





你好,我是甜恬。
感谢你肯花时间读我的文章,希望我们可以成为朋友,在这奔流不息的世界,可以相互学习共同进步。
上回书说到Python对于Excel的操作,本回书咱们来说一说Python对于Word的操作。这次的需求是这样的:把若干个Word文档转换为PDF格式。起因呢,是因为公司经常会披露公告、法律文件等,这些文件在编辑的时候都是以Word的形式,而正式发布的时候则需要是PDF格式,可能有的时候数量比较多就不能手工一个个转换而需要批量转换工具。
有同学可能会问,网上工具那么多,甚至还有在线转换的,为啥还要自己写代码?
那还用问?自己写代码显得牛X呀。
开个玩笑,正经的原因如下:
1、 用软件或在线转换不太安全,尤其是保密文件
2、 有些公司对于软件下载安装有严格的策略控制
3、 市场上各类软件良莠不齐,小心“中招”
话不多说了,先看代码和结果。
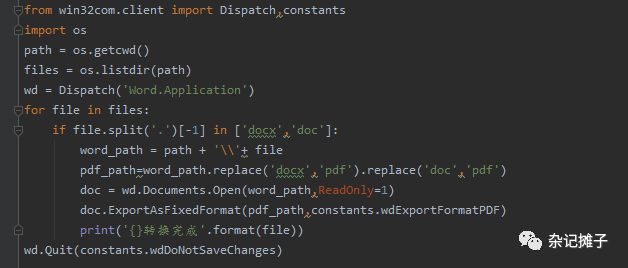
Python代码
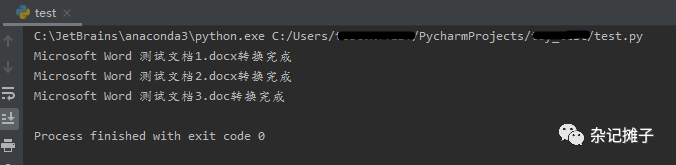
代码执行结果

