数估计出后,需考察参数估计量的统计性质,可从如下几个方面考察其优劣性:
(1)线性性,即它是否是另一随机变量的线性函数;
(2)无偏性,即它的期望值是否等于总体的真实值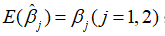 ;
;
(3)有效性,即它是否在所有线性无偏估计量中具有最小方差。
这三个准则也称作估计量的小样本性质。拥有以上性质的估计量称为最佳线性无偏估计量(best liner unbiased estimator, BLUE)。
可以证明最小二乘法估计量具有高斯——马尔可夫定理(Gauss-Markov theorem):在给定经典线性回归的假定下,最小二乘估计量是具有最小方差的线性无偏估计量(best linear unbiased estimator, BLUE)。定理的具体证明请参考相关教材(Greene, 2012;朱建平等,2009;李子奈等,2010)。
(二)参数估计量的概率分布及随机干扰项方差的估计
参数估计量与的概率分布。普通最小二乘估计量、分别是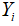 的线性组合,所以与的分布取决于Y的分布。在是正态分布的假设下,Y也是正态分布,则、也服从正态分布,分别为
的线性组合,所以与的分布取决于Y的分布。在是正态分布的假设下,Y也是正态分布,则、也服从正态分布,分别为
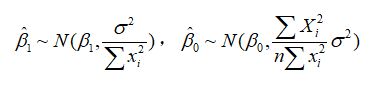
随机误差项的方差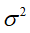 的估计。与的方差中,都含有随机扰动项的方差。由于实际上是未知的,因此与的方差实际上无法计算,这就需要对其进行估计。由于随机项不可观测,只能从的估计(残差)出发,对进行估计。
的估计。与的方差中,都含有随机扰动项的方差。由于实际上是未知的,因此与的方差实际上无法计算,这就需要对其进行估计。由于随机项不可观测,只能从的估计(残差)出发,对进行估计。
的最小二乘估计量为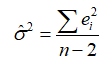 ,可以证明它是的无偏估计量。
,可以证明它是的无偏估计量。
因此,参数与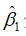 的方差和标准差的估计量分别是:
的方差和标准差的估计量分别是:

回归分析的目的是要通过样本所估计的参数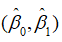 来代替总体的真实参数
来代替总体的真实参数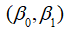 ,或者说是用样本回归线代替总体回归线。尽管从统计性质上可以保证如果有足够多的重复抽样,参数的估计值的期望(均值)就等于其总体的参数真值,即具有无偏性。但在一次抽样中,估计值不一定就等于该真值。那么,在一次抽样中,参数的估计值与真值的差异有多大、是否显著,这就需要进一步进行统计检验,主要有拟合优度检验、变量的显著性检验。
,或者说是用样本回归线代替总体回归线。尽管从统计性质上可以保证如果有足够多的重复抽样,参数的估计值的期望(均值)就等于其总体的参数真值,即具有无偏性。但在一次抽样中,估计值不一定就等于该真值。那么,在一次抽样中,参数的估计值与真值的差异有多大、是否显著,这就需要进一步进行统计检验,主要有拟合优度检验、变量的显著性检验。
(一)拟合优度检验
拟合优度检验是对回归拟合值与观测值之间拟合程度的一种检验。度量拟合优度的指标主要是判定系数(可决系数)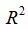 。要理解需先理解总离差平方和的分解。
。要理解需先理解总离差平方和的分解。
Y
的第
i
个观测值与样本均值的离差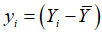 可分解为两部分之和:
可分解为两部分之和:
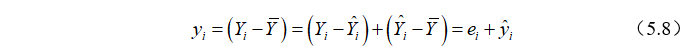
其中,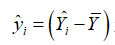 是样本回归拟合值与观测值的平均值之差,可认为是由回归直线解释的部分;
是样本回归拟合值与观测值的平均值之差,可认为是由回归直线解释的部分;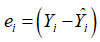 是实际观测值与回归拟合值之差,是回归直线不能解释的部分。如果
是实际观测值与回归拟合值之差,是回归直线不能解释的部分。如果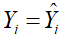 即实际观测值落在样本回归“线”上,则拟合得最好。对于所有样本点,则需考虑这些点与样本均值离差的平方和,可以证明:
即实际观测值落在样本回归“线”上,则拟合得最好。对于所有样本点,则需考虑这些点与样本均值离差的平方和,可以证明:
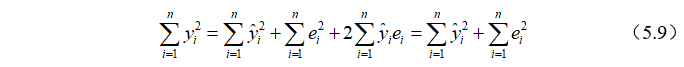
记:

三者之间有如下关系: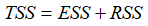 ,所以,Y的观测值围绕其均值的总离差(total variation)可分解为两部分:一部分来自回归 (ESS),另一部分则来自随机因素(RSS)。在给定样本下,TSS不变,如果实际观测点离样本回归线越近,则ESS在TSS中占的比重越大。
