用法
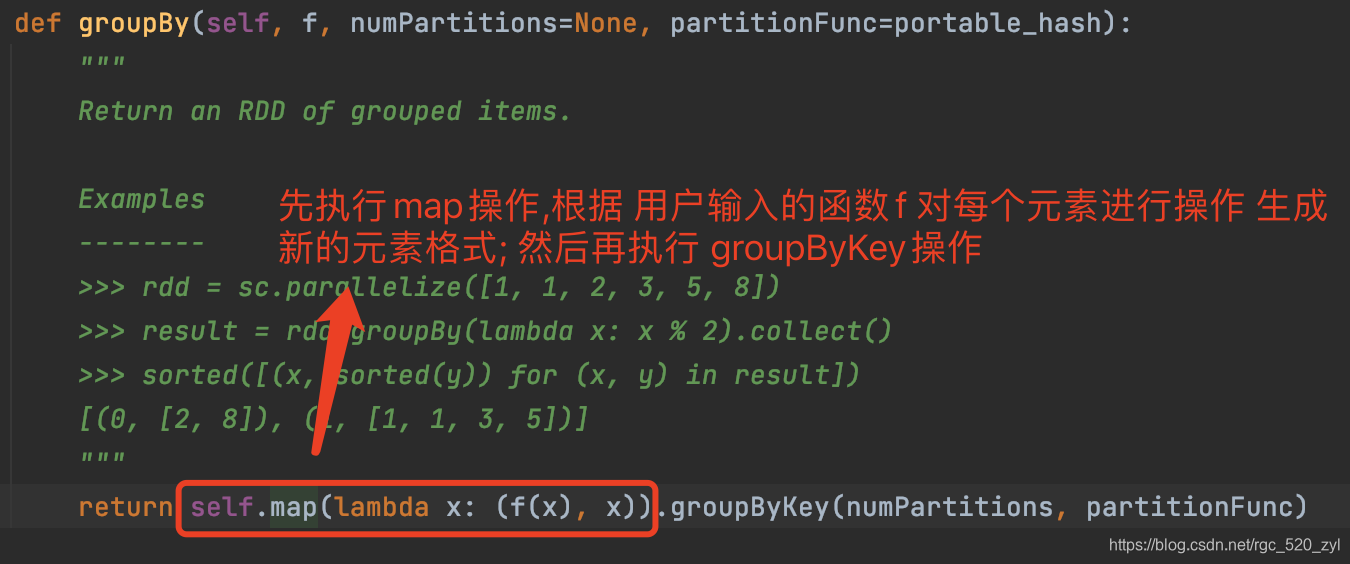
- groupBy: 每个元素根据用户指定的函数运行结果作为key,然后进行分组;
如果需要 自定义分组的key可以使用此方法;
- groupByKey:rdd每个元素根据第一个值作为key进行分组
用法示例
"""
(C) rgc
All rights reserved
create time '2021/5/30 21:01'
Usage:
"""
from pyspark.conf import SparkConf
from pyspark.context import SparkContext
conf = SparkConf()
conf.setMaster('local[1]').setAppName('rgc')
sc = SparkContext(conf=conf)
rdd = sc.parallelize([(2, 3), (1, 4), (2, 4), (1, 5), (3, 3)], 2)
def func(x):
"""
:param x:
:return:
"""
return x[1]
rdd_res = rdd.groupBy(func).cache()
print(rdd_res.mapValues(list).collect())
def func1(x):
"""
对list进行转换
:param x:
:return:
"""
_list = []
for item in list(x):
_list.append(item[0])
return _list
print(rdd_res.mapValues(func1).collect())
rdd_res = rdd.groupByKey()
print(rdd_res.mapValues(list).collect())
总结
- groupBy其实内部调用的groupByKey方法;
- 这2个方法只对RDD进行分组,返回的是 迭代对象,且不对分组结果进行进一步处理;一般后续接的是 mapValues方法,将迭代对象转为一般数据结构;

























 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









