





- 一直对fasterRCNN感觉不够理解,现结合之前看过的版本,写一个基于keras架构的fasterRCNN整体理解。水平有限,希望和大家多多交流
- 原文链接:http://www.ee.bgu.ac.il/~rrtammy/DNN/reading/FastSun.pdf
- github托管代码可以在github上自行搜索,之前的keras版本貌似已经失效
- 本文是我在学习目标检测时记录的笔记,中间可能会引用部分博客的文档,我会尽力注明引用,如有侵权,请私信告知。
1. 目标检测
目标检测:对给定图片的定位和标注。即目标在哪里和是什么的过程。受限于物体尺寸编号、角度姿态及物体类别多样性,目标检测困难重重。
传统目标检测流程:
- 区域选择(穷举策略:采用滑动窗口,且设置不同的大小,不同的长宽比对图像进行遍历,时间复杂度高)
- 特征提取(SIFT、HOG等;形态多样性、光照变化多样性、背景多样性使得特征鲁棒性差
- 分类器分类(主要有SVM、Adaboost等)
目前学术和工业级目标检测算法可分为传统目标检测算法和基于机器学习的检测算法:
- 传统目标检测算法:Cascade + HOG/DPM + Haar/SVM及其迭代升级版
- 基于深度学习检测算法:
- 基于深度学习的回归方法:YOLO/SSD/DenseBox 等方法

-
- 候选区域 + 深度学习分类
- R-CNN(Selective Search + CNN + SVM)
- SPP-net(ROI Pooling)
- Fast R-CNN(Selective Search + CNN + ROI)
- Faster R-CNN(RPN + CNN + ROI)
- R-FCN
- 候选区域 + 深度学习分类
2. RCNN、fastRCNN和fasterRCNN对比

2.1 RCNN
- 利用selective search 算法在图像中提取2000个左右的Region Proposal;
- 将每个Region Proposal缩放(warp)成227*227的大小并输入到CNN,将CNN的fc7层的输出作为特征并输入到SVM进行分类;
- 对于SVM分好类的Region Proposal做边框回归,用Bounding box回归值校正原来的建议窗口,生成预测窗口坐标.
缺陷:
- 训练耗时,占用磁盘空间大;
- 速度、测试速度慢测试速度慢:每个候选区域需要运行整个前向CNN计算;
- SVM和回归是事后操作,在SVM和回归过程中CNN特征没有被学习更新.
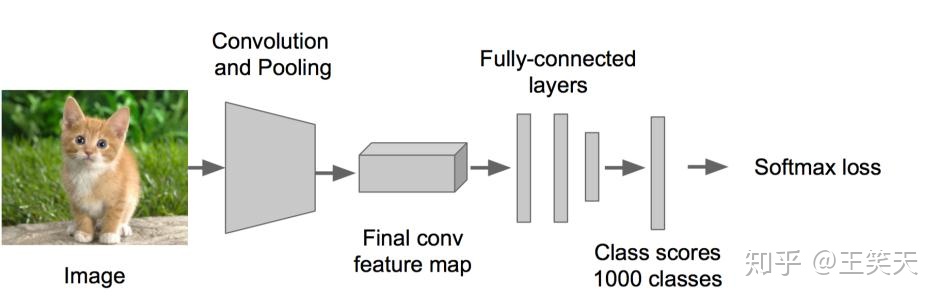
2.2 fastRCNN
- 利用selective search 算法在图像中从上到下提取2000个左右的建议窗口(Region Proposal);
- 将整张图片输入CNN,进行特征提取 ;
- 把建议窗口映射到CNN的最后一层卷积feature map上;
- 通过RoI pooling层使每个建议窗口生成固定尺寸的feature map;
- 利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
3. Faster RCNN整体流程图
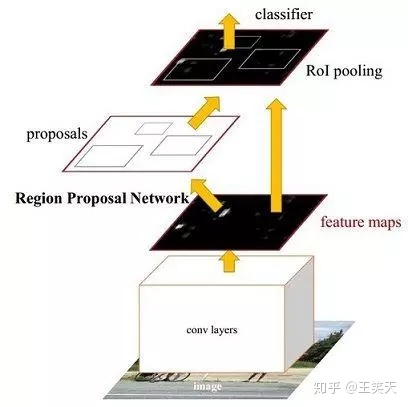
由以上流程图,可以看到,fasterRCNN分为两个阶段:
- 使用RPN网络获取候选区域(region proposal或ROI)
- 对候选区域分类判断并回归修正。
具体来说,可以分为以下几部分















 5963
5963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









