





在人工智能的计算机视觉领域中,最常见的应用包括影像分类、对象侦测、像素级对象影像分割(语义分割及实例分割),其中以对象侦测的应用范围最广。
近年来对象侦测的算法(模型)不断推陈出新,从最早的二阶式(R-CNN、Fast R-CNN、Faster R-CNN)高精度算法演变到现在一阶式(YOLO、SSD、R-FCN)高效算法,在这之中以 YOLO(You Only Look Once)系列最受大家喜爱。
目前 YOLO 已演进至第三代(下简称 YOLO v3),其主要搭配 Microsoft COCO 对象侦测 80 分类做为预设训练数据集,如果只需侦测常见对象侦测(如人、动物、车辆等),那直接利用 YOLO 预训练好的模型及权重值就可应用到实际场域了,不过这 80 类对象通常很难满足我们的需求,因此如果想应用自己准备的数据集,如何收集(取像)、标注、训练数据集及进行最后的推论就显得非常重要,接下来就以辨识(侦测)小蕃茄为例为大家介绍完整的工作流程:
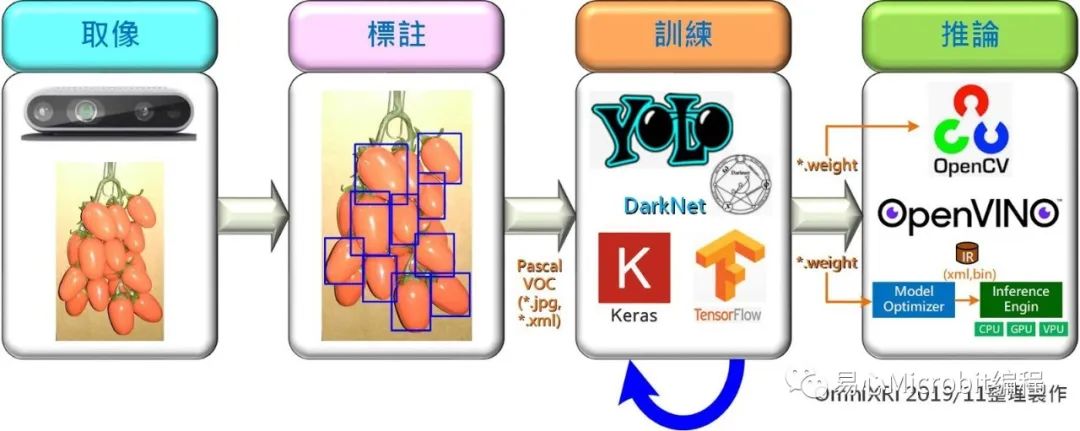
建立数据集
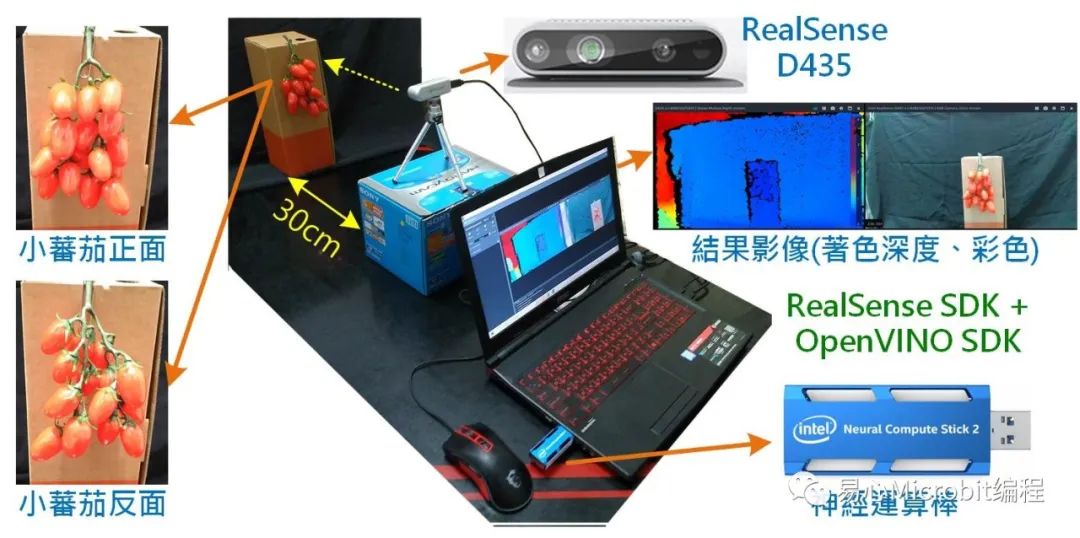
为了使后续训练的成果较理想,取像和训练影像条件要尽可能接近,因此这里直接使用 RealSense D435取像(彩色影像),而不采用其它高阶、高分辨率的摄影机,另外这么做还能顺便取得因摄影机本身受光照(白平衡、亮度、对比、色相等)及其它干扰产生的噪声(如热噪声、低照度噪声等)。
通常如果要作为深度学习的影像数据集,少说得取得几千张,甚至数十万张影像,但这里只是示范如何建构,因此仅对小蕃茄的正反面各取数十张影像当作测试,其取像及测试环境如下图所示,后续也可依需求自行增加影像的数量。
虽然训练影像不足时可以透过影像平移、旋转、缩放、亮度、对比、色彩调整等方式来扩增,但对象的纹理、视角、光照、形变等差异是不容易以数据扩增(Data Augmentation)的方式完成,因此在建立数据集时,数据的多样性部份要特别留意。
由于没有实际场域可以取像,所以只能反向操作,让摄影机不动,移动、旋转小蕃茄,以这种方式取得多种位置及视角的影像,其中也包含因移动产生的模糊影像。这里为了加快取像速度及与加大影像间的差异,设定摄影机以连续取像模式进行取像,每隔 1/3.3 秒(10 frames @ 30 FPS)取一张影像并存成 JPG 格式,另外也为减少后续训练数据集时间和因计算所需的内存空间,所以单张影像取像大小仅为 640×480 像素,而非 RealSense D435 的最大分辨率 1920×1080 像素,最后本范例共取得小蕃茄正面 92 张、反面 79 张,合计 171 张影像,完整的影像数据集请参考Github 下 VOC2007\JPEGImages。
https://github.com/OmniXRI/OpenVINO_RealSense_HarvestBot/tree/master/my_yolo3

标注数据集
有了自己的影像数据集后,接着要开始对其进行标注(Annatation),就是把每一张影像中的每一个小蕃茄的位置标上一个对象框,不过为了后续方便其它训练框架也能轻松读取标注数据,这里采用 VOC2007 的对象标注格式,而不直接采用 YOLO 自定义的格式。
