





- 论文原文:Incorporating Graph Attention Mechanism into Knowledge Graph Reasoning Based on Deep Reinforcement Learning
- 出版:EMNLP 2019
- 关键词:基于路径的知识图谱推理,深度强化学习,图注意力机制,LSTM,知识图谱补全
摘要
知识图谱(KG)推理旨在找到关系的推理路径,以解决 KG中的不完整性问题。许多以前的基于路径的方法(例如PRA和DeepPath)都缺少记忆组件,或者陷入了训练过程中。因此,它们的表现总是依赖于良好的训练。
在本文中,我们提出了一个基于 AttnPath 的基于深度强化学习的模型,该模型将 LSTM 和图注意力机制作为记忆组件。我们定义两个指标,平均选择率(MSR)和平均替换率(MRR),以定量地衡量学习查询关系的难度,并在强化学习的框架下利用它们来微调模型。同时,提出了一种新的强化学习机制,即通过强制智能体每走一步来避免智能体不断停滞在同一实体节点上。基于此操作,所提出的模型不仅可以摆脱预训练过程,而且与其他模型相比也能达到最新的性能。
我们在具有不同任务的 FB15K-237 和 NELL995 数据集上测试了我们的模型。大量的实验表明,我们的模型在许多当前最先进的方法中均有效且具有竞争力,并且在实践中也表现良好。
1 介绍
主要有三种方式执行知识图谱推理,基于规则、基于嵌入和基于路径的方法。同时,知识图谱推理提供了一种视角:将深度强化学习带入到预测缺失链接到任务中。
例如 DeepPath,一个基于路径的方法,它是第一个将深度强化学习集成到知识图谱推理任务中的工作。相比于 PRA,它仍然有一些缺陷: - 缺乏记忆组件,导致需要预训练。预训练要求提供许多已知的或存在的路径用于模型训练。这种暴力操作可能使模型在用于预训练的路径上过拟合。 - 训练过程中为知识图谱中不同的关系设置同样的超参数是不合理的,它忽略了实体之间连接的多样性。 - 当智能体选择无效的路径时,它将停止并重新选择,可能导致不断选择无效的路径并最终卡在一个结点上。
因此,在该文中,作者提出一种新的深度强化学习模型和一个算法,试图解决上述问题。该方法属于基于路径的框架中。该文的贡献主要是:
- 提出一种模型 AttnPath,集成 LSTM 和图注意力作为记忆组件,并不再需要预训练。
- 定义了两个度量标准(MSR和MRR),以定量地度量学习关系的可替换路径的难度。该度量用于微调模型。
- 提出了一种新的强化学习机制,通过强制智能体每走一步来避免智能体不断停滞在同一实体节点上。
3 AttnPath:集成记忆组件
3.1 知识图谱推理的强化学习框架
因为使用强化学习作为序列决策模型的训练算法,作者首先介绍知识图谱推理中的强化学习框架的基本元素。包括环境、状态、行为和奖励。
环境:在该任务中,环境指的是整个知识图谱,排除查询关系和逆关系。环境在整个训练过程中保持不变。 状态:智能体的状态由三部分拼接而成,嵌入部分、LSTM 部分、图注意力部分。 不同于 DeepPath 使用 TransE 作为知识图谱嵌入模型,AttnPath 使用 TransD 模型。状态的嵌入部分可描述为:

