






这篇继续来聊一下调试与剖析这个话题。
一般软件调试使用GDB来进行,不过对GDB熟悉的不一定多。我认识的几个Google出来的工程师,使用GDB并不多。其中一个Google的工程师甚至说,使用glog打印一些日志,基本就可以看出问题了,要什么GDB啊。
如果说代码质量比较高的话,边界的测试比较多,确实不太需要使用到GDB。不过大型项目就不好说的,因为依赖的代码错综复杂,可能你的代码质量很高,但是依赖的third party质量一般,有一些隐藏的Bug,甚至操作系统有一些隐藏的Bug也不无可能,所以还是需要学会一些调试技巧。
接触的Google相关的调试技巧并不多,其中有一个是用于收集崩溃报告的。一般我们发生了crash,会生成core dump文件,但是core dump文件很大,存储和上传都比较困难,这时候是否可以考虑生成一个比较小的文件,包括一些比较关键的信息呢?当然是可以的,Google 就有一个开源的C++项目,叫做breakpad,官方是这么介绍的:
Breakpad is a library and tool suite that allows you to distribute an application to users with compiler-provided debugging information removed, record crashes in compact “minidump” files, send them back to your server, and produce C and C++ stack traces from these minidumps. Breakpad can also write minidumps on request for programs that have not crashed.
Breakpad项目目前被以下项目使用到:Google Chrome, Firefox, Google Picasa, Camino, Google Earth等。
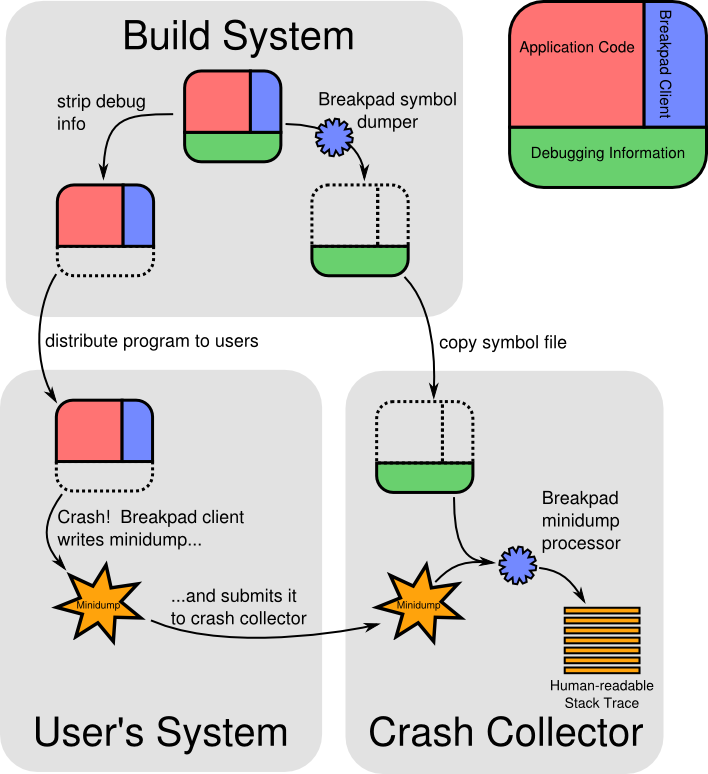
breakpad主要包含三部分:client, symbol dumper 和 processor。client负责生成minidump文件,symbol dumper 则定义了自己的一个文件格式,读取编译器生成的调试信息,转换为自定义的符号文件。而processor则负责读取上传到服务器段的minidump文件,为相关版本的二进制文件和minidump文件提到的动态库查找对应的符号文件,然后生成人可读的C/C++堆栈信息。
以我的理解,breakpad主要就几个事情:
1,怎么捕获和处理各个平台的异常,然后在处理函数中,收集必要的信息并保持到文件中。需要设计一个自定义的文件格式,格式应该比较紧凑。
2,将信息上传到服务器。
3,服务器存储minidump文件的时候,按照相关版本的binary来索引。
4,要使用minidump来分析问题的时候,需要将相关的binary,动态库都找到,然后生成函数堆栈信息。怎么去遍历堆栈信息,打印出函数名等比较方便定位到相关代码的信息,是比较关键的,可以参考以下文档:
https://chromium.googlesource.com/breakpad/breakpad/+/master/docs/stack_walking.md
总结下软件调试:
1,代码质量过硬的话,确实在日常开发中不太需要使用到比较复杂的GDB调试技巧。
2,复杂项目,难免出现软件崩溃、内存泄露、死锁等问题,掌握一些调试技巧还是有帮助的。
3,复杂环境,比如客户端软件,典型的比如浏览器,聊天软件,下载软件等,一般都会出现崩溃,比如大家在使用电脑的过程中,应该碰到过不少次IE浏览器异常退出,QQ崩溃,或者电驴软件崩溃等现象。这个时候就要求客户端软件能够在崩溃的时候,能够自动收集崩溃信息到后台,从而在后台能够定位问题,让软件在下一个版本变得更加稳定。
聊完了调试部分,我们接着再来说剖析(Profiling)。一般有两个场景,一个是看内存的使用情况(Heap profiling),比如,看看内存都被哪些代码分配的,从而给内存优化找到放心,再比如,另一个是出现了内存泄露的话,怎么去定位并解决。一个是看CPU资源都被哪些代码使用了,以有的放矢地开展性能优化。
做这些性能剖析,Google内部使用比较多的gperftools,开源版本的项目的地址为:
https://github.com/gperftools/gperftools
官方是这么介绍的:
The fastest malloc we’ve seen; works particularly well with threads and STL. Also: thread-friendly heap-checker, heap-profiler, and cpu-profiler.gperftools is a collection of a high-performance multi-threaded malloc() implementation, plus some pretty nifty performance analysis tools.