首先新增一个名为 VOC2007 的文件夹,其下分别新增 Annotations 文件夹存放标注数据(*.xml)、ImageSets\Main 文件夹存放工作清单(*.txt)及 JPEGImages 文件夹存放原始影像(*.jpg),如下图:

有了影像后要如何标注呢?目前市面有许多免费开源工具可以使用,网络上也有许多教学范例。
标注时 LabelImg 默认路径会将产生的标注档(*.xml)放在原始图档(*.jpg)的路径下,每一张 jpg 图像文件标注完后会产出一张同名的 xml 档,可以等全部标注完后再一起搬到 \Annotations 下即可。标注时由于小蕃茄会有多层重迭问题,所以只标注靠外侧(层)较完整的和第二层有露出超过 1/2 以上的,完整的影像标注内容可参考本Github 下 VOC2007\Annotations。
https://github.com/OmniXRI/OpenVINO_RealSense_HarvestBot/tree/master/my_yolo3
接着要分配数据集大小,包括训练集(train.txt)、验证集(val.txt)、测试集(test.txt)及训练加验证集(trainval.txt)。若执行本部落格 Github 下 my_dataset.py,就会自动随机把影像数据集分成三个部份,其比例可自定,预设训练加验证集大约占全部数量的 2/3(trainval_percent = 0.66),而训练集占前述比例的一半(train_percent= 0.5),完成分配后,存放路径在 VOC2007\ImageSets\Main 下,而各数据集清单文件(*.txt)即为不含扩展名的影像名称列表。
训练数据集
一般要训练 YOLO v3 可选择使用原始的 DarkNet 方式或使用常见的 AI 框架,完整程序请参考本Github。
https://github.com/OmniXRI/OpenVINO_RealSense_HarvestBot/tree/master/my_yolo3
在程序执行前请先将 Keras 及相关依赖组件安装好,并另行下载 YOLO v3 预训练好的权重文件 yolov3.weights(约 243 MB)。
•数据集格式转换
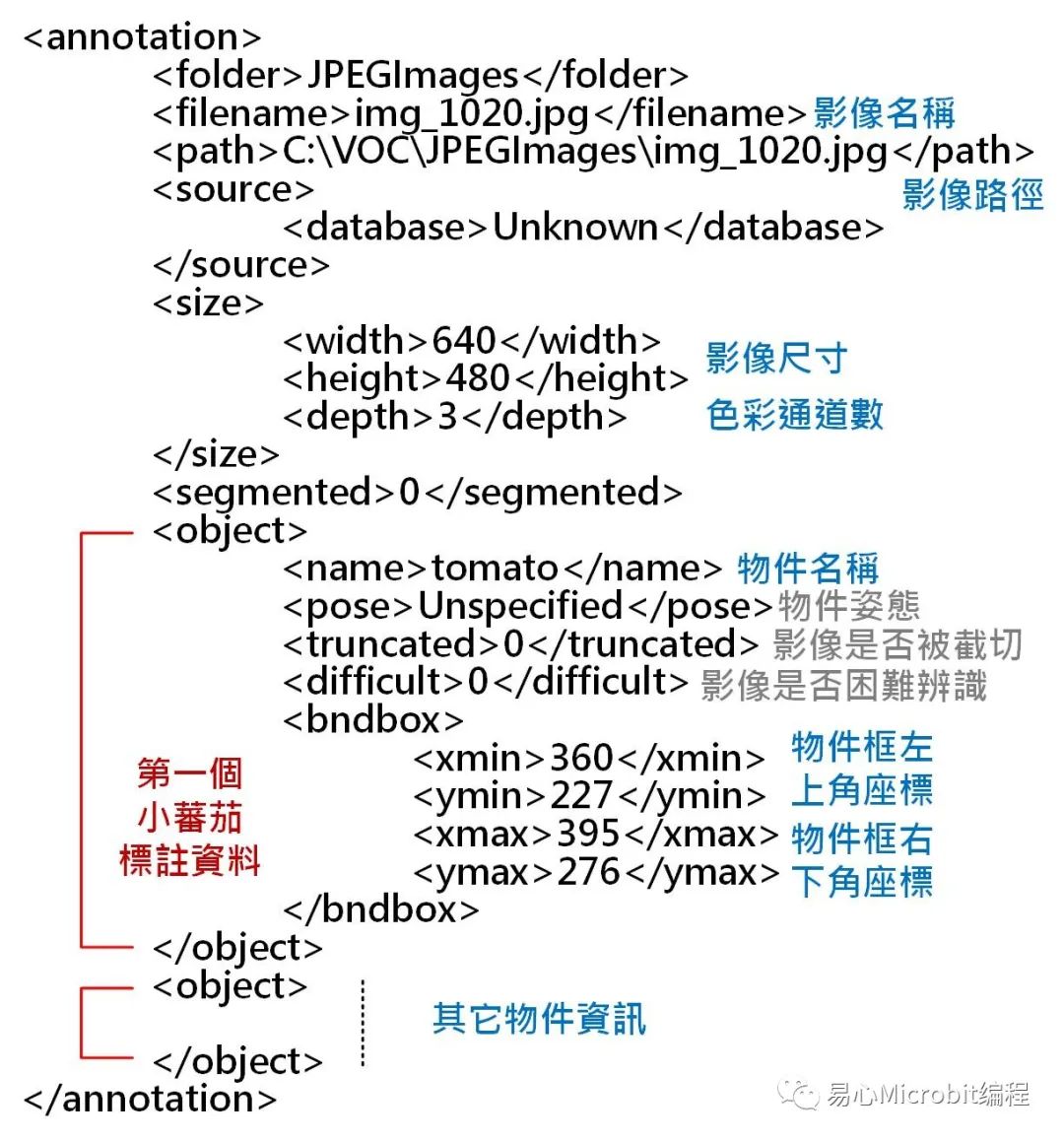
VOC2007 格式所产生标注档(*.xml)内容会如上图所示,主要表示对象框的方式为左上(xmin、ymin)及右下(xmax、ymax)坐标,和 YOLO 格式不同,所以要依数据集清单文件(*.txt),将个别标注档(*.xml)转换成对象编号加上对象框中心坐标及尺寸格式后再写至另一个清单文件。
这里只需执行执行本Github 下 my_voc_annotation.py 即可产生 2007_tarin.txt、2007_val.txt 及 2007_test.txt 三个 YOLO 格式的清单文件。
https://github.com/OmniXRI/OpenVINO_RealSense_HarvestBot/tree/master/my_yolo3
由于目前只有一个类别 tomato,所以 my_voc_annotation.py 中只需定义 classes = [“tomato”] 一个项目即可,另外 \model_data 下有一个 my_classes.txt 即是此次所需自义类别的标签文件,同样地只需定义 tomato 一个项目即可。
转换权重文件