,所以,Y的观测值围绕其均值的总离差(total variation)可分解为两部分:一部分来自回归 (ESS),另一部分则来自随机因素(RSS)。在给定样本下,TSS不变,如果实际观测点离样本回归线越近,则ESS在TSS中占的比重越大。
记,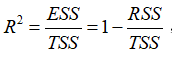 称为可决系数(coefficient of determination)。的取值范围为[0,1],越接近1,说明实际观测点离样本线越近,拟合优度越高。
称为可决系数(coefficient of determination)。的取值范围为[0,1],越接近1,说明实际观测点离样本线越近,拟合优度越高。
(二)变量显著性检验
回归分析的目的之一是要判断X是否是Y的一个显著影响因素。这就需要进行变量的显著性检验。我们已经知道回归系数估计量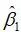 服从正态分布,即
服从正态分布,即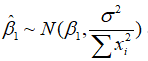 。又由于真实的未知,利用它的无偏估计量
。又由于真实的未知,利用它的无偏估计量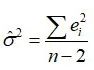 替代时,可构造检验统计量
替代时,可构造检验统计量
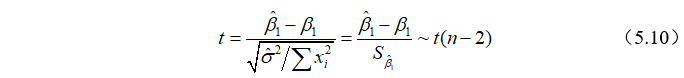
进行检验。具体的检验步骤为:
(1)对总体参数提出假设
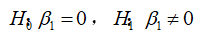
(2)在原假设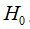 成立下,构造t统计量
成立下,构造t统计量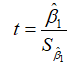 ;
;
(3)给定显著性水平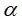 ,查t分布表,得临界值
,查t分布表,得临界值 ;
;
(4)比较,判断:

对于一元线性回归方程中的截距项,同理可构造如下统计量:
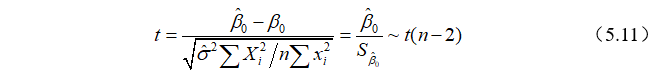
具体的检验步骤与的检验步骤类似,在此就不再赘述。
对于拟合得到的一元线性回归模型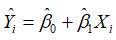 , 给定样本以外的自变量观测值
, 给定样本以外的自变量观测值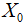 ,可以得到因变量的预测值
,可以得到因变量的预测值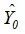 ,并以此作为其条件均值
,并以此作为其条件均值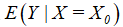 或个别值
或个别值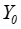 的一个近似估计,我们称之为点预测。给定显著性水平下,可以求出的预测区间,我们称之为区间预测。
的一个近似估计,我们称之为点预测。给定显著性水平下,可以求出的预测区间,我们称之为区间预测。
(一)点预测
对总体回归函数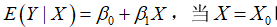 时,
时,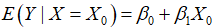 。通过样本回归函数
。通过样本回归函数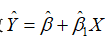 ,求得拟合值为
,求得拟合值为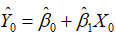 ,于是两边取期望可得,
,于是两边取期望可得,
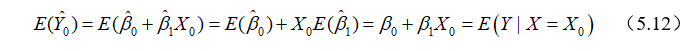
可见,是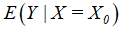 的无偏估计。
的无偏估计。
对总体回归模型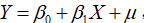 ,当
,当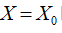 时,
时,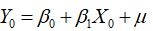 ,两边取期望可得
,两边取期望可得
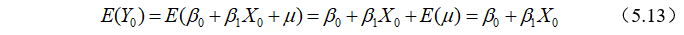
而通过样本回归函数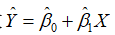 ,求得拟合值为
,求得拟合值为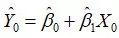 的期望为
的期望为
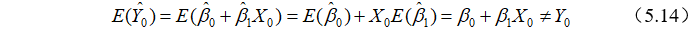
可见不是个值的无偏估计。
(二)区间预测
由于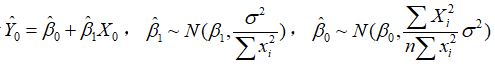 可以证明,