状态的 LSTM 部分和图注意力部分在后文描述。
行为:对于知识图谱推理任务,一个行为指的是一个智能体选择关系路径前进。基于深度强化学习的框架,它根据模型提供的概率选择关系。行为可能是有效的或无效的。有效的行为表示有输出关系是与当前实体相连的关系,而无效的关系表示该实体没有对应的关系。
奖励:奖励是根据行为是否有效、或者一系列行为是否能在有限步骤内导向正确的尾实体,而给予智能体的反馈。
对于无效的行为,奖励是 -1. 对于不引向真实实体的行为,作者选择 ConvE 的输出作为奖励。因为 ConvE 输出概率,在 (0, 1) 之间,作者使用对数操作将奖励的扩大并提升可辨别性。
对于引向真实实体的行为,即成功的事件,奖励是全局准确性、路径高效性、路径多样性的加权和。按照惯例,将全局准确性设置为 1,并且路径效率是路径长度的倒数,因为我们鼓励智能体尽可能少地走步。路径多样性定义为:
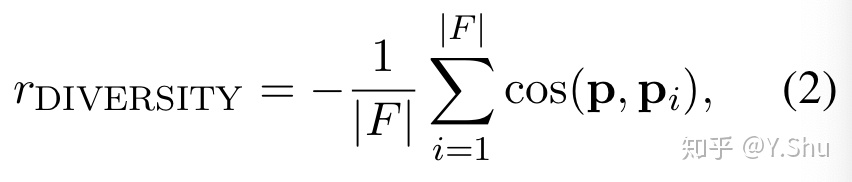
其中 |F| 是找到的路径的数量,p 是路径的嵌入,简单地定义为路径中所有关系嵌入的和。
上面的定义保证了有效动作的奖励总是大于无效动作的奖励,而成功的事件的奖励总是大于不成功的事件的奖励。
3.2 LSTM 和图注意力作为记忆组件
在模型中,作者使用三层 LSTM,使智能体能记忆并从记忆中学习之前执行过的行为。将第 t 步的隐藏状态是记为 h_t,初始隐藏状态为 h0,我们可得:
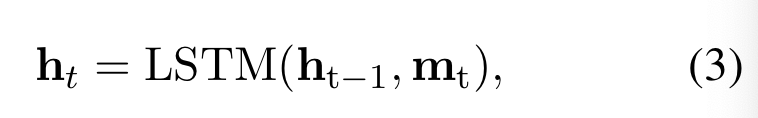
这就是状态的 LSTM 部分。
通常而言,一个实体有多个方面,例如表示一个人的实体可能有职业和家庭成员两种角色。对于不同的查询关系,较好的方式是让智能体关注于与查询关系更加相关的关系与邻居。
因此,作者引入了图注意力机制。GAT 是在实体结点的自注意力。图注意力机制部分的描述如下:


智能体选择一个动作并获得奖励。在成功到达尾部实体或未达到指定的次数后,整个事件的奖励将用于更新所有参数。使用 REINFORCE 算法完成优化,并使用以下随机梯度更新θ:
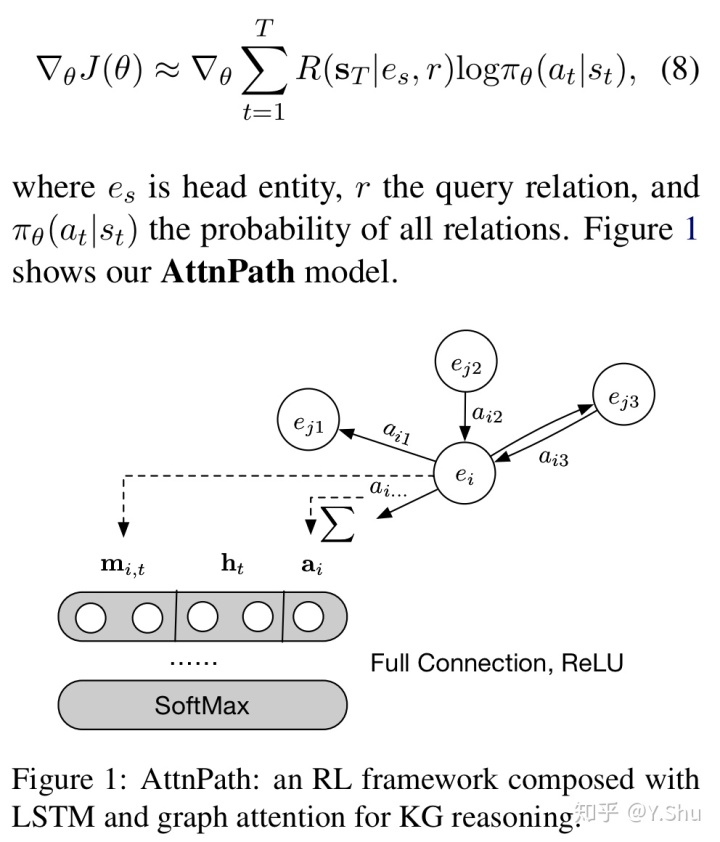
上面图 1 展示了强化学习框架,相比于 DeepPath 的关键创新是集成了 LSTM 和图注意力机制。读到这里,请再读一遍该论文原文的标题。
3.3 平均选择/替换率
对于不同的查询关系,需要为每个查询模型训练不同的模型。实际上,每种关系的难度值都完全不同。某些关系可能具有更多的替换关系,这表明智能体可以轻松选择从头部实体到尾部的替换路径。因此,我们在这里发明了两个指标,均值选择率(MSR)和均值替换率(MRR),以定量地衡量每个关系的难度值。