由于此次使用的是 Keras 框架,所以须把下载到的 YOLO 预训练权重值转成 Keras 格式(*.h5),执行本Github 下 convert.py 即可转换完成并置于 \model_data 下,
https://github.com/OmniXRI/OpenVINO_RealSense_HarvestBot/tree/master/my_yolo3
其完整指令如下所示。
python convert.py -w yolov3.cfgyolov3.weights model_data/yolo_weights.h5
执行模型训练
接下来就可以执行本Github下 my_train.py 进行小蕃茄影像像训练,训练前要设定好下列参数(程序代码前二位数字为列号)。如果 GPU 内存不足导致训练到一半程序中止时,可把第 56 列批次数量设小一些;如果想先大概测一下(未完全收敛),可将第 62、82、83 列数值设小一点。最终训练完的结果会存放在 \logs\000\trained_weights_final.h5,若不满意结果想从这个结果继续训练,则可将此权重档复制到 \model_data 下,再将第 32 列程序修改成 weights_path=’model_data/ trained_weights_final.h5′ 即可。
另外如程序第 35、36列,在训练过程每隔几个遍历(Epoch)就会有检查点并会存权重结果临时档,万一不幸还没训练完成程序就意外终止时,可使用这些档案当成起始权重档使用,不过由于程序每次存盘是以第几次遍历加上损失率做为档名且不会自动删除,所以可能会占用巨量的磁盘空间,建议可改为存同一个名称,保留最后一次成果权重档即可;另外如果需要将 YOLO 模型及权重完整存盘以供其它程序或框架使用,则可把第 86 列改成 model.save() 即可。
16 annotation_path = '2007_train.txt' #待训练清单(YOLO 格式)
17 log_dir = 'logs/000/' #训练过程及结果暂存路径
18 classes_path ='model_data/my_classes.txt' #自定义卷标文件路径及名称
19 anchors_path ='model_data/yolo_anchors.txt' #锚点定义文件路径及名称
32 freeze_body=2,weights_path='model_data/yolo_weights.h5') #指定起始训练权重文件路径及名称
35 checkpoint = ModelCheckpoint(log_dir +'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
36 monitor='val_loss',save_weights_only=True, save_best_only=True, period=3) #训练过程权重档名称由第几轮加上损失率为名称
56 batch_size = 24 #批处理数量,依 GPU 大小决定
62 epochs=50, #训练遍历次数
63 initial_epoch=0, #初始训练遍历次数
82 epochs=100, #训练遍历次数
83 initial_epoch=50, #初始训练遍历次数
86 model.save_weights(log_dir +'trained_weights_final.h5') #储存最终权重档
