





最初于2019年6月24日发布在https://hackersandslackers.com。
在PySpark DataFrame上执行类似SQL的联接和聚合。

我们一起经历了一段探索PySpark神奇世界的旅程。 在介绍了DataFrame转换,结构化流和RDD之后,在我们进行深入研究之前,剩下的事情还不多。
为了总结本系列的内容,我们将回顾一下我们错过的一些强大的DataFrame操作。 特别是,我们将专注于整体修改DataFrame的操作,例如Join和Aggregation。 让我们从Joins开始,然后我们可以访问Aggregation并以一些可视化的想法结束。
在PySpark中加入DataFrames
我假设您已经熟悉类似SQL的联接的概念。 为了在PySpark中进行演示,我将创建两个简单的DataFrame:
· 客户数据框(指定为数据框1);
· 订单DataFrame(指定为DataFrame 2)。
我们创建两个DataFrame的代码如下
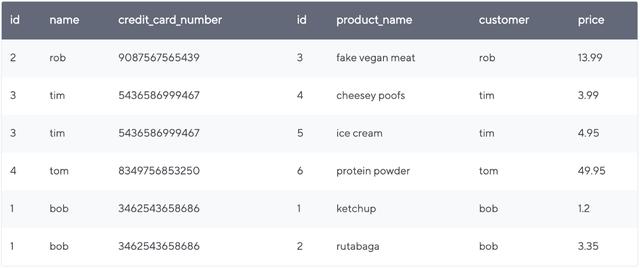
# DataFrame 1valuesA = [(1, 'bob', 3462543658686), (2, 'rob', 9087567565439), (3, 'tim', 5436586999467), (4, 'tom', 8349756853250)]customersDF = spark.createDataFrame(valuesA,['id', 'name', 'credit_card_number']) # DataFrame 2valuesB = [(1, 'ketchup', 'bob', 1.20), (2, 'rutabaga', 'bob', 3.35), (3, 'fake vegan meat', 'rob', 13.99), (4, 'cheesey poofs', 'tim', 3.99), (5, 'ice cream', 'tim', 4.95), (6, 'protein powder', 'tom', 49.95)]ordersDF = spark.createDataFrame(valuesB,['id', 'product_name', 'customer', 'price']) # Show tablescustomersDF.show()ordersDF.show()它们的外观如下:

> The DataFrames we just created.
现在,我们有两个简单的数据表可以使用。
在联接这两个表之前,必须意识到Spark中的表联接是相对"昂贵"的操作,也就是说,它们使用了大量的时间和系统资源。
内部联接
在没有指定我们要执行的联接类型的情况下,PySpark将默认为内部联接。 通过调用DataFrame上的join()方法可以进行联接:
joinedDF = customersDF.join(ordersDF, customersDF.name == ordersDF.customer)
join()方法在现有的DataFrame上运行,我们将其他DataFrame联接到现有的DataFrame上。 join()方法中的第一个参数是要添加或连接的DataFrame。
接下来,我们指定联接的" on"。 在我们的示例中,我们告诉我们的联接将customersDF的"名称"列与ordersDF的"客户"列进行比较。 结果是这样的:
右,左和外连接
我们可以将关键字参数" how"传递到join()中,该参数指定我们要执行的联接的类型。 如您所想,how参数如何接受内部,外部,左侧和右侧。 我们还可以通过how参数传递一些冗余类型,如leftOuter(与left相同)。
交叉联接
我们可以执行的最后一种连接类型是交叉连接,也称为笛卡尔连接。 交叉联接与其他类型的联接有些不同,因此交叉联接具有自己的DataFrame方法:
joinedDF = customersDF.crossJoin(ordersDF)
交叉联接在DataFrame#2中的每个记录在DataFrame#1中创建一个新行:

