







VGG16 keras框架 猫狗识别【使用预训练的卷积神经网络】
一.前言
想要将深度学习应用在小型数据集,一种高效的方法是使用预训练的网络。
预训练的网络是之前保存好的网络,之前大型数据集(通常是大规模图像分类任务)上训练好。如果这个原始数据集足够大且足够通用,那么预训练的网络学到的特征的空间层次结构,可以有效的作为视觉世界的通用模型,因此这些模型可以用于各种不同的计算机视觉问题。
使用预训练网络有两种方法:特征提取和微调模型。
二.特征提取
特征提取是使用之前网络学习到的表示来从新样本中提取出有趣的特征。然后将这些特征进入一个新的分类器,从头开始训练。
用于图像分类的卷积神经网络包含两部分,首先是一系列的池化层和卷积层,最后是一个密集连接分类器。
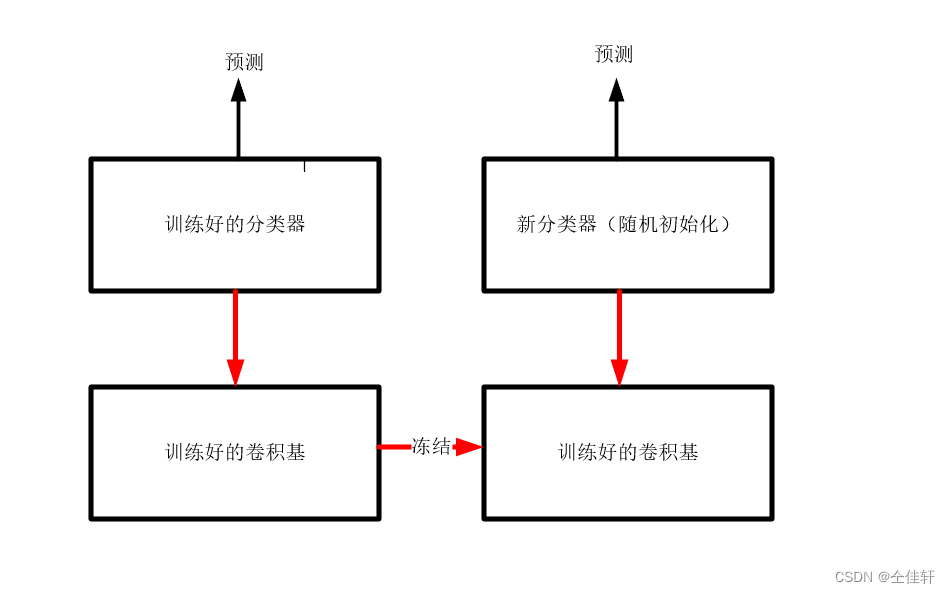
为什么要用仅仅使用卷积基呢?我们能否也重复使用密集连接分类器?一般来说,应该避免这么做。原因在于卷积基学到的表示可能更加通用。卷积神经网络的特征图表示通用概念在图像中是否存在,无论面对什么样的计算机视觉问题,这种特征图都可能是有用的。但是,分类器学到的表示必然是针对模型训练的类别,其中仅包含某个类别出现在某张图像中的概率信息。
VGG16等模型内置于Keras中。可以通过模块导入的方式进行导入。下面是Keras.applications中的一部分图像分类模型(都是在ImageNet数据集中训练得到的)
- Xception
- Inception V3
- ResNet50
- VGG16
- VGG19
- MobileNet
本篇博客将教你迁移已经训练好的VGG16模型。
三.实现步骤
3.1 将VGG16实例化
from keras.applications import VGG16
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape= (150,150,3))
这里向构造函数中传递入三个参数。
- weights 指定模型初始化的权重检查点。
- include_top 指定模型最后是否包括密集连接分类器。默认情况下,这个密集连接分类器应该对应于ImageNet的1000个类别。因为我们打算使用自己的密集连接分类器(只有两个类别:cat和dog),所以不需要包含它。
- input_shape 是指输入到网络的图像张量的形状。这个参数是可选的。如果不选择,那么网络可以处理任意形状的输入。
最后输出的特征图的形状为(4,4,512)。
下一步有两种方法可供选择。
- 在你的数据集上运行卷积基,将输出保存为硬盘中的Numpy数组,然后将这个数据作为输入,输入到独立的密集连接分类器中。
- 在顶部添加Dense层来扩展已有模型(即conv_base),并在输入数据上端到端的运行整个模型。这样你可以使用数据增强,因为每个输入图像进入模型时都会经过卷积基。但是出于同样的原因,这种方法计算代价很高。
3.2 使用预训练的卷积基提取特征
from keras.applications import VGG16
import os
import numpy as np
from keras import models
from keras import layers
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
base_dir ='D:/严少青毕设/CNN-BiLSTM/cnn-bilstm/base_data'
train_dir = os.path.join(base_dir,'train')
validation_dir = os.path.join(base_dir,'validation')
test_dir = os.path.join(base_dir,'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape= (150,150,3))
def extract_freatures(directory, sample_count):
features = np.zeros(shape = (sample_count, 4 , 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(directory,
target_size=(150,150),
batch_size=batch_size,
class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i*batch_size: (i+1)*batch_size] =features_batch
labels[i*batch_size:(i+1)*batch_size] =labels_batch
i +=1
if i*batch_size >= sample_count:
break
return features,labels
if __name__ == '__main__':
train_features,train_labels =extract_freatures(train_dir,2000)
validation_features, validation_labels = extract_freatures(validation_dir,1000)
test_features, test_labels = extract_freatures(test_dir,1000)
train_features = np.reshape(train_features,(2000,4*4*512))
validation_features = np.reshape(validation_features, (1000, 4 * 4 * 512))
test_features = np.reshape(test_features, (1000, 4 * 4 * 512))
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4*4*512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(learning_rate=2e-5),
loss='binary_crossentropy',
metrics='accuracy')
history = model.fit(train_features,train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features,validation_labels))
Found 2000 images belonging to 2 classes.
1/1 [==============================] - 1s 1s/step
Found 1000 images belonging to 2 classes.
1/1 [==============================] - 1s 1s/step
Found 1000 images belonging to 2 classes.
1/1 [==============================] - 1s 1s/step
Epoch 1/30
100/100 [==============================] - 2s 19ms/step - loss: 0.6917 - accuracy: 0.9960 - val_loss: 0.6876 - val_accuracy: 0.9920
Epoch 2/30
100/100 [==============================] - 2s 17ms/step - loss: 0.6861 - accuracy: 0.9950 - val_loss: 0.6812 - val_accuracy: 0.9910
Epoch 3/30
100/100 [==============================] - 2s 18ms/step - loss: 0.6772 - accuracy: 0.9970 - val_loss: 0.6754 - val_accuracy: 0.9900
Epoch 4/30
100/100 [==============================] - 2s 18ms/step - loss: 0.6686 - accuracy: 0.9980 - val_loss: 0.6687 - val_accuracy: 0.9910
可以看见训练和验证精度都非常高。

















 4185
4185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











