






本篇文章是设计一个关于数据库比较常用但是却没有关心的一个问题,希望它能给你带来一些思考。
导致的结果
效率低,效率低,效率低!!
原因总结
不需要的列会增加数据传输时间和网络开销
对于无用的大字段,如 varchar、blob、text,会增加 io 操作
失去MySQL优化器“覆盖索引”策略优化的可能性
阿里巴巴都有明文规定
【强制】在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。
说明:
增加查询分析器解析成本。
增减字段容易与 resultMap 配置不一致。
无用字段增加网络 消耗,尤其是 text 类型的字段。
原因详解
1. 不需要的列会增加数据传输时间和网络开销
用“SELECT * ”数据库需要解析更多的对象、字段、权限、属性等相关内容,在 SQL 语句复杂,硬解析较多的情况下,会对数据库造成沉重的负担。
增大网络开销;* 有时会误带上如log、IconMD5之类的无用且大文本字段,数据传输size会几何增涨。如果DB和应用程序不在同一台机器,这种开销非常明显
即使 mysql 服务器和客户端是在同一台机器上,使用的协议还是 tcp,通信也是需要额外的时间。
2. 对于无用的大字段,如 varchar、blob、text,会增加 io 操作
准确来说,长度超过 728 字节的时候,会先把超出的数据序列化到另外一个地方,因此读取这条记录会增加一次 io 操作。(MySQL InnoDB)
3. 失去MySQL优化器“覆盖索引”策略优化的可能性
SELECT * 杜绝了覆盖索引的可能性,而基于MySQL优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式。
例如,有一个表为t(a,b,c,d,e,f),其中,a为主键,b列有索引。
那么,在磁盘上有两棵 B+ 树,即聚集索引和辅助索引(包括单列索引、联合索引),分别保存(a,b,c,d,e,f)和(a,b),如果查询条件中where条件可以通过b列的索引过滤掉一部分记录,查询就会先走辅助索引,如果用户只需要a列和b列的数据,直接通过辅助索引就可以知道用户查询的数据。
如果用户使用select *,获取了不需要的数据,则首先通过辅助索引过滤数据,然后再通过聚集索引获取所有的列,这就多了一次b+树查询,速度必然会慢很多。
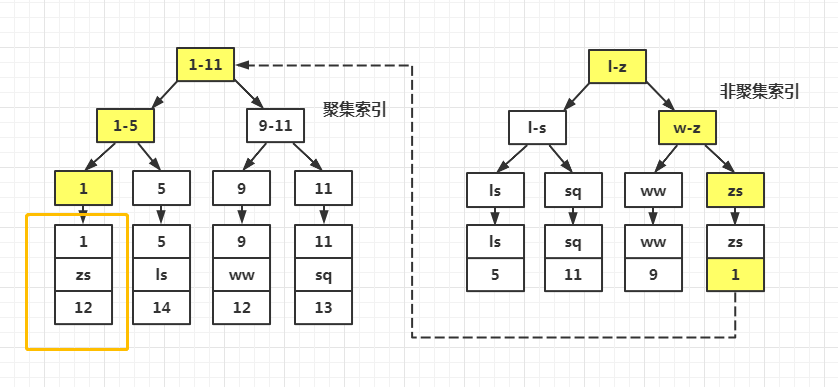
由于辅助索引的数据比聚集索引少很多,很多情况下,通过辅助索引进行覆盖索引(通过索引就能获取用户需要的所有列),都不需要读磁盘,直接从内存取,而聚集索引很可能数据在磁盘(外存)中(取决于buffer pool的大小和命中率),这种情况下,一个是内存读,一个是磁盘读,速度差异就很显著了,几乎是数量级的差异。
总结
当然这不是说硬性要求,但是这是一个可以优化的点,所以,也希望能够从点滴开始。
备注:
如果数据量小影响可以省略‘
如果表的所有字段也就4-5个,那么影响也可以省略’
像我这一天300W的数据量,那么对比起来还是确实有提升的感觉;
如果你觉得学到了知识,别忘记转发给你周围的小伙伴陪你一起学习哦!互相学习才是最好的学习!双手抱拳,感谢你的阅读和分享!















 1989
1989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