> Anatomy of a cross join.
通过我们的简单示例,您可以看到PySpark支持与传统持久数据库系统(例如Oracle,IBM DB2,Postgres和MySQL)相同类型的联接操作。 PySpark使用内存中方法创建弹性分布式数据帧(RDD)。 正如我们提到的那样,在集群中执行这些类型的联接操作将既昂贵又耗时。 接下来,我们将讨论汇总数据,这是Spark的核心优势。
汇总数据
Spark允许我们对数据执行强大的聚合功能,类似于您可能已经在SQL或Pandas中使用的功能。 我要汇总的数据是纽约市机动车碰撞的数据集,因为我是一个悲伤而扭曲的人!
我们将在这里熟悉两个函数:agg()和groupBy()。 这些通常串联使用,但是agg()可以用于没有groupBy()的数据集:
df.agg({"*": "count"}).show()
不执行groupBy()进行聚合通常并不完全有用:
+--------+
|count(1) |
+--------+
| 1000 |
+--------+
通过将agg()与groupby()结合起来,让我们从数据中获得更深层的含义。
使用groupBy()
让我们看看哪个自治市镇在事故数量上处于领先地位:
import pyspark.sql.functions as fdf.groupby('borough').agg(f.count('borough').alias('count')).show()
结果:
+-------------+-----+
| borough |count |
+-------------+-----+
| QUEENS | 241 |
| BROOKLYN | 182 |
| BRONX | 261 |
| MANHATTAN | 272 |
|STATEN ISLAND | 44 |
+-------------+-----+
曼哈顿以我们的样本中的272起事故为首! 聚在一起,曼哈顿。 让我们看看哪个区是最致命的区:
df.groupby('borough').agg(f.sum('number_of_persons_injured').alias('injuries')).orderBy('injuries', ascending=False).show()
开始了:
+-------------+--------+
| borough |injuries|
+-------------+--------+
| MANHATTAN | 62 |
| QUEENS | 59 |
| BRONX | 57 |
| BROOKLYN | 47 |
|STATEN ISLAND| 14 |
+-------------+--------+
好吧…那好。 让我们避开曼哈顿!
按多列分组
通常,我们会希望按多列进行分组,以查看更复杂的细分。 在这里,我们按自治市镇和"主要贡献因素"进行分组:
aggDF = df.groupby('borough', 'contributing_factor_vehicle_1').agg(f.sum('number_of_persons_injured').alias('injuries')).orderBy('borough', 'injuries', ascending=False)aggDF = aggDF.filter(aggDF.injuries > 1)display(aggDF)这将向我们展示每个行政区最常见的事故类型:
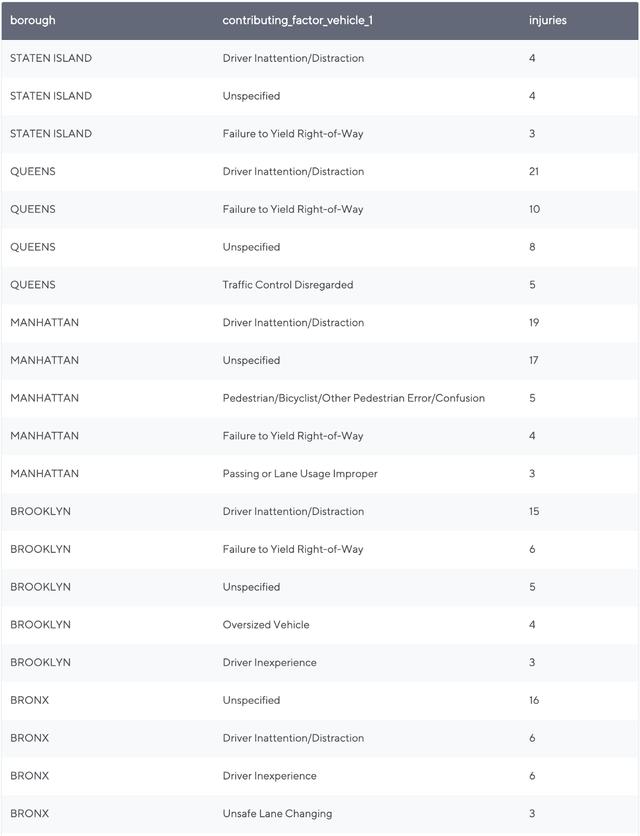
> Drivers in Manhattan need to pay attention! Get off your phones!!
到目前为止,我们已经使用count和sum函数进行了汇总。 如您所料,我们还可以使用min,max和avg函数进行聚合。 还有一个特别值得一提的功能,叫做corr()。 corr函数可帮助我们确定列之间的相关强度。
确定列相关
如果您是数据科学类型,那么您会喜欢使用corr()进行聚合。 corr()确定两列的相关强度,并输出代表该相关的整数:
df.agg(corr("a", "b").alias('correlation')).collect()输出示例:
[Row(correlation=1.0)]
使用PySpark的Aggregation功能,您会发现您可以进入功能强大的聚合管道并真正回答复杂的问题。 这些问题的答案必须以令人愉悦且易于理解的视觉形式呈现。 让我们考虑这些聚合的可视化。
聚合的数据块可视化
如果您正在使用Databricks笔记本电脑,那么display()命令会标配大量出色的可视化效果,以补充我们执行的所有汇总。 当试图了解我们创建的聚合的分布时,这些功能特别有用。
我继续前进,整理了以下事故中受伤人员的细目分类。 我们将结果划分为Borough,然后查看骑自行车的人和驾车者之间受伤人数的分布:
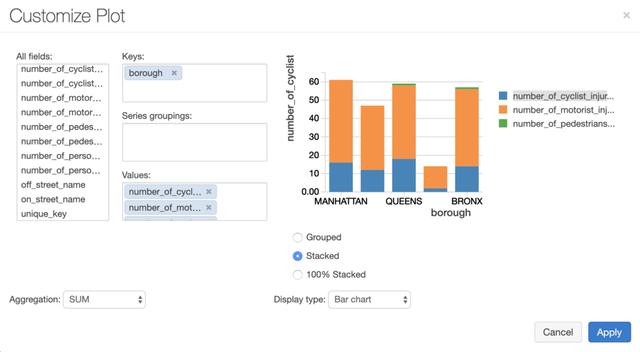
> Creating a visualization in Databricks.
在创建条形图时,"键"确定x轴上的值。 我在这里通过多个"值"进行测量,也就是说,将显示沿y轴的多次测量。
此特定的图表非常适合堆积条形图,我们通过将条形图指定为显示类型,然后在其他选项中指定堆积来创建堆积条形图。 Databrick允许各种附加的酷视觉效果,例如地理图表,散点图等等。 似乎在曼哈顿散步要安全得多!
快乐足迹
我们在一起进行PySpark之旅中经历了很多事情。 我很乐意将您永远留在这里,每个好父母都知道什么时候该让他们的孩子离开巢穴并独自飞翔。 我会给你一些父母给我的建议:去找份工作,离开我该死的房子。
(本文翻译自Todd Birchard的文章《PySpark Macro DataFrame Methods: join() and groupBy()》,参考:https://hackingandslacking.com/pyspark-macro-dataframe-methods-join-and-groupby-477a57836ff)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