简单来说就是,它是Google内部使用的性能分析工具。该项目实现了性能非常好的malloc版本tcmalloc, 并且多线程安全,和STL的兼容性也很好。此外,它还实现了一些剖析工具,比如内存剖析、内存泄露检测、CPU剖析。
tcmalloc 我没有系统介绍过,不过类似的实现jemalloc, 本公众号曾经详细介绍过,没读过的推荐看看:《【译】使用jemalloc实现可扩展的内存分配》。本文就不具体介绍tcmalloc的实现了,放一下之前这篇文件的个人文字吧:
大家在编程中经常使用 malloc() 函数,很多工程师可能觉得这是一个系统调用,其实不是的,mmap(), sbrk() 等才是系统调用,malloc() 是 glibc 等内存分配器中实现的内存分配函数,是用户态函数。
如果大家对 malloc 的实现比较感兴趣,可以去下载 glibc 的源代码阅读。malloc 的 glibc 实现,有不少不足之处,其中就包括内存峰值比较高(分配器自身的 overhead 大),线程多的时候内存分配比较慢等问题。工业界常用的还有 tcmalloc 和 jemalloc, 前者在谷歌内部广泛使用,后者在 Facebook 内部广泛使用。这篇文章是 jemalloc 的作者 Jason Evans 写的,内容切中要害,也还算通俗易懂,因此翻译出来,和读者分享。文中根据我自己的理解和经验,补充了一定的译注,希望对读者阅读有帮助。
考虑以后找个时间写一两篇介绍谷歌 tcmalloc 的文章。目前我们公司内部使用 tcmalloc 更多一些,我本人也详细阅读过 tcmalloc 的源代码,并根据项目需求,做过一定的改造,以解决一些难搞的内存问题。
值得一提的是,tcmalloc 的作者,就是和 Jeff Dean 齐名的谷歌大神 Sanjay Ghemawat,最近有几篇文章讲他们的传奇故事的。jeaf dean 的代码,可以看看开源的 leveldb, Sanjay的代码,我搜索了下,似乎就只有tcmalloc 是开源的了。如果读者们也膜拜这两位工业界的大神,不妨找来他们的开源项目,读读代码。后续有时间的话,我会写篇文章介绍下他们两位开源的项目,在谷歌内部广为人知的项目,以及他们发表的一些论文和对外分享的 PPT。
在我工作的第一家公司里,所有的binary都是默认链接tcmalloc的,大部分情况下,性能会得到不少提升。
下面通过一张图来大概看看tcmalloc的内部架构:
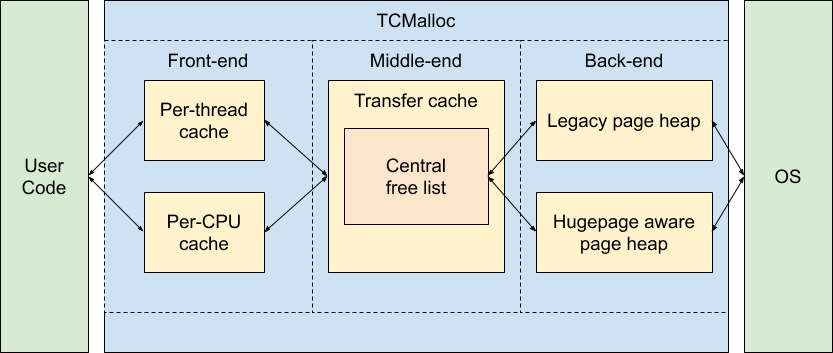
想要了解tcmalloc原理的,可以详细阅读下这篇文档:
https://github.com/google/tcmalloc/blob/master/docs/design.md
有关内存问题,有时候我们是为了分析内存都去哪里了,有时候是要找出来内存泄露在哪里。如果泄露的内存很大,一般做一下heap profiling,就可以快速定位出来了,因为跑得越久,泄露内存的地方,占据内存的比例越大。而如果内存泄露很小,比如跑一天下来,才泄露几M内存,就不容易通过heap profiling来定位了。这类问题,我们往往是通过在单元测试中进行内存泄露检测来实现的。在测试程序结束的时候,将内存检测的结果输出,如果发现了泄露,就生成一个报告,必要的话,就让整个测试的结果判定为失败。