可以证明,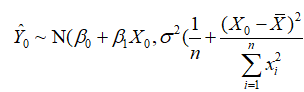 )),由于未知,
)),由于未知,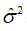 将代替,可构造t统计量:
将代替,可构造t统计量:
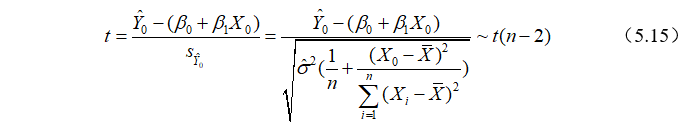
于是,在给定显著性水平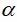 下,总体均值
下,总体均值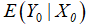 的置信区间为:
的置信区间为:
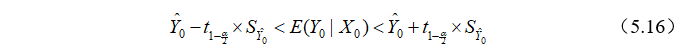
这也称为的区间预测。
由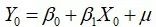 可得
可得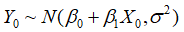 ,于是我们可以得到
,于是我们可以得到 的分布
的分布
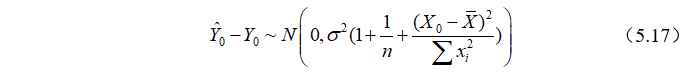
将代替,可构造t统计量:
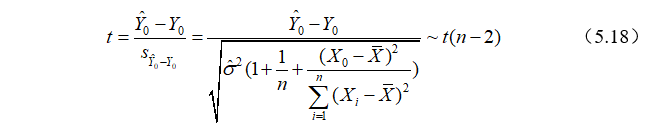
于是,在给定显著性水平下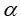 ,的置信区间为:
,的置信区间为:
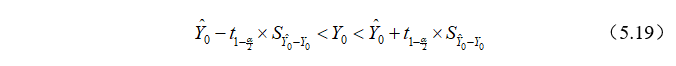
这也称为的区间预测。
R里OLS的估计可用lm()函数。lm()的用法是lm ( formula , data , subset , weights , na.action , method = "qr" ,...)
其中formula表示回归里的表达式,一般是y ~ X,“~”左边是因变量,“~”右边是自变量,默认是包含截距项,如果不需要截距项的可以在自变量前面加“-1”,即y ~ -1 + X。
比如,例5.1的OLS估计结果为:
> lm1 # 将回归结果保存在lm1对象里
> coef ( lm1 ) # 提取估计系数
(Intercept) income
-103.1717172 0.7770101
> coef ( lm ( consum ~ - 1 + income ) )
income
0.7356645例5.1的和的OLS估计结果分别是-103.17和0.78。如果去掉截距项后,回归系数是0.74。
再比如,例5.2的OLS估计结果为:
> lm2 > coef ( lm2 )
(Intercept) x
210.0484584 -0.7977266
例5.2的和的OLS估计结果分别210.05和-0.80。
R里求OLS的方差估计量,需要用summary()函数先将lm()的结果保存在slm对象里,然后提取sigma成分,即为。若要计算参数与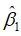 的标准差,先提取出coef矩阵,然后再提取矩阵的第二列即为参数与
的标准差,先提取出coef矩阵,然后再提取矩阵的第二列即为参数与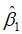 的标准差。
的标准差。
例5.1的估计结果为:
> slm > slm $ sigma # 得到总体方差的OLS估计量
[1] 115.767
> slm $ coef # 得到系数有关的矩阵
Estimate Std. Error t value Pr(>|t|)
(Intercept) -103.1717172 98.4059798 -1.048429 3.250795e-01
income 0.7770101 0.0424851 18.289003 8.217449e-08
> slm $ coef [ , 2 ] # 矩阵第二列,即系数标准差
(Intercept) income
98.4059798 0.0424851例5.1中为115.767,与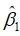 的样本标准差分别为98.41和0.042。
的样本标准差分别为98.41和0.042。
R里求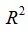 ,只要在上文的slm对象里提取r.squared成分即可。
,只要在上文的slm对象里提取r.squared成分即可。
> slm $ r.squared
[1] 0.9766415说明例5.1回归模型的拟合效果都不错。
如果回归的残差,可以直接在lm1上调用resid()函数得到,例如
> resid ( lm1 )
1 2 3 4 5 6 7 8 9 10
75.56 -113.54 137.36 -62.75 -42.85 -88.95 51.95 -72.16 201.74 -86.36R里summary()函数会自动提供线性回归的t检验,可以通过slm $ coef提取得到回归系数估计值、标准差、t值和相应的p-value。
例5.1的变量显著性检验程序和结果:
> slm > slm
Call:
lm(formula = consum ~ income)
Residuals:
Min 1Q Median 3Q Max