PDF文件转换结果
01 win32com是模块吗?为什么pypi搜索不到?
还记得上回我们在操作Excel的时候,用到了“模块”这一概念,当时“模块”是采用从http://pypi.org下载安装的方式得到的。而本次,我们使用比模块更深奥的“库”。通俗理解下,包包含“模块”;库包括好多“包”;框架继承了多个“库”。从本质上来说,这些东西都是“模块”,其用法也都比较类似。那么本次我们使用的win32com正是属于库中的一个包,它是涵盖在pywin32这个库中的。因此我们需要pip安装pywin32才能使用win32com这个包。
我们来看代码当中的第一句:
from win32com.client import Dispatch,constants,gencache
这句代码的意思就是引入win32com包中的client模块,但仅引入Dispatch,constants,gencache这三个成员。如果引入client模块的所有而不限制成员可以写为:
from win32com import client
但是如果引入所有,那么在接下来代码中,都要使用“包.成员名”这一形式来进行使用,如果数量比较少的话还好,但是多了就会比较麻烦。更多的引入方式及说明请见附录。
这里再给大家简单介绍一下pywin32。pywin32是一个第三方模块库,直接包装了几乎所有的Windows API,主要的作用是使Python开发者可以方便快速的调用Windows API。同时pywin32也是绝大部分windows上第三方python模块库的前提,例如wmi,如果没有安装pywin32是无法正常使用wmi这个第三方模块库的。
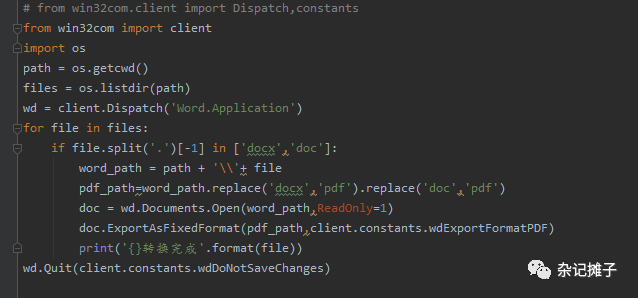
引入client模块的所有而不限制成员的写法
02 逐句分解
新概念就说到这,接下来进行需求及代码分解。我们这个程序采用的是模仿人操作的方式,调用VBA实现这一过程。那么,要实现Word转PDF这一需求,如果是你,你会怎么操作?
1、 打开所要转换的一个Word文件
2、 点击文件-另存为
3、 下拉框选择PDF格式-保存
4、 循环打开下一个Word文件
通过上述流程,我们深入考虑一下,如果是程序呢,应该会包括些什么步骤?
首先最主要的肯定是一个循环,因为我们需要反复读取Word直到将所有Word都转成了PDF;其次应该就是转换了,在VBA中,我们可以使用wdExportFormatPDF代替人工下拉框选择PDF格式-保存这一操作;最后就是命名了,我们需要的是转换后的PDF和转换前的Word同名,因此对于名称我们也需要进行处理。
分析完成,那我们的程序也逐渐清晰了,我将核心内容摘出来一句句解释:
if file.split('.')[-1] in ['docx','doc']:
这句主要的作用是找出文件夹内的所有Word文档。我们都知道Word文档一般都是.docx和.doc结尾的,那我这里采用的是将文件名按.分割为两部分,找到第二部分属于['docx','doc']的文件进入循环。
pdf_path=word_path.replace('docx','pdf').replace('doc','pdf')
定义生成的PDF路径,我采用的是生成的PDF在原路径,你也可以按需定义。
doc = wd.Documents.Open(word_path,ReadOnly=1)
以只读方式打开当前Word。
doc.ExportAsFixedFormat(pdf_path, constants.wdExportFormatPDF)
这句是整个程序的核心部分,它所实现的功能就是调用VBA函数,使Word转换成PDF。VBA函数的语法是这样的:
ExportAsFixedFormat(OutputFileName、 microsoft.office.infopath.exportformat、 OpenAfterExport、 OptimizeFor、 Range、 From、 To、 Item、 IncludeDocProps、 KeepIRM、 CreateBookmarks、DocStructureTags、 BitmapMissingFonts、 UseISO19005_1、 FixedFormatExtClassPtr)
具体函数用法可参见微软提供的官方说明:https://docs.microsoft.com/zh-cn/office/vba/api/word.document.exportasfixedformat
03 进阶一下
我们再来看一下这句代码
pdf_path=word_path.replace('docx','pdf').replace('doc','pdf')
它的意思是将文件的拓展名docx和doc替换为pdf,生成正常的pdf名。细心的你会不会有疑问,如果Word文件名中就含有docx或doc,那不是也被替换了?
没错!使用replace函数替换确实会存在这个问题,它会将所有检测到的字符都替换掉。那么有没有别的函数,只替换掉末尾的docx和doc?
函数我暂时没找到,如果你知道请一定告诉我。
我这里要介绍的是采用正则表达式这一方法。正则表达式描述了一种字符串匹配的模式,可以用来检查一个字符串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。学会灵活运用正则表达式,可以让你的字符串的处理是事半功倍。具体详细的介绍网上都有,请大家自行查阅,我这里就抛砖引玉介绍本次用到的两个。
$:匹配输入字符串的结尾位置。要匹配 $ 字符本身,请使用 \$。
|:指明两项之间的一个选择。要匹配 |,请使用 \|。
基于上述两个字符,结合我们的目标:获取以docx或doc结尾的子串,那么可以通过这两种代码实现:
doc$|docx$
(doc|docx)$
我们已经简单了解了正则表达式,且已经成功用正则表达式获取了子串,那Python又是如何与正则表达式进行结合的呢?
这里我们就要引入一个新的模块:re。re是正则表达式的英文(regular expression)的首字母,在Python中若需要使用正则表达式,那就需要引入re。具体该需求的实现,见下图示例。
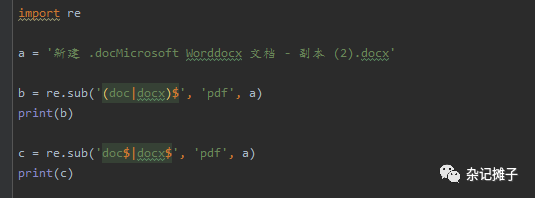
正则表达式示例

执行结果
附录
导入模块的方式:
import 模块名1 [as 别名1], 模块名2 [as 别名2],…
使用这种语法格式的 import 语句,会导入指定模块中的所有成员(包括变量、函数、类等)。不仅如此,当需要使用模块中的成员时,需用该模块名(或别名)作为前缀,否则 Python 解释器会报错。
from 模块名 import 成员名1 [as 别名1],成员名2 [as 别名2],…
使用这种语法格式的 import 语句,只会导入模块中指定的成员,而不是全部成员。同时,当程序中使用该成员时,无需附加任何前缀,直接使用成员名(或别名)即可。
导入包类似:
import 包名[.模块名 [as 别名]]
from 包名 import 模块名 [as 别名]
from 包名.模块名 import 成员名 [as 别名]















 1789
1789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