内存泄露问题相对来说比较复杂,比如上面提及的泄露几M的问题,也可以通过输出多个profiler文件,比较各个函数分配的内存比例,来定位随着运行时间越长,哪些函数分配的内存比例越高。也就是说,无法通过一份profiler文件来定位,因为可能分配的内存很小,泄露了很多次,总体的内存占比也不够高。这时候就只好通过对比比例的变化,来判定是否出现了泄露了。
再说一个内存分析的问题。有时候在嵌入式平台,运行heap profiling是非常慢的,主要是因为stack unwind过程非常慢。有时候一个程序运行十几个小时,我们才确认出现了内存泄露的现象,这个时候如果打开heap profiling,程序的运行速度会成数量级的降低,很可能需要跑好几个月,才能从profiling result中看出问题。而这显然不具有可行性,就和机器学习训练任务一样,如果一个训练任务需要好几个月,做实验的话肯定连自杀的心都有了。当时我们的解决方案是,给gperftools打了个补丁,对stack unwind操作做了一定的采样比例,从而让程序的运行速度保持在同一个数量级上。通过这个改动,解决了一两个顽固的内存泄露问题。
说完了内存剖析,就是性能分析了。那么Google的CPU profiling怎么使用呢?大概分为三步:1,链接gperftools library到二进制,2,运行程序,3,使用pprof工具分析,输出profiling结果。想要了解更多细节的,可以阅读下面的文章:
https://gperftools.github.io/gperftools/cpuprofile.html
通过做cpu profiling,可以拿到某个函数消耗CPU的大概比例。比如下图:
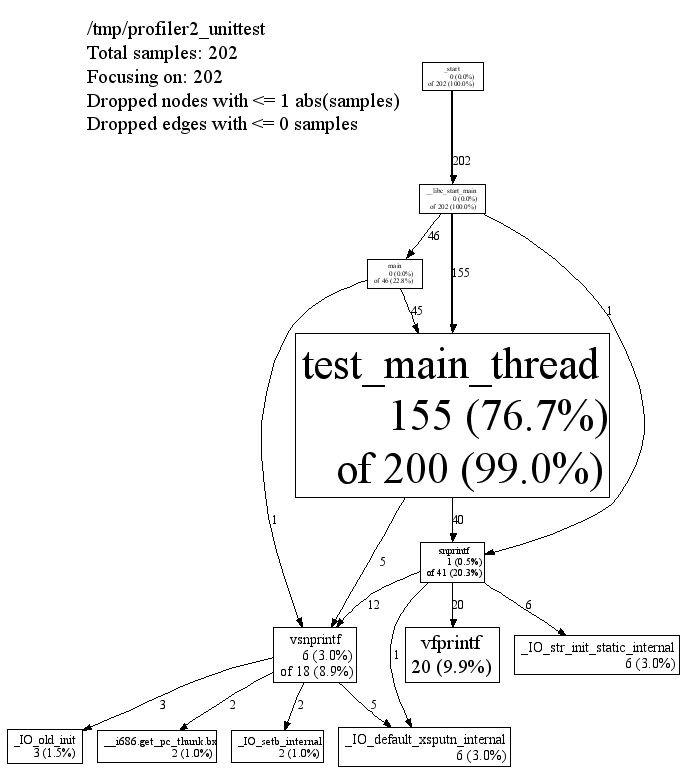
从图中可以比较方便地看出来,如果要进行性能优化的话,优先级应该安排安排(按照图中矩形的面积大小即可)。除了上面的输出方式外,其实输出火焰图方式的性能剖析工具也比较流行,有兴趣的可以自行搜索下。
说到性能分析,我面试过的大部分工程师,都不知道怎么在不看具体代码的情况下,去对程序的性能问题进行大概的摸底调研。换句话说,类似gperftools的工具,大部分工程师都没有使用过。
不过有了工具其实还不够,主要还是要掌握足够多的性能优化技巧。性能优化方面,我之前写过几篇短文,列在这里:
《GCC编译器中的性能优化》
《推荐与批评》
《性能优化分享 -- static search set 篇》
《性能优化之—通才与专才》
有关性能优化部分,计划近期专门写一篇文章,详细总结下之前的经验,另外也总结下阅读过的比较不错的书籍,以及文章。希望通过那篇文章,给之前几年在性能优化方面做过的学习和探索做一个总结。














 8016
8016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