-113.54 -82.81 -52.80 69.66 201.74
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -103.17172 98.40598 -1.048 0.325
income 0.77701 0.04249 18.289 8.22e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 115.8 on 8 degrees of freedom
Multiple R-squared: 0.9766, Adjusted R-squared: 0.9737
F-statistic: 334.5 on 1 and 8 DF, p-value: 8.217e-08
> slm $ coef [ , 3 ] # 提取t值
(Intercept) income
-1.048429 18.289003
> slm $ coef [ , 4 ] # 提取t值的p-value
(Intercept) income
3.250795e-01 8.217449e-08例5.1的和 的t值分别为-1.048429和18.289003,对应的p-value分别为3.250795e-01和8.217449e-08,说明不显著,而
的t值分别为-1.048429和18.289003,对应的p-value分别为3.250795e-01和8.217449e-08,说明不显著,而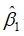 显著。
显著。
在R里求均值预测区间可以用predict()函数,但要在interval参数设为confidence,如果求个值的预测区间需要在interval参数设为prediction。例5.1中,当收入为4000元时,我们求和的区间预测。
> predict ( lm1 , newdata = data.frame ( income = 4000 ) ,
interval = "confidence" , level = 0.95 ) # 均值预测区间,level为置信度
fit lwr upr
13004.869 2804.927 3204.811
> predict ( lm1 , newdata = data.frame ( income = 4000 ) ,
interval = "prediction" , level = 0.95 ) # 个值预测区间
fit lwr upr
13004.869 2671.336 3338.401结果中fit值是点预测值,lwr和upr分别是区间预测的上限和下限。例5.1中,当收入为4000元时,我们求和的置信度为95%时的预测区间分别为[2804.927, 3204.811]和[2671.336, 3338.401],并且的预测区间要比的预测区间要宽,这与理论结果一致。
下面将例5.1的样本内观测值、回归线、均值预测区间、个值预测区间画在同一张图上,如图5-4所示。
> sx # 把自变量先从小到大排序
# 求均值的预测区间
> conf "confidence" )
# 求个值的预测区间
> pred "prediction" )
> plot ( income , consum ) # 画散点图
> abline ( lm1 ) # 添加回归线
> lines ( sx , conf [ , 2 ] ) ; lines ( sx , conf [ , 3 ] )
> lines ( sx , pred [ , 2 ] , lty = 3 ) ; lines ( sx , pred [ , 3] , lty = 3 )
图5-4 区间预测
图5-4的散点是实际观测值,中间的直线是拟合的回归线,两边的两条实线是总体均值的预测区间(置信区间),最外面的两条虚线是个体值的预测区间。分析Y的总体均值与个体值的预测区间及其图形,我们发现:
(1)样本容量n越大,预测精度越高,反之预测精度越低;
(2)样本容量一定时,置信带的宽度当在X均值处最小,其附近进行预测(插值预测)精度越大;X越远离其均值,置信带越宽,预测可信度下降。
更多内容请见《数据科学》一书!
注:由于微信排版限制,部分公式未对齐,书籍中均正常。
▼往期精彩回顾▼第1讲:数据科学导论第2讲:R语言数据读写第3讲:数据清洗与预处理第4讲:数据可视化
作者简介
方匡南,厦门大学经济学院教授、博士生导师、耶鲁大学博士后、厦门大学数据挖掘研究中心副主任。入选国家“万人计划”青年拔尖人才,国际统计学会推选会士(ISI Elected member),全国工业统计学会常务理事、数据科学与商业智能学会常务理事,中国青年统计学家协会常务理事等。主要研究方向为 数据科学,机器学习,应用统计。先后与华为、华星光电、厦门国际银行、南方电网、普益标准、北京诺信创联等众多企业有联合研究,先后为联通、华星光电、建设银行、农业银行、国元集团等众多企业提供培训。

欢迎选购作者新作《数据科学》
了解更多详情
﹏﹏﹏﹏京东自营

当当自营

















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