影像推论
训练完成就可以来测试推论效果如何,执行本Github 下 my_yolo.py 即可,这里为求简单起见,直接于程序第 216 列指定待推论图像文件(如果想改成外部参数或变成对影片档连续推论可自行修改)。
216 path ='C:/Users/jack_/my_yolo3/VOC2007/JPEGImages/img_1550.jpg' #指定待测图像文件案路径及名称
下方是程序第 22~30 列,推论前除指定权重档、锚点定义文件、标签文件外,最重要的是指定置信度门坎和重迭区比例,而值要设多少就看实际侦测到多少个对象及外框尺寸精度来调整。
22 _defaults = {
23 "model_path":'model_data/trained_weights_final.h5', #指定 YOLO 训练完成权重文件路径及名称
24 "anchors_path":'model_data/yolo_anchors.txt', #指定锚点定义文件路径及名称
25 "classes_path":'model_data/my_classes.txt', #指定自定义卷标文件路径及名称
26 "score" : 0.1, #最低置信度门坎(0.01~0.99)
27 "iou" : 0.45, #重迭区比例(0.01~1.0)
28 "model_image_size" : (416,416), #影像尺寸
29 "gpu_num" : 1, #使用GPU数量
30 }



由于本文使用的影像数据集非常少,且训练的次数也不足一百次,所以小蕃茄被正确检出的比例并不高,所以将置信度调得很低,以方便呈现检出结果。另外一般测试时是绝对不能将训练集和验证集当作测试集,但本实验因为影像数据集太小及训练次数不多,所以就直接拿所有影像当成测试集以方便大家了解结果,不妥之处敬请见谅。完整的结果影像动画 GIF 文件可参考本Github 下\Result\tomato_ori.gif(原始图像文件)及tomato_yolo3.gif(推论结果档)。
另外这里补充两个小程序,yolov3_keras_to_darknet.py 方便大家将 Keras 训练好的 YOLO 模型转回 DarkNet 权重档(*.weights),而 h5topb.py则可将模型和权重转换到 TensoFlow(*.pb),有兴趣的朋友可以试一下。不过这里提醒一下,如果想在 Intel OpenVINO 下执行的朋友,请直接将权重档从 *.h5 格式转成 DarkNet *.weights 格式再送至 Model Optimizer 转换成 IR 格式(*.xml、*.bin),而不要转成 TensorFlow *.pb 格式再送到 MO 转 IR,以免无法顺利执行。
小结
YOLO v3 是非常普遍及高效的对象侦测深度学习模型,只要多花一点时间取得够多的影像集并进行仔细的标注及长时间的训练,相信像小蕃茄这类层迭迭的对象也能顺利检出,后续若再配上像 Intel RealSense D435 深度传感器的深度影像信息,自动采收小蕃茄的机器手臂很快就能土炮出来了。
====================
















 3736
3736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