较低的 MSR 表示更难学习给定的关系,因为与该关系相连的实体可能有更多的语义层面。

较高的 MRR 表示关系可能有更多的替代关系,所以它更容易学习因为智能体可以直接选择替代关系来到达终点。
该模型中使用了三种方法来防止过拟合:L2 正则化、dropout、行为 dropout。但是,对于易于学习的关系(较高的MSR和MRR),我们希望施加更多的正规化以鼓励智能体找到更多不同的路径,而又不会过分适应即时的成功。另外,对于较难学习的关系(MSR和MRR较低),我们最好将重点放在寻找路径的成功率上,因此应减少正则化。
为简单起见,我们使用指数计算关系r的难度系数。它定义为 exp(MSR(r) + MRR(r)),并分别乘以三种正则化方法的基本速率。正则化方法的基本速率基于 KG,在同一 KG 中的所有关系之间共享。
3.4 整体训练算法
基于提出的模型,我们提出了一种新的训练算法,如算法 1 所示。
作者对算法的贡献之一是,当智能体选择无效路径时,模型不仅会对其进行惩罚,还会强制其选择有效关系以向前迈进。来自神经网络的概率在所有有效关系中均被归一化,这反过来又影响了强制行为的概率。
初始化之后,第6行根据网络的输出对动作进行采样。当智能体选择无效动作时,将执行第7到10行,而第9到10行则迫使智能体向前移动。当智能体选择有效动作时,将执行第12行。第19、22和25行使用奖励-1,Rtotal和Rshaping分别更新无效动作,成功事件中的有效动作和不成功事件中的有效动作的参数。

4 实验
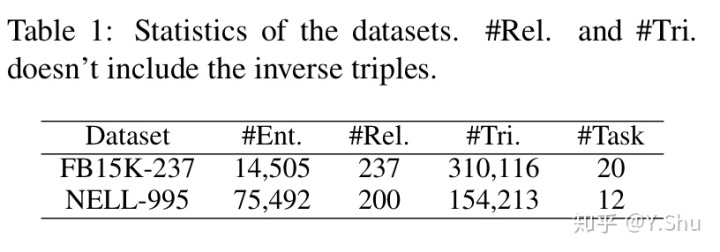
作者使用关系预测和链接预测两个任务对该模型做实验,并比较了和 DeepPath 的表现差距。

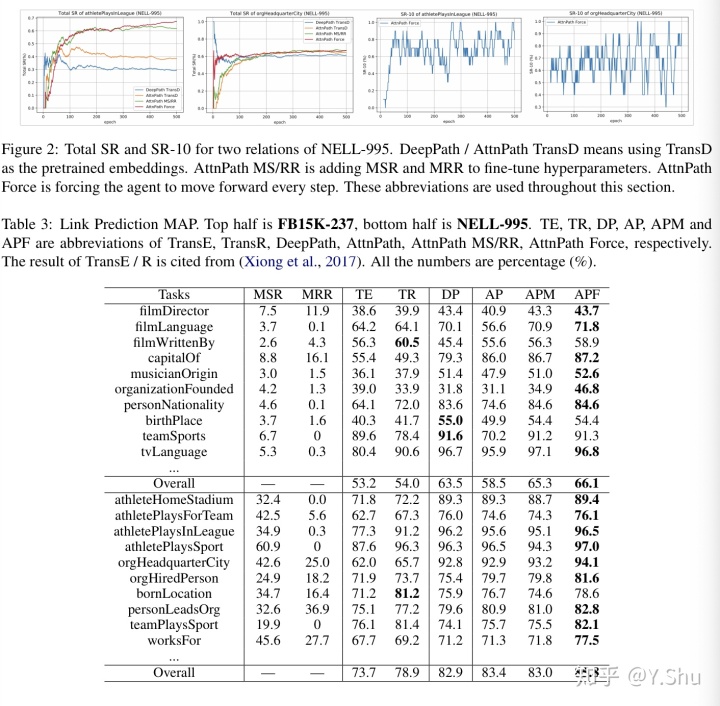
5 结论与未来工作
在本文中,作者提出了 AttnPath,这是一种基于 DRL 的 KG 推理任务模型,该模型将 LSTM 和图注意力机制作为记忆组件,以减轻模型的预训练。
作者还发明了两个指标 MSR 和 MRR 来衡量关系的学习难度,并将其用于更好地微调训练超参数。
作者改进了训练过程,以防止智能体陷入毫无意义的状态。
定性实验和定量分析表明,作者的方法明显优于DeepPath和基于嵌入的方法,证明了其有效性。
在未来,作者有兴趣于使用多任务学习,使模型能同时学习多个查询关系。作者也感兴趣于研究如何使用 GAT、MSR 和 MRR 于其他 KG 相关的任务,例如 KG 的表示、关系聚类和 KBQA。














 3943
3943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









